
Our research advances the fundamental mechanisms of learning, adaptation, and control that drive autonomous behaviour. We develop robotic systems capable of learning from human instruction, engaging in embodied dialogue, and collaborating seamlessly with human partners. As these systems become more capable, we remain committed to responsible development — embedding safety, trust, and transparency.
We combine fundamental research in AI and cognitive science with the engineering of complete, deployable systems that address real-world challenges in healthcare and mobility. This includes long-standing research interests in:
- Generative modelling of human behaviour
- Interactive compositional learning and machine teaching
- Cognitive-aware assessment and training
- Human-robot collaboration
- Safe and trustworthy shared autonomy frameworks
Together, these capabilities enable the creation of intelligent systems that are not only autonomous, but also genuinely interactive, interpretable, and aligned with human needs.

Featured Publications


Publications
2025
Heuristic Adaptation of Potentially Misspecified Domain Support for Likelihood-Free Inference in Stochastic Dynamical Systems Working paper
Georgios Kamaras, Craig Innes, Subramanian Ramamoorthy
2025.
@workingpaper{Kamaras2025,
title = {Heuristic Adaptation of Potentially Misspecified Domain Support for Likelihood-Free Inference in Stochastic Dynamical Systems},
author = {Georgios Kamaras and Craig Innes and Subramanian Ramamoorthy },
url = {https://arxiv.org/abs/2510.26656},
year = {2025},
date = {2025-10-30},
abstract = {In robotics, likelihood-free inference (LFI) can provide the domain distribution that adapts a learnt agent in a parametric set of deployment conditions. LFI assumes an arbitrary support for sampling, which remains constant as the initial generic prior is iteratively refined to more descriptive posteriors. However, a potentially misspecified support can lead to suboptimal, yet falsely certain, posteriors. To address this issue, we propose three heuristic LFI variants: EDGE, MODE, and CENTRE. Each interprets the posterior mode shift over inference steps in its own way and, when integrated into an LFI step, adapts the support alongside posterior inference. We first expose the support misspecification issue and evaluate our heuristics using stochastic dynamical benchmarks. We then evaluate the impact of heuristic support adaptation on parameter inference and policy learning for a dynamic deformable linear object (DLO) manipulation task. Inference results in a finer length and stiffness classification for a parametric set of DLOs. When the resulting posteriors are used as domain distributions for sim-based policy learning, they lead to more robust object-centric agent performance.
},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Conversational Code Generation: a Case Study of Designing a Dialogue System for Generating Driving Scenarios for Testing Autonomous Vehicles Proceedings Article
Rimvydas Rubavicius, Antonio Valerio Miceli-Barone, Alex Lascarides, Subramanian Ramamoorthy
In: Proceedings of the Generative Code Intelligence Workshop (GeCoIn 2025) co-located with 28th European Conference on Artificial Intelligence (ECAI 2025) , CEUR Workshop Proceedings, 2025.
@inproceedings{rubavicius2025conversationalcodegenerationcase,
title = {Conversational Code Generation: a Case Study of Designing a Dialogue System for Generating Driving Scenarios for Testing Autonomous Vehicles},
author = {Rimvydas Rubavicius and Antonio Valerio Miceli-Barone and Alex Lascarides and Subramanian Ramamoorthy},
url = {https://ceur-ws.org/Vol-4075/paper7.pdf
https://arxiv.org/abs/2410.09829},
year = {2025},
date = {2025-10-26},
urldate = {2025-09-03},
booktitle = {Proceedings of the Generative Code Intelligence Workshop (GeCoIn 2025) co-located with 28th European Conference on Artificial Intelligence (ECAI 2025)
},
volume = {4075},
publisher = {CEUR Workshop Proceedings},
abstract = {Cyber-physical systems like autonomous vehicles are tested in simulation before deployment, using domain-specific programs for scenario specification. To aid the testing of autonomous vehicles in simulation, we design a natural language interface, using an instruction-following large language model, to assist a non-coding domain expert in synthesising the desired scenarios and vehicle behaviours. We show that using it to convert utterances to the symbolic program is feasible, despite the very small training dataset. Human experiments show that dialogue is critical to successful simulation generation, leading to a 4.5 times higher success rate than a generation without engaging in extended conversation.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
ROOM: A Physics-Based Continuum Robot Simulator for Photorealistic Medical Datasets Generation Working paper
Salvatore Esposito, Matías Mattamala, Daniel Rebain, Francis Xiatian Zhang, Kevin Dhaliwal, Mohsen Khadem, Subramanian Ramamoorthy
2025.
@workingpaper{Espositoetal2025,
title = {ROOM: A Physics-Based Continuum Robot Simulator for Photorealistic Medical Datasets Generation},
author = {Salvatore Esposito and Matías Mattamala and Daniel Rebain and Francis Xiatian Zhang and Kevin Dhaliwal and Mohsen Khadem and Subramanian Ramamoorthy },
url = {https://arxiv.org/abs/2509.13177
https://github.com/iamsalvatore/room},
year = {2025},
date = {2025-09-17},
abstract = {Continuum robots are advancing bronchoscopy procedures by accessing complex lung airways and enabling targeted interventions. However, their development is limited by the lack of realistic training and test environments: Real data is difficult to collect due to ethical constraints and patient safety concerns, and developing autonomy algorithms requires realistic imaging and physical feedback. We present ROOM (Realistic Optical Observation in Medicine), a comprehensive simulation framework designed for generating photorealistic bronchoscopy training data. By leveraging patient CT scans, our pipeline renders multi-modal sensor data including RGB images with realistic noise and light specularities, metric depth maps, surface normals, optical flow and point clouds at medically relevant scales. We validate the data generated by ROOM in two canonical tasks for medical robotics -- multi-view pose estimation and monocular depth estimation, demonstrating diverse challenges that state-of-the-art methods must overcome to transfer to these medical settings. Furthermore, we show that the data produced by ROOM can be used to fine-tune existing depth estimation models to overcome these challenges, also enabling other downstream applications such as navigation. We expect that ROOM will enable large-scale data generation across diverse patient anatomies and procedural scenarios that are challenging to capture in clinical settings.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
The ACPGBI AI taskforce report: A mixed-methods roadmap for AI in colorectal surgery Journal Article
James M. Kinross, Kyle Lam, Andrew Yiu, Katie Adams, Kiran Altaf, Elaine Burns, Mindy Duffourc, Nicola Eardley, Charles Evans, Stamatia Giannarou, Laura Hancock, Victoria Hu, Ahsan Javed, Shivank Khare, Evangelos Mazomenos, Linnet McGeever, Susan Moug, Piero Nastro, Sebastien Ourselin, Subramanian Ramamoorthy, Campbell Roxburgh, Catherine Simister, Danail Stoyanov, Gregory Thomas, Pietro Valdastri, Marcus Vass, Dale Vimalachandran, Tom Vercauteren, Justin Davies
In: Colorectal Disease, vol. 27, no. 9, 2025.
@article{Kinrossetal2025,
title = {The ACPGBI AI taskforce report: A mixed-methods roadmap for AI in colorectal surgery},
author = {James M. Kinross and Kyle Lam and Andrew Yiu and Katie Adams and Kiran Altaf and Elaine Burns and Mindy Duffourc and Nicola Eardley and Charles Evans and Stamatia Giannarou and Laura Hancock and Victoria Hu and Ahsan Javed and Shivank Khare and Evangelos Mazomenos and Linnet McGeever and Susan Moug and Piero Nastro and Sebastien Ourselin and Subramanian Ramamoorthy and Campbell Roxburgh and Catherine Simister and Danail Stoyanov and Gregory Thomas and Pietro Valdastri and Marcus Vass and Dale Vimalachandran and Tom Vercauteren and Justin Davies},
doi = {10.1111/codi.70232},
year = {2025},
date = {2025-09-16},
urldate = {2025-09-16},
journal = {Colorectal Disease},
volume = {27},
number = {9},
abstract = {Abstract Aim The ACPGBI has commissioned a taskforce to devise a strategy for integrating artificial intelligence (AI) into colorectal surgery. This report aims to (i) map current AI adoption amongst UK colorectal surgeons; (ii) evaluate knowledge, attitudes, perceptions and experience of AI technologies; and (iii) establish priority recommendations to drive innovation across the specialty. Methods A prospective 45-item questionnaire was circulated to the ACPGBI membership. Questionnaire findings were explored at a multidisciplinary round table of surgeons, allied professionals, computer scientists and lawyers. Strategic recommendations were then generated. Results 122 members responded (75.4% consultants; 72.1% male; modal age 41–50 years). Although 43.5% used AI daily, only one third said they could explain key concepts within AI. 86.9% anticipated routine future-AI use, with documentation and imaging ranked highest. 88.5% endorsed formal AI training. Major obstacles were unclear regulation, cost, medicolegal liability and professional or patient distrust. The round table generated 17 recommendations across clinical, educational and research domains and a ten-point action plan, including the establishment of a Colorectal AI Committee and the creation of an open-source colorectal foundational data initiative. Conclusion This taskforce report combines questionnaire insights from the ACPGBI membership and expert debate into 17 key recommendations and a ten-point action plan that will set the direction of future colorectal AI practice. The objective is to establish a framework through which colorectal surgical practice can be augmented by safe, trustworthy AI.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Learning a Neural Association Network for Self-supervised Multi-Object Tracking Proceedings Article
Shuai Li, Michael Burke, Subramanian Ramamoorthy, Juergen Gall
In: 36th British Machine Vision Conference, (BMVC) 24th - 27th November 2025, Sheffield, UK, BMVA Press, 2025.
@inproceedings{li2024learningneuralassociationnetwork,
title = {Learning a Neural Association Network for Self-supervised Multi-Object Tracking},
author = {Shuai Li and Michael Burke and Subramanian Ramamoorthy and Juergen Gall},
url = {https://arxiv.org/abs/2411.11514},
year = {2025},
date = {2025-09-03},
urldate = {2024-01-01},
booktitle = {36th British Machine Vision Conference, (BMVC) 24th - 27th November 2025, Sheffield, UK},
publisher = {BMVA Press},
abstract = {This paper introduces a novel framework to learn data association for multi-object tracking in a self-supervised manner. Fully-supervised learning methods are known to achieve excellent tracking performances, but acquiring identity-level annotations is tedious and time-consuming. Motivated by the fact that in real-world scenarios object motion can be usually represented by a Markov process, we present a novel expectation maximization (EM) algorithm that trains a neural network to associate detections for tracking, without requiring prior knowledge of their temporal correspondences. At the core of our method lies a neural Kalman filter, with an observation model conditioned on associations of detections parameterized by a neural network. Given a batch of frames as input, data associations between detections from adjacent frames are predicted by a neural network followed by a Sinkhorn normalization that determines the assignment probabilities of detections to states. Kalman smoothing is then used to obtain the marginal probability of observations given the inferred states, producing a training objective to maximize this marginal probability using gradient descent. The proposed framework is fully differentiable, allowing the underlying neural model to be trained end-to-end. We evaluate our approach on the challenging MOT17, MOT20, and BDD100K datasets and achieve state-of-the-art results in comparison to self-supervised trackers using public detections.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Beyond Discriminant Patterns: On the Robustness of Decision Rule Ensembles Proceedings Article
Xin Du, Subramanian Ramamoorthy, Wouter Duivesteijn, Jin Tian, Mykola Pechenizkiy
In: IEEE International Conference on Data Mining (ICDM), 2025.
@inproceedings{2109.10432,
title = {Beyond Discriminant Patterns: On the Robustness of Decision Rule Ensembles},
author = {Xin Du and Subramanian Ramamoorthy and Wouter Duivesteijn and Jin Tian and Mykola Pechenizkiy},
url = {https://arxiv.org/abs/2109.10432},
year = {2025},
date = {2025-08-26},
urldate = {2021-09-21},
booktitle = { IEEE International Conference on Data Mining (ICDM)},
abstract = {Local decision rules are commonly understood to be more explainable, due to the local nature of the patterns involved. With numerical optimization methods such as gradient boosting, ensembles of local decision rules can gain good predictive performance on data involving global structure. Meanwhile, machine learning models are being increasingly used to solve problems in high-stake domains including healthcare and finance. Here, there is an emerging consensus regarding the need for practitioners to understand whether and how those models could perform robustly in the deployment environments, in the presence of distributional shifts. Past research on local decision rules has focused mainly on maximizing discriminant patterns, without due consideration of robustness against distributional shifts. In order to fill this gap, we propose a new method to learn and ensemble local decision rules, that are robust both in the training and deployment environments. Specifically, we propose to leverage causal knowledge by regarding the distributional shifts in subpopulations and deployment environments as the results of interventions on the underlying system. We propose two regularization terms based on causal knowledge to search for optimal and stable rules. Experiments on both synthetic and benchmark datasets show that our method is effective and robust against distributional shifts in multiple environments.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Evaluating personalized beneficial interventions in the daily lives of older adults using a camera Proceedings Article
Longfei Chen, Robert B. Fisher, Nusa Faric, Jacques Fleuriot, Subramanian Ramamoorthy
In: Daniele Cafolla, Timothy Rittman, Hao Ni (Ed.): Artificial Intelligence in Healthcare (AIiH), pp. 131-141, Springer Nature, 2025, ISBN: 978-3-032-00656-1.
@inproceedings{chen2025evaluating,
title = {Evaluating personalized beneficial interventions in the daily lives of older adults using a camera},
author = {Longfei Chen and Robert B. Fisher and Nusa Faric and Jacques Fleuriot and Subramanian Ramamoorthy },
editor = {Daniele Cafolla and Timothy Rittman and Hao Ni},
url = {https://link.springer.com/chapter/10.1007/978-3-032-00656-1_10
https://www.arxiv.org/abs/2507.19494},
doi = {10.1007/978-3-032-00656-1_10},
isbn = {978-3-032-00656-1},
year = {2025},
date = {2025-08-20},
urldate = {2025-08-20},
booktitle = {Artificial Intelligence in Healthcare (AIiH)},
volume = {16039},
pages = {131-141},
publisher = {Springer Nature},
series = {Lecture Notes in Computer Science},
abstract = {Beneficial daily activity interventions have been shown to improve both the physical and mental health of older adults. However, there is a lack of robust objective metrics and personalised strategies to measure their impact. In this study, two older adults aged over 65, living in Edinburgh, UK, selected their preferred daily interventions (mindful meals and art crafts), which were then assessed for effectiveness. The total monitoring period across both participants was 8 weeks. Their physical behaviours were continuously monitored using a non-contact, privacy-preserving camera-based system. Postural and mobility statistics were extracted using computer vision algorithms and compared across periods with and without the interventions. The results demonstrate significant behavioural changes for both participants, highlighting the effectiveness of both these activities and the monitoring system.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning Neuro-symbolic Dialogue Strategies for Interactive Symbol Grounding Journal Article
Rimvydas Rubavicius, Alex Lascarides, Subramanian Ramamoorthy
In: Linguistic Issues in Language Technology, vol. 20, iss. 1, 2025.
@article{rubavicius-etal-2025-strategies,
title = {Learning Neuro-symbolic Dialogue Strategies for Interactive Symbol Grounding},
author = {Rimvydas Rubavicius and Alex Lascarides and Subramanian Ramamoorthy },
url = {https://journals.colorado.edu/index.php/lilt/article/view/2457
https://github.com/assistive-autonomy/dialogue-strategies},
doi = {10.33011/lilt.v20.a1},
year = {2025},
date = {2025-08-06},
urldate = {2025-08-06},
journal = {Linguistic Issues in Language Technology},
volume = {20},
issue = {1},
abstract = {Interactive task learning studies situations in which a teacher (task instructor) interacts with a learner (task executor) to perform a novel task in an embodied environment. To successfully interpret the teacher's utterances, the learner has to perform interactive symbol grounding: it must update its prior beliefs about the mapping from symbols to visual referents each time the teacher speaks. Interactive symbol grounding is even more challenging if the learner starts out unaware of concepts that are critical to task success. In that case, the learner must use the embodied conversation to discover and adapt to unforeseen possibilities, and so must cope with a continuously expanding hypothesis space and hence a non-stationary domain model, requiring structure-level updates during interaction. In this paper, we propose a neuro-symbolic model for learning dialogue strategies for achieving interactive symbol grounding. In particular, we study the effects of enriching the model with symbolic reasoning that captures the valid consequences of quantifiers (e.g., both, every). Our hypothesis is that utilizing such reasoning makes interactive task learning more data efficient. We test this empirically via a task of interactive reference resolution, in which the learner must jointly learn a grounding model and a policy for querying the teacher to enhance its accuracy in grounding. Our results show that a learner that exploits such symbolic reasoning for both decision-making and grounding is more data-efficient than learners that ignore such linguistic insights.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
SECURE: Semantics-aware Embodied Conversation under Unawareness for Lifelong Robot Learning Proceedings Article
Rimvydas Rubavicius, Peter David Fagan, Alex Lascarides, Subramanian Ramamoorthy
In: Proceedings of The 4th Conference on Lifelong Learning Agents, PMLR, 2025.
@inproceedings{rubavicius2025securesemanticsawareembodiedconversation,
title = {SECURE: Semantics-aware Embodied Conversation under Unawareness for Lifelong Robot Learning},
author = {Rimvydas Rubavicius and Peter David Fagan and Alex Lascarides and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2409.17755},
year = {2025},
date = {2025-08-01},
urldate = {2025-08-01},
booktitle = {Proceedings of The 4th Conference on Lifelong Learning Agents, PMLR},
abstract = {This paper addresses a challenging interactive task learning scenario we call rearrangement under unawareness: an agent must manipulate a rigid-body environment without knowing a key concept necessary for solving the task and must learn about it during deployment. For example, the user may ask to "put the two granny smith apples inside the basket", but the agent cannot correctly identify which objects in the environment are "granny smith" as the agent has not been exposed to such a concept before. We introduce SECURE, an interactive task learning policy designed to tackle such scenarios. The unique feature of SECURE is its ability to enable agents to engage in semantic analysis when processing embodied conversations and making decisions. Through embodied conversation, a SECURE agent adjusts its deficient domain model by engaging in dialogue to identify and learn about previously unforeseen possibilities. The SECURE agent learns from the user's embodied corrective feedback when mistakes are made and strategically engages in dialogue to uncover useful information about novel concepts relevant to the task. These capabilities enable the SECURE agent to generalize to new tasks with the acquired knowledge. We demonstrate in the simulated Blocksworld and the real-world apple manipulation environments that the SECURE agent, which solves such rearrangements under unawareness, is more data-efficient than agents that do not engage in embodied conversation or semantic analysis.},
howpublished = {Proceedings of The 4th Conference on Lifelong Learning Agents, PMLR},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Assistax: A Hardware-Accelerated Reinforcement Learning Benchmark for Assistive Robotics Working paper
Leonard Hinckeldey, Elliot Fosong, Elle Miller, Rimvydas Rubavicius, Trevor McInroe, Patricia Wollstadt, Christiane B. Wiebel-Herboth, Subramanian Ramamoorthy, Stefano V. Albrecht
2025.
@workingpaper{hinckeldey2025assistax,
title = {Assistax: A Hardware-Accelerated Reinforcement Learning Benchmark for Assistive Robotics},
author = {Leonard Hinckeldey and Elliot Fosong and Elle Miller and Rimvydas Rubavicius and Trevor McInroe and Patricia Wollstadt and Christiane B. Wiebel-Herboth and Subramanian Ramamoorthy and Stefano V. Albrecht},
url = {https://arxiv.org/abs/2507.21638},
year = {2025},
date = {2025-07-29},
urldate = {2025-01-01},
booktitle = {Proc. Coordination and Cooperation in Multi-Agent Reinforcement Learning Workshop (CoCoMARL), RLC},
abstract = {The development of reinforcement learning (RL) algorithms has been largely driven by ambitious challenge tasks and benchmarks. Games have dominated RL benchmarks because they present relevant challenges, are inexpensive to run and easy to understand. While games such as Go and Atari have led to many breakthroughs, they often do not directly translate to real-world embodied applications. In recognising the need to diversify RL benchmarks and addressing complexities that arise in embodied interaction scenarios, we introduce Assistax: an open-source benchmark designed to address challenges arising in assistive robotics tasks. Assistax uses JAX’s hardware acceleration for significant speed-ups for learning in physics-based simulations. In terms of open-loop wall-clock time Assistax runs up to 370 faster, compared to CPU-based alternatives, when vectorising training runs. Assistax conceptualises the interaction between an assistive robot and an active human patient using multi-agent RL to train a population of diverse partner agents against which an embodied robotic agent's zero-shot coordination capabilities can be tested. Extensive evaluation and hyperparameter tuning for popular continuous control RL and MARL algorithms provide reliable baselines and establish Assistax as a practical benchmark for advancing RL research for assistive robotics.
},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Distributional Treatment of Real2Sim2Real for Object-Centric Agent Adaptation in Vision-Driven DLO Manipulation Journal Article
Georgios Kamaras, Subramanian Ramamoorthy
In: IEEE Robotics and Automation Letters (RA-L), vol. 10, no. 8, pp. 8075–8082, 2025, ISSN: 2377-3774.
@article{Kamaras_2025,
title = {Distributional Treatment of Real2Sim2Real for Object-Centric Agent Adaptation in Vision-Driven DLO Manipulation},
author = {Georgios Kamaras and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/11045513},
doi = {10.1109/lra.2025.3581744},
issn = {2377-3774},
year = {2025},
date = {2025-07-20},
urldate = {2025-08-01},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {10},
number = {8},
pages = {8075–8082},
publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
abstract = {We present an integrated (or end-to-end) framework for the Real2Sim2Real problem of manipulating deformable linear objects (DLOs) based on visual perception. Working with a parameterised set of DLOs, we use likelihood-free inference (LFI) to compute the posterior distributions for the physical parameters using which we can approximately simulate the behaviour of each specific DLO. We use these posteriors for domain randomisation while training, in simulation, object-specific visuomotor policies (i.e. assuming only visual and proprioceptive sensory) for a DLO reaching task, using model-free reinforcement learning. We demonstrate the utility of this approach by deploying sim-trained DLO manipulation policies in the real world in a zero-shot manner, i.e. without any further fine-tuning. In this context, we evaluate the capacity of a prominent LFI method to perform fine classification over the parametric set of DLOs, using only visual and proprioceptive data obtained in a dynamic manipulation trajectory. We then study the implications of the resulting domain distributions in sim-based policy learning and real-world performance.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
OPPH: A Vision-Based Operator for Measuring Body Movements for Personal Healthcare Proceedings Article
Chen Long-fei, Subramanian Ramamoorthy, Robert B Fisher
In: Computer Vision – ECCV 2024 Workshops. ECCV 2024. Lecture Notes in Computer Science, 2025.
@inproceedings{longfei2024opphvisionbasedoperatormeasuring,
title = {OPPH: A Vision-Based Operator for Measuring Body Movements for Personal Healthcare},
author = {Chen Long-fei and Subramanian Ramamoorthy and Robert B Fisher},
url = {https://link.springer.com/chapter/10.1007/978-3-031-92591-7_13
https://doi.org/10.1007/978-3-031-92591-7_13
https://arxiv.org/abs/2408.09409},
doi = {10.1007/978-3-031-92591-7_13},
year = {2025},
date = {2025-05-12},
urldate = {2025-05-12},
booktitle = {Computer Vision – ECCV 2024 Workshops. ECCV 2024. Lecture Notes in Computer Science},
volume = {15634},
abstract = {Vision-based motion estimation methods show promise in accurately and unobtrusively estimating human body motion for healthcare purposes. However, these methods are not specifically designed for healthcare purposes and face challenges in real-world applications. Human pose estimation methods often lack the accuracy needed for detecting fine-grained, subtle body movements, while optical flow-based methods struggle with poor lighting conditions and unseen real-world data. These issues result in human body motion estimation errors, particularly during critical medical situations where the body is motionless, such as during unconsciousness. To address these challenges and improve the accuracy of human body motion estimation for healthcare purposes, we propose the OPPH operator designed to enhance current vision-based motion estimation methods. This operator, which considers human body movement and noise properties, functions as a multi-stage filter. Results tested on two real-world and one synthetic human motion dataset demonstrate that the operator effectively removes real-world noise, significantly enhances the detection of motionless states, maintains the accuracy of estimating active body movements, and maintains long-term body movement trends. This method could be beneficial for analyzing both critical medical events and chronic medical conditions.},
howpublished = {In Proc. 12th International Workshop on Assistive Computer Vision and Robotics (ACVR), The European Conference on Computer Vision (ECCV), 2024},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning Visually Grounded Domain Ontologies via Embodied Conversation and Explanation Proceedings Article
Jonghyuk Park, Alex Lascarides, Subramanian Ramamoorthy
In: Proceedings of the AAAI Conference on Artificial Intelligence, pp. 14361-14368, 2025.
@inproceedings{park2024learningvisuallygroundeddomain,
title = {Learning Visually Grounded Domain Ontologies via Embodied Conversation and Explanation},
author = {Jonghyuk Park and Alex Lascarides and Subramanian Ramamoorthy},
url = {https://dl.acm.org/doi/10.1609/aaai.v39i13.33573
https://arxiv.org/abs/2412.09770},
doi = {10.1609/aaai.v39i13.33573},
year = {2025},
date = {2025-04-11},
urldate = {2025-04-11},
booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence},
volume = {39},
number = {13},
pages = {14361-14368},
abstract = {In this paper, we offer a learning framework in which the agent's knowledge gaps are overcome through corrective feedback from a teacher whenever the agent explains its (incorrect) predictions. We test it in a low-resource visual processing scenario, in which the agent must learn to recognize distinct types of toy truck. The agent starts the learning process with no ontology about what types of trucks exist nor which parts they have, and a deficient model for recognizing those parts from visual input. The teacher's feedback to the agent's explanations addresses its lack of relevant knowledge in the ontology via a generic rule (e.g., "dump trucks have dumpers"), whereas an inaccurate part recognition is corrected by a deictic statement (e.g., "this is not a dumper"). The learner utilizes this feedback not only to improve its estimate of the hypothesis space of possible domain ontologies and probability distributions over them, but also to use those estimates to update its visual interpretation of the scene. Our experiments demonstrate that teacher-learner pairs utilizing explanations and corrections are more data-efficient than those without such a faculty.},
howpublished = {In Proc. AAAI Conference on Artificial Intelligence (AAAI-25), 2025},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
ContactFusion: Stochastic Poisson Surface Maps from Visual and Contact Sensing Working paper
Aditya Kamireddypalli, Joao Moura, Russell Buchanan, Sethu Vijayakumar, Subramanian Ramamoorthy
2025.
@workingpaper{kamireddypalli2025contactfusionstochasticpoissonsurface,
title = {ContactFusion: Stochastic Poisson Surface Maps from Visual and Contact Sensing},
author = {Aditya Kamireddypalli and Joao Moura and Russell Buchanan and Sethu Vijayakumar and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2503.16592},
year = {2025},
date = {2025-01-01},
abstract = {Robust and precise robotic assembly entails insertion of constituent components. Insertion success is hindered when noise in scene understanding exceeds tolerance limits, especially when fabricated with tight tolerances. In this work, we propose ContactFusion which combines global mapping with local contact information, fusing point clouds with force sensing. Our method entails a Rejection Sampling based contact occupancy sensing procedure which estimates contact locations on the end-effector from Force/Torque sensing at the wrist. We demonstrate how to fuse contact with visual information into a Stochastic Poisson Surface Map (SPSMap) - a map representation that can be updated with the Stochastic Poisson Surface Reconstruction (SPSR) algorithm. We first validate the contact occupancy sensor in simulation and show its ability to detect the contact location on the robot from force sensing information. Then, we evaluate our method in a peg-in-hole task, demonstrating an improvement in the hole pose estimate with the fusion of the contact information with the SPSMap.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
2024
Click to Grasp: Zero-Shot Precise Manipulation via Visual Diffusion Descriptors Proceedings Article
Nikolaos Tsagkas, Jack Rome, Subramanian Ramamoorthy, Oisin Mac Aodha, Chris Xiaoxuan Lu
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 11610–11617, IEEE, 2024.
@inproceedings{Tsagkas_2024,
title = {Click to Grasp: Zero-Shot Precise Manipulation via Visual Diffusion Descriptors},
author = {Nikolaos Tsagkas and Jack Rome and Subramanian Ramamoorthy and Oisin Mac Aodha and Chris Xiaoxuan Lu},
url = {http://dx.doi.org/10.1109/IROS58592.2024.10801488},
doi = {10.1109/iros58592.2024.10801488},
year = {2024},
date = {2024-12-25},
urldate = {2024-10-01},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
pages = {11610–11617},
publisher = {IEEE},
abstract = {Precise manipulation that is generalizable across scenes and objects remains a persistent challenge in robotics. Current approaches for this task heavily depend on having a significant number of training instances to handle objects with pronounced visual and/or geometric part ambiguities. Our work explores the grounding of fine-grained part descriptors for precise manipulation in a zero-shot setting by utilizing web-trained text-to-image diffusion-based generative models. We tackle the problem by framing it as a dense semantic part correspondence task. Our model returns a gripper pose for manipulating a specific part, using as reference a user-defined click from a source image of a visually different instance of the same object. We require no manual grasping demonstrations as we leverage the intrinsic object geometry and features. Practical experiments in a real-world tabletop scenario validate the efficacy of our approach, demonstrating its potential for advancing semantic-aware robotics manipulation.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Achieving Dexterous Bidirectional Interaction in Uncertain Conditions for Medical Robotics Journal Article
Carlo Tiseo, Quentin Rouxel, Martin Asenov, Keyhan Kouhkiloui Babarahmati, Subramanian Ramamoorthy, Zhibin Li, Michael Mistry
In: IEEE Transactions on Medical Robotics and Bionics (BioRob), vol. 7, no. 1, pp. 43–50, 2024, ISSN: 2576-3202.
@article{Tiseo_2025,
title = {Achieving Dexterous Bidirectional Interaction in Uncertain Conditions for Medical Robotics},
author = {Carlo Tiseo and Quentin Rouxel and Martin Asenov and Keyhan Kouhkiloui Babarahmati and Subramanian Ramamoorthy and Zhibin Li and Michael Mistry},
url = {http://dx.doi.org/10.1109/TMRB.2024.3506163
https://ieeexplore.ieee.org/document/10767388
https://arxiv.org/abs/2206.09906},
doi = {10.1109/tmrb.2024.3506163},
issn = {2576-3202},
year = {2024},
date = {2024-11-25},
urldate = {2025-02-01},
journal = {IEEE Transactions on Medical Robotics and Bionics (BioRob)},
volume = {7},
number = {1},
pages = {43–50},
publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
abstract = {Medical robotics can help improve and extend the reach of healthcare services. A major challenge for medical robots is the complex physical interaction between the robot and the patients which is required to be safe. This work presents the preliminary evaluation of a recently introduced control architecture based on the Fractal Impedance Control (FIC) in medical applications. The deployed FIC architecture is robust to delay between the master and the replica robots. It can switch online between an admittance and impedance behaviour, and it is robust to interaction with unstructured environments. Our experiments analyse three scenarios: teleoperated surgery, rehabilitation, and remote ultrasound scan. The experiments did not require any adjustment of the robot tuning, which is essential in medical applications where the operators do not have an engineering background required to tune the controller. Our results show that is possible to teleoperate the robot to cut using a scalpel, do an ultrasound scan, and perform remote occupational therapy. However, our experiments also highlighted the need for a better robots embodiment to precisely control the system in 3D dynamic tasks.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Learning from Demonstration with Implicit Nonlinear Dynamics Models Working paper
Peter David Fagan, Subramanian Ramamoorthy
2024.
@workingpaper{fagan2025learningdemonstrationimplicitnonlinear,
title = {Learning from Demonstration with Implicit Nonlinear Dynamics Models},
author = {Peter David Fagan and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2409.18768},
year = {2024},
date = {2024-09-27},
urldate = {2025-01-01},
abstract = {Learning from Demonstration (LfD) is a useful paradigm for training policies that solve tasks involving complex motions, such as those encountered in robotic manipulation. In practice, the successful application of LfD requires overcoming error accumulation during policy execution, i.e. the problem of drift due to errors compounding over time and the consequent out-of-distribution behaviours. Existing works seek to address this problem through scaling data collection, correcting policy errors with a human-in-the-loop, temporally ensembling policy predictions or through learning a dynamical system model with convergence guarantees. In this work, we propose and validate an alternative approach to overcoming this issue. Inspired by reservoir computing, we develop a recurrent neural network layer that includes a fixed nonlinear dynamical system with tunable dynamical properties for modelling temporal dynamics. We validate the efficacy of our neural network layer on the task of reproducing human handwriting motions using the LASA Human Handwriting Dataset. Through empirical experiments we demonstrate that incorporating our layer into existing neural network architectures addresses the issue of compounding errors in LfD. Furthermore, we perform a comparative evaluation against existing approaches including a temporal ensemble of policy predictions and an Echo State Network (ESN) implementation. We find that our approach yields greater policy precision and robustness on the handwriting task while also generalising to multiple dynamics regimes and maintaining competitive latency scores.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Generating robotic elliptical excisions with human-like tool-tissue interactions Proceedings Article
Arturas Straizys, Michael Burke, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), pp. 15017-15023, 2024.
@inproceedings{straizys2023generatingroboticellipticalexcisions,
title = {Generating robotic elliptical excisions with human-like tool-tissue interactions},
author = {Arturas Straizys and Michael Burke and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/10610990
https://arxiv.org/abs/2309.12219
https://www.youtube.com/watch?v=dGrn-OBtOms},
doi = {10.1109/ICRA57147.2024.10610990},
year = {2024},
date = {2024-08-08},
urldate = {2024-08-08},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
pages = {15017-15023},
abstract = {In surgery, the application of appropriate force levels is critical for the success and safety of a given procedure. While many studies are focused on measuring in situ forces, little attention has been devoted to relating these observed forces to surgical techniques. Answering questions like "Can certain changes to a surgical technique result in lower forces and increased safety margins?" could lead to improved surgical practice, and importantly, patient outcomes. However, such studies would require a large number of trials and professional surgeons, which is generally impractical to arrange. Instead, we show how robots can learn several variations of a surgical technique from a smaller number of surgical demonstrations and interpolate learnt behaviour via a parameterised skill model. This enables a large number of trials to be performed by a robotic system and the analysis of surgical techniques and their downstream effects on tissue. Here, we introduce a parameterised model of the elliptical excision skill and apply a Bayesian optimisation scheme to optimise the excision behaviour with respect to expert ratings, as well as individual characteristics of excision forces. Results show that the proposed framework can successfully align the generated robot behaviour with subjects across varying levels of proficiency in terms of excision forces.},
howpublished = {In Proc. IEEE International Conference on Robotics and Automation (ICRA), 2024},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Open X-Embodiment: Robotic Learning Datasets and RT-X Models Best Paper Proceedings Article
Open-X Embodiment Collaboration
In: IEEE International Conference on Robotics and Automation (ICRA), pp. 6892-6903, 2024.
@inproceedings{embodimentcollaboration2025openxembodimentroboticlearning,
title = {Open X-Embodiment: Robotic Learning Datasets and RT-X Models},
author = {Open-X Embodiment Collaboration},
url = {https://arxiv.org/abs/2310.08864
https://robotics-transformer-x.github.io},
doi = {10.1109/ICRA57147.2024.10611477},
year = {2024},
date = {2024-08-08},
urldate = {2024-05-01},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
pages = {6892-6903},
abstract = {Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms.},
howpublished = {In Proc. IEEE International Conference on Robotics and Automation (ICRA), 2024.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Adaptive Splitting of Reusable Temporal Monitors for Rare Traffic Violations Proceedings Article
Craig Innes, Subramanian Ramamoorthy
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), pp. 12386-12393, 2024, ISBN: 2153-0866.
@inproceedings{innes2024adaptivesplittingreusabletemporal,
title = {Adaptive Splitting of Reusable Temporal Monitors for Rare Traffic Violations},
author = {Craig Innes and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/10802747
https://arxiv.org/abs/2405.15771},
doi = {10.1109/IROS58592.2024.10802747},
isbn = {2153-0866},
year = {2024},
date = {2024-07-24},
urldate = {2024-01-01},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
pages = {12386-12393},
abstract = {Autonomous Vehicles (AVs) are often tested in simulation to estimate the probability they will violate safety specifications. Two common issues arise when using existing techniques to produce this estimation: If violations occur rarely, simple Monte-Carlo sampling techniques can fail to produce efficient estimates; if simulation horizons are too long, importance sampling techniques (which learn proposal distributions from past simulations) can fail to converge. This paper addresses both issues by interleaving rare-event sampling techniques with online specification monitoring algorithms. We use adaptive multi-level splitting to decompose simulations into partial trajectories, then calculate the distance of those partial trajectories to failure by leveraging robustness metrics from Signal Temporal Logic (STL). By caching those partial robustness metric values, we can efficiently re-use computations across multiple sampling stages. Our experiments on an interstate lane-change scenario show our method is viable for testing simulated AV-pipelines, efficiently estimating failure probabilities for STL specifications based on real traffic rules. We produce better estimates than Monte-Carlo and importance sampling in fewer simulations.},
howpublished = {In Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset Proceedings Article
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, Peter David Fagan, Joey Hejna, Masha Itkina, Marion Lepert, Yecheng Jason Ma, Patrick Tree Miller, Jimmy Wu, Suneel Belkhale, Shivin Dass, Huy Ha, Arhan Jain, Abraham Lee, Youngwoon Lee, Marius Memmel, Sungjae Park, Ilija Radosavovic, Kaiyuan Wang, Albert Zhan, Kevin Black, Cheng Chi, Kyle Beltran Hatch, Shan Lin, Jingpei Lu, Jean Mercat, Abdul Rehman, Pannag R. Sanketi, Archit Sharma, Cody Simpson, Quan Vuong, Homer Rich Walke, Blake Wulfe, Ted Xiao, Jonathan Heewon Yang, Arefeh Yavary, Tony Z. Zhao, Christopher Agia, Rohan Baijal, Mateo Guaman Castro, Daphne Chen, Qiuyu Chen, Trinity Chung, Jaimyn Drake, Ethan Paul Foster, Jensen Gao, David Antonio Herrera, Minho Heo, Kyle Hsu, Jiaheng Hu, Donovon Jackson, Charlotte Le, Yunshuang Li, Roy Lin, Zehan Ma, Abhiram Maddukuri, Suvir Mirchandani, Daniel Morton, Tony Nguyen, Abigail O'Neill, Rosario Scalise, Derick Seale, Victor Son, Stephen Tian, Emi Tran, Andrew E. Wang, Yilin Wu, Annie Xie, Jingyun Yang, Patrick Yin, Yunchu Zhang, Osbert Bastani, Glen Berseth, Jeannette Bohg, Ken Goldberg, Abhinav Gupta, Abhishek Gupta, Dinesh Jayaraman, Joseph J. Lim, Jitendra Malik, Roberto Martín-Martín, Subramanian Ramamoorthy, Dorsa Sadigh, Shuran Song, Jiajun Wu, Michael C. Yip, Yuke Zhu, Thomas Kollar, Sergey Levine, Chelsea Finn
In: Proceedings of Robotics: Science and Systems, Delft, Netherlands, 2024, ISBN: 979-8-9902848-0-7.
@inproceedings{khazatsky2024droid,
title = {DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset},
author = {Alexander Khazatsky and Karl Pertsch and Suraj Nair and Ashwin Balakrishna and Sudeep Dasari and Siddharth Karamcheti and Soroush Nasiriany and Mohan Kumar Srirama and Lawrence Yunliang Chen and Kirsty Ellis and Peter David Fagan and Joey Hejna and Masha Itkina and Marion Lepert and Yecheng Jason Ma and Patrick Tree Miller and Jimmy Wu and Suneel Belkhale and Shivin Dass and Huy Ha and Arhan Jain and Abraham Lee and Youngwoon Lee and Marius Memmel and Sungjae Park and Ilija Radosavovic and Kaiyuan Wang and Albert Zhan and Kevin Black and Cheng Chi and Kyle Beltran Hatch and Shan Lin and Jingpei Lu and Jean Mercat and Abdul Rehman and Pannag R. Sanketi and Archit Sharma and Cody Simpson and Quan Vuong and Homer Rich Walke and Blake Wulfe and Ted Xiao and Jonathan Heewon Yang and Arefeh Yavary and Tony Z. Zhao and Christopher Agia and Rohan Baijal and Mateo Guaman Castro and Daphne Chen and Qiuyu Chen and Trinity Chung and Jaimyn Drake and Ethan Paul Foster and Jensen Gao and David Antonio Herrera and Minho Heo and Kyle Hsu and Jiaheng Hu and Donovon Jackson and Charlotte Le and Yunshuang Li and Roy Lin and Zehan Ma and Abhiram Maddukuri and Suvir Mirchandani and Daniel Morton and Tony Nguyen and Abigail O'Neill and Rosario Scalise and Derick Seale and Victor Son and Stephen Tian and Emi Tran and Andrew E. Wang and Yilin Wu and Annie Xie and Jingyun Yang and Patrick Yin and Yunchu Zhang and Osbert Bastani and Glen Berseth and Jeannette Bohg and Ken Goldberg and Abhinav Gupta and Abhishek Gupta and Dinesh Jayaraman and Joseph J. Lim and Jitendra Malik and Roberto Martín-Martín and Subramanian Ramamoorthy and Dorsa Sadigh and Shuran Song and Jiajun Wu and Michael C. Yip and Yuke Zhu and Thomas Kollar and Sergey Levine and Chelsea Finn},
url = {https://www.roboticsproceedings.org/rss20/p120.html
https://droid-dataset.github.io},
doi = {10.15607/RSS.2024.XX.120},
isbn = {979-8-9902848-0-7},
year = {2024},
date = {2024-07-01},
urldate = {2024-07-01},
booktitle = {Proceedings of Robotics: Science and Systems},
address = {Delft, Netherlands},
abstract = {The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
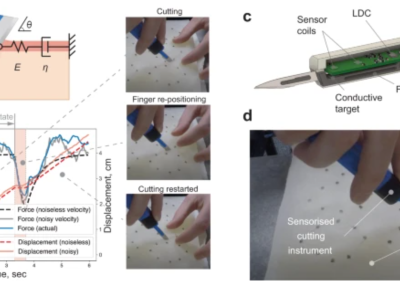
Learning human-like skills for cutting soft objects using force sensing PhD Thesis
Artūras Straižys
University of Edinburgh, 2024.
@phdthesis{straizys2024,
title = {Learning human-like skills for cutting soft objects using force sensing},
author = {Artūras Straižys},
url = {http://dx.doi.org/10.7488/era/4378},
year = {2024},
date = {2024-03-21},
urldate = {2024-03-21},
school = {University of Edinburgh},
abstract = {This thesis investigates the application of force sensing to learn robotic cutting of soft
objects.
The automation of deformable object cutting is a promising prospect for many important
areas, ranging from the food processing industry to soft tissue surgery. However,
the remarkable robustness with which humans perform these tasks is far beyond the
capabilities of current robotics. Humans achieve this robustness by employing various
cutting strategies that rely on tactile feedback. This thesis investigates these abilities,
ways of sensing and modeling these, and approaches to exploit these for robotic
cutting, through four key research contributions.
The first formulates and confirms the hypothesis that forces play a key role in the
robustness of cutting skills. This study investigated the human skills of scooping a
grapefruit with a knife. The insight behind the hypothesis is that humans guide the
knife’s movement using tactile cues that arise at the pulp/peel interface. Experiments
conducted in this thesis indicate that similar torque-based movement adaptation is an
effective strategy in robotic grapefruit scooping. The proposed method can be used
in many practical applications where cutting along the medium boundary is required;
for example, in surgical excision of solid tumours within soft tissue.
A second study considered the practical implementation of robotic cutting systems
that must account for a number of constraints. In many cutting tasks, the required
adaptation of cutting movement is subject to a non-holonomic constraint that restricts
the lateral motion of the blade. This makes it difficult to encode cutting motions using
dynamical system-based methods, such as dynamical movement primitives (DMPs),
otherwise well suited for learning complex reactive behaviours. The non-holonomic
DMPs proposed in this thesis introduce a coupling term derived by the Udwadia-
Kalaba method that guarantees run-time satisfaction of a wide range of constraints,
including non-holonomic. We demonstrate how this approach can be applied to learn
robotic cutting skills from demonstration.
A third study on the role of forces in surgical excisions has shown that the force
modality contains valuable information for skill understanding. It was found that incision
forces consist of subject-specific signatures that reflect excision assessment
by experts. We proposed a generative model of excision forces, which decomposes
cutting behaviour into amplitude and temporal components that encode meaningful
characteristics of the observed behaviour. Along with a novel sensorised instrument
developed for this study, this model can form the basis for surgical training systems
with objective skill assessment and opens up many opportunities for learning humanlike
robotic excision of soft tissues.
Finally, these approaches were combined for learning human-like robotic elliptical
excision skills, following an approach using the previously developed sensorised instrument
and the model of elliptical excision forces.We introduced a generative model
for pose trajectories of the blade in the elliptical excision task and used it to encode
the observed excision behaviours. We demonstrate how the proposed model of excision
forces can be employed to optimise the robotic behaviour with respect to the
performance assessment of experts and the desired human-like characteristics of
cutting forces.
This work let us analyse complex cutting tasks, techniques and skills from human
demonstrations. Such analysis can lead us to understand better what underlies these
skills in humans and how these can be replicated by a robot.},
howpublished = {Edinburgh Research Archive (ERA)},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
objects.
The automation of deformable object cutting is a promising prospect for many important
areas, ranging from the food processing industry to soft tissue surgery. However,
the remarkable robustness with which humans perform these tasks is far beyond the
capabilities of current robotics. Humans achieve this robustness by employing various
cutting strategies that rely on tactile feedback. This thesis investigates these abilities,
ways of sensing and modeling these, and approaches to exploit these for robotic
cutting, through four key research contributions.
The first formulates and confirms the hypothesis that forces play a key role in the
robustness of cutting skills. This study investigated the human skills of scooping a
grapefruit with a knife. The insight behind the hypothesis is that humans guide the
knife’s movement using tactile cues that arise at the pulp/peel interface. Experiments
conducted in this thesis indicate that similar torque-based movement adaptation is an
effective strategy in robotic grapefruit scooping. The proposed method can be used
in many practical applications where cutting along the medium boundary is required;
for example, in surgical excision of solid tumours within soft tissue.
A second study considered the practical implementation of robotic cutting systems
that must account for a number of constraints. In many cutting tasks, the required
adaptation of cutting movement is subject to a non-holonomic constraint that restricts
the lateral motion of the blade. This makes it difficult to encode cutting motions using
dynamical system-based methods, such as dynamical movement primitives (DMPs),
otherwise well suited for learning complex reactive behaviours. The non-holonomic
DMPs proposed in this thesis introduce a coupling term derived by the Udwadia-
Kalaba method that guarantees run-time satisfaction of a wide range of constraints,
including non-holonomic. We demonstrate how this approach can be applied to learn
robotic cutting skills from demonstration.
A third study on the role of forces in surgical excisions has shown that the force
modality contains valuable information for skill understanding. It was found that incision
forces consist of subject-specific signatures that reflect excision assessment
by experts. We proposed a generative model of excision forces, which decomposes
cutting behaviour into amplitude and temporal components that encode meaningful
characteristics of the observed behaviour. Along with a novel sensorised instrument
developed for this study, this model can form the basis for surgical training systems
with objective skill assessment and opens up many opportunities for learning humanlike
robotic excision of soft tissues.
Finally, these approaches were combined for learning human-like robotic elliptical
excision skills, following an approach using the previously developed sensorised instrument
and the model of elliptical excision forces.We introduced a generative model
for pose trajectories of the blade in the elliptical excision task and used it to encode
the observed excision behaviours. We demonstrate how the proposed model of excision
forces can be employed to optimise the robotic behaviour with respect to the
performance assessment of experts and the desired human-like characteristics of
cutting forces.
This work let us analyse complex cutting tasks, techniques and skills from human
demonstrations. Such analysis can lead us to understand better what underlies these
skills in humans and how these can be replicated by a robot.
Unobtrusive Monitoring of Physical Weakness: A Simulated Approach Working paper
Chen Long-fei, Muhammad Ahmed Raza, Craig Innes, Subramanian Ramamoorthy, Robert B. Fisher
2024.
@workingpaper{longfei2024unobtrusivemonitoringphysicalweakness,
title = {Unobtrusive Monitoring of Physical Weakness: A Simulated Approach},
author = {Chen Long-fei and Muhammad Ahmed Raza and Craig Innes and Subramanian Ramamoorthy and Robert B. Fisher},
url = {https://arxiv.org/abs/2406.10045},
year = {2024},
date = {2024-01-01},
urldate = {2024-01-01},
abstract = {Aging and chronic conditions affect older adults' daily lives, making early detection of developing health issues crucial. Weakness, common in many conditions, alters physical movements and daily activities subtly. However, detecting such changes can be challenging due to their subtle and gradual nature. To address this, we employ a non-intrusive camera sensor to monitor individuals' daily sitting and relaxing activities for signs of weakness. We simulate weakness in healthy subjects by having them perform physical exercise and observing the behavioral changes in their daily activities before and after workouts. The proposed system captures fine-grained features related to body motion, inactivity, and environmental context in real-time while prioritizing privacy. A Bayesian Network is used to model the relationships between features, activities, and health conditions. We aim to identify specific features and activities that indicate such changes and determine the most suitable time scale for observing the change. Results show 0.97 accuracy in distinguishing simulated weakness at the daily level. Fine-grained behavioral features, including non-dominant upper body motion speed and scale, and inactivity distribution, along with a 300-second window, are found most effective. However, individual-specific models are recommended as no universal set of optimal features and activities was identified across all participants.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
2023
On Specifying for Trustworthiness Journal Article
Dhaminda B. Abeywickrama, Amel Bennaceur, Greg Chance, Yiannis Demiris, Anastasia Kordoni, Mark Levine, Luke Moffat, Luc Moreau, Mohammad Reza Mousavi, Bashar Nuseibeh, Subramanian Ramamoorthy, Jan Oliver Ringert, James Wilson, Shane Windsor, Kerstin Eder
In: Communications of the ACM, vol. 67, iss. 1, pp. 98–109, 2023, ISSN: 1557-7317.
@article{Abeywickrama_2023,
title = {On Specifying for Trustworthiness},
author = {Dhaminda B. Abeywickrama and Amel Bennaceur and Greg Chance and Yiannis Demiris and Anastasia Kordoni and Mark Levine and Luke Moffat and Luc Moreau and Mohammad Reza Mousavi and Bashar Nuseibeh and Subramanian Ramamoorthy and Jan Oliver Ringert and James Wilson and Shane Windsor and Kerstin Eder},
url = {https://dl.acm.org/doi/10.1145/3624699
https://arxiv.org/abs/2206.11421},
doi = {10.1145/3624699},
issn = {1557-7317},
year = {2023},
date = {2023-12-21},
urldate = {2023-12-21},
journal = {Communications of the ACM},
volume = {67},
issue = {1},
pages = {98–109},
publisher = {Association for Computing Machinery (ACM)},
abstract = {As autonomous systems (AS) increasingly become part of our daily lives, ensuring their trustworthiness is crucial. In order to demonstrate the trustworthiness of an AS, we first need to specify what is required for an AS to be considered trustworthy. This roadmap paper identifies key challenges for specifying for trustworthiness in AS, as identified during the "Specifying for Trustworthiness" workshop held as part of the UK Research and Innovation (UKRI) Trustworthy Autonomous Systems (TAS) programme. We look across a range of AS domains with consideration of the resilience, trust, functionality, verifiability, security, and governance and regulation of AS and identify some of the key specification challenges in these domains. We then highlight the intellectual challenges that are involved with specifying for trustworthiness in AS that cut across domains and are exacerbated by the inherent uncertainty involved with the environments in which AS need to operate.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Anticipating Accidents through Reasoned Simulation Proceedings Article
Craig Innes, Andrew Ireland, Yuhui Lin, Subramanian Ramamoorthy
In: Proceedings of the First International Symposium on Trustworthy Autonomous Systems (TAS), Association for Computing Machinery (ACM), 2023, ISSN: 9798400707346.
@inproceedings{Innes2023,
title = {Anticipating Accidents through Reasoned Simulation},
author = {Craig Innes and Andrew Ireland and Yuhui Lin and Subramanian Ramamoorthy},
url = {https://dl.acm.org/doi/10.1145/3597512.3599698},
doi = {10.1145/3597512.3599698},
issn = {9798400707346},
year = {2023},
date = {2023-07-11},
urldate = {2023-07-11},
booktitle = {Proceedings of the First International Symposium on Trustworthy Autonomous Systems (TAS)},
volume = {1},
number = {4},
publisher = {Association for Computing Machinery (ACM)},
abstract = {A key goal of the System-Theoretic Process Analysis (STPA) hazard analysis technique is the identification of loss scenarios – causal factors that could potentially lead to an accident. We propose an approach that aims to assist engineers in identifying potential loss scenarios that are associated with flawed assumptions about a system’s intended operational environment. Our approach combines aspects of STPA with formal modelling and simulation. Currently, we are at a proof-of-concept stage and illustrate the approach using a case study based upon a simple car door locking system. In terms of the formal modelling, we use Extended Logic Programming (ELP) and on the simulation side, we use the CARLA simulator for autonomous driving. We make use of the problem frames approach to requirements engineering to bridge between the informal aspects of STPA and our formal modelling.},
howpublished = {In Proc. International Symposium on Trustworthy Autonomous Systems (TAS)},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning rewards from exploratory demonstrations using probabilistic temporal ranking Journal Article
Michael Burke, Katie Lu, Daniel Angelov, Artūras Straižys, Craig Innes, Kartic Subr, Subramanian Ramamoorthy
In: Autonomous Robots, vol. 47, no. 6, pp. 733–751, 2023, ISSN: 1573-7527.
@article{Burke2023,
title = {Learning rewards from exploratory demonstrations using probabilistic temporal ranking},
author = {Michael Burke and Katie Lu and Daniel Angelov and Artūras Straižys and Craig Innes and Kartic Subr and Subramanian Ramamoorthy},
url = {https://doi.org/10.1007/s10514-023-10120-w
https://sites.google.com/view/ultrasound-scanner
https://www.youtube.com/watch?v=AzgIrblR0ME},
doi = {10.1007/s10514-023-10120-w},
issn = {1573-7527},
year = {2023},
date = {2023-07-10},
urldate = {2023-08-00},
journal = {Autonomous Robots},
volume = {47},
number = {6},
pages = {733--751},
publisher = {Springer Science and Business Media LLC},
abstract = {Informative path-planning is a well established approach to visual-servoing and active viewpoint selection in robotics, but typically assumes that a suitable cost function or goal state is known. This work considers the inverse problem, where the goal of the task is unknown, and a reward function needs to be inferred from exploratory example demonstrations provided by a demonstrator, for use in a downstream informative path-planning policy. Unfortunately, many existing reward inference strategies are unsuited to this class of problems, due to the exploratory nature of the demonstrations. In this paper, we propose an alternative approach to cope with the class of problems where these sub-optimal, exploratory demonstrations occur. We hypothesise that, in tasks which require discovery, successive states of any demonstration are progressively more likely to be associated with a higher reward, and use this hypothesis to generate time-based binary comparison outcomes and infer reward functions that support these ranks, under a probabilistic generative model. We formalise this probabilistic temporal ranking approach and show that it improves upon existing approaches to perform reward inference for autonomous ultrasound scanning, a novel application of learning from demonstration in medical imaging while also being of value across a broad range of goal-oriented learning from demonstration tasks.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Testing Rare Downstream Safety Violations via Upstream Adaptive Sampling of Perception Error Models Proceedings Article
Craig Innes, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2023, ISBN: 979-8-3503-2365-8.
@inproceedings{innes2023testingraredownstreamsafety,
title = {Testing Rare Downstream Safety Violations via Upstream Adaptive Sampling of Perception Error Models},
author = {Craig Innes and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/10161501
https://arxiv.org/abs/2209.09674},
doi = {10.1109/ICRA48891.2023.10161501},
isbn = {979-8-3503-2365-8},
year = {2023},
date = {2023-07-04},
urldate = {2023-01-01},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {Testing black-box perceptual-control systems in simulation faces two difficulties. Firstly, perceptual inputs in simulation lack the fidelity of real-world sensor inputs. Secondly, for a reasonably accurate perception system, encountering a rare failure trajectory may require running infeasibly many simulations. This paper combines perception error models -- surrogates for a sensor-based detection system -- with state-dependent adaptive importance sampling. This allows us to efficiently assess the rare failure probabilities for real-world perceptual control systems within simulation. Our experiments with an autonomous braking system equipped with an RGB obstacle-detector show that our method can calculate accurate failure probabilities with an inexpensive number of simulations. Further, we show how choice of safety metric can influence the process of learning proposal distributions capable of reliably sampling high-probability failures.},
howpublished = {In Proc. IEEE International Conference on Robotics and Automation (ICRA), 2023},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning robotic cutting from demonstration: Non-holonomic DMPs using the Udwadia-Kalaba method Proceedings Article
Artūras Straižys, Michael Burke, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2023, ISBN: 979-8-3503-2365-8.
@inproceedings{straižys2022learningroboticcuttingdemonstration,
title = {Learning robotic cutting from demonstration: Non-holonomic DMPs using the Udwadia-Kalaba method},
author = {Artūras Straižys and Michael Burke and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/10160917
https://arxiv.org/abs/2209.12039
https://github.com/straizys/nonholonomic-dmp},
doi = {10.1109/ICRA48891.2023.10160917},
isbn = {979-8-3503-2365-8},
year = {2023},
date = {2023-07-04},
urldate = {2022-01-01},
booktitle = { IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {Dynamic Movement Primitives (DMPs) offer great versatility for encoding, generating and adapting complex end-effector trajectories. DMPs are also very well suited to learning manipulation skills from human demonstration. However, the reactive nature of DMPs restricts their applicability for tool use and object manipulation tasks involving non-holonomic constraints, such as scalpel cutting or catheter steering. In this work, we extend the Cartesian space DMP formulation by adding a coupling term that enforces a pre-defined set of non-holonomic constraints. We obtain the closed-form expression for the constraint forcing term using the Udwadia-Kalaba method. This approach offers a clean and practical solution for guaranteed constraint satisfaction at run-time. Further, the proposed analytical form of the constraint forcing term enables efficient trajectory optimization subject to constraints. We demonstrate the usefulness of this approach by showing how we can learn robotic cutting skills from human demonstration.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
A generative force model for surgical skill quantification using sensorised instruments Journal Article
Artūras Straižys, Michael Burke, Paul M. Brennan, Subramanian Ramamoorthy
In: Communications Engineering, vol. 2, no. 36, 2023, ISSN: 2731-3395.
@article{Straižys2023,
title = {A generative force model for surgical skill quantification using sensorised instruments},
author = {Artūras Straižys and Michael Burke and Paul M. Brennan and Subramanian Ramamoorthy},
url = {https://www.nature.com/articles/s44172-023-00086-z},
doi = {10.1038/s44172-023-00086-z},
issn = {2731-3395},
year = {2023},
date = {2023-06-10},
urldate = {2023-12-00},
journal = {Communications Engineering},
volume = {2},
number = {36},
publisher = {Springer Science and Business Media LLC},
abstract = {Surgical skill requires the manipulation of soft viscoelastic media. Its measurement through generative models is essential both for accurate quantification of surgical ability and for eventual automation in robotic platforms. Here we describe a sensorised scalpel, along with a generative model to assess surgical skill in elliptical excision, a representative manipulation task. Our approach allows us to capture temporal features via data collection and downstream analysis. We demonstrate that incision forces carry information that is relevant for skill interpretation, but inaccessible via conventional descriptive statistics. We tested our approach on 12 medical students and two practicing surgeons using a tissue phantom mimicking the properties of human skin. We demonstrate that our approach can bring deeper insight into performance analysis than traditional time and motion studies, and help to explain subjective assessor skill ratings. Our technique could be useful in applications spanning forensics, pathology as well as surgical skill quantification.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
DiPA: Probabilistic Multi-Modal Interactive Prediction for Autonomous Driving Journal Article
Anthony Knittel, Majd Hawasly, Stefano V. Albrecht, John Redford, Subramanian Ramamoorthy
In: IEEE Robotics and Automation Letters (RA-L), vol. 8, no. 8, pp. 4887–4894, 2023, ISSN: 2377-3774, (Workd done at FiveAI).
@article{Knittel_2023,
title = {DiPA: Probabilistic Multi-Modal Interactive Prediction for Autonomous Driving},
author = {Anthony Knittel and Majd Hawasly and Stefano V. Albrecht and John Redford and Subramanian Ramamoorthy},
url = {http://dx.doi.org/10.1109/LRA.2023.3284355},
doi = {10.1109/lra.2023.3284355},
issn = {2377-3774},
year = {2023},
date = {2023-06-08},
urldate = {2023-06-08},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {8},
number = {8},
pages = {4887–4894},
publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
abstract = {Accurate prediction is important for operating an autonomous vehicle in interactive scenarios. Prediction must be fast, to support multiple requests from a planner exploring a range of possible futures. The generated predictions must accurately represent the probabilities of predicted trajectories, while also capturing different modes of behaviour (such as turning left vs continuing straight at a junction). To this end, we present DiPA, an interactive predictor that addresses these challenging requirements. Previous interactive prediction methods use an encoding of k-mode-samples, which under-represents the full distribution. Other methods optimise closest-mode evaluations, which test whether one of the predictions is similar to the ground-truth, but allow additional unlikely predictions to occur, over-representing unlikely predictions. DiPA addresses these limitations by using a Gaussian-Mixture-Model to encode the full distribution, and optimising predictions using both probabilistic and closest-mode measures. These objectives respectively optimise probabilistic accuracy and the ability to capture distinct behaviours, and there is a challenging trade-off between them. We are able to solve both together using a novel training regime. DiPA achieves new state-of-the-art performance on the INTERACTION and NGSIM datasets, and improves over the baseline (MFP) when both closest-mode and probabilistic evaluations are used. This demonstrates effective prediction for supporting a planner on interactive scenarios.},
note = {Workd done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Interactive Acquisition of Fine-grained Visual Concepts by Exploiting Semantics of Generic Characterizations in Discourse Best Paper Proceedings Article
Jonghyuk Park, Alex Lascarides, Subramanian Ramamoorthy
In: Proceedings of International Conference on Computational Semantics (IWCS), pp. 318-331, Association for Computational Linguistics, 2023.
@inproceedings{park2023interactiveacquisitionfinegrainedvisual,
title = {Interactive Acquisition of Fine-grained Visual Concepts by Exploiting Semantics of Generic Characterizations in Discourse},
author = {Jonghyuk Park and Alex Lascarides and Subramanian Ramamoorthy},
url = {https://aclanthology.org/2023.iwcs-1.33/
https://arxiv.org/abs/2305.03461},
year = {2023},
date = {2023-06-01},
urldate = {2023-06-01},
booktitle = {Proceedings of International Conference on Computational Semantics (IWCS)},
volume = {1},
pages = {318-331},
publisher = {Association for Computational Linguistics},
abstract = {Interactive Task Learning (ITL) concerns learning about unforeseen domain concepts via natural interactions with human users. The learner faces a number of significant constraints: learning should be online, incremental and few-shot, as it is expected to perform tangible belief updates right after novel words denoting unforeseen concepts are introduced. In this work, we explore a challenging symbol grounding task--discriminating among object classes that look very similar--within the constraints imposed by ITL. We demonstrate empirically that more data-efficient grounding results from exploiting the truth-conditions of the teacher's generic statements (e.g., "Xs have attribute Z.") and their implicatures in context (e.g., as an answer to "How are Xs and Ys different?", one infers Y lacks attribute Z).},
howpublished = {In Proc. International Conference on Computational Semantics (IWCS), 2023. [Outstanding Paper Award]},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Anthony Knittel, Morris Antonello, John Redford, Subramanian Ramamoorthy
2023, (Work done at FiveAI).
@workshop{knittel2023comparisonpedestrianpredictionmodels,
title = {Comparison of Pedestrian Prediction Models from Trajectory and Appearance Data for Autonomous Driving},
author = {Anthony Knittel and Morris Antonello and John Redford and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2305.15942},
year = {2023},
date = {2023-05-25},
urldate = {2023-05-25},
abstract = {The ability to anticipate pedestrian motion changes is a critical capability for autonomous vehicles. In urban environments, pedestrians may enter the road area and create a high risk for driving, and it is important to identify these cases. Typical predictors use the trajectory history to predict future motion, however in cases of motion initiation, motion in the trajectory may only be clearly visible after a delay, which can result in the pedestrian has entered the road area before an accurate prediction can be made. Appearance data includes useful information such as changes of gait, which are early indicators of motion changes, and can inform trajectory prediction. This work presents a comparative evaluation of trajectory-only and appearance-based methods for pedestrian prediction, and introduces a new dataset experiment for prediction using appearance. We create two trajectory and image datasets based on the combination of image and trajectory sequences from the popular NuScenes dataset, and examine prediction of trajectories using observed appearance to influence futures. This shows some advantages over trajectory prediction alone, although problems with the dataset prevent advantages of appearance-based models from being shown. We describe methods for improving the dataset and experiment to allow benefits of appearance-based models to be captured.},
howpublished = {In Workshop on Long-term Human Motion Prediction, ICRA },
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Beyond RMSE: Do Machine-Learned Models of Road User Interaction Produce Human-Like Behavior? Journal Article
Aravinda Ramakrishnan Srinivasan, Yi-Shin Lin, Morris Antonello, Anthony Knittel, Mohamed Hasan, Majd Hawasly, John Redford, Subramanian Ramamoorthy, Matteo Leonetti, Jac Billington, Richard Romano, Gustav Markkula
In: IEEE Transactions on Intelligent Transportation Systems (T-ITS), vol. 24, no. 7, pp. 7166–7177, 2023, ISSN: 1558-0016, (Work done at FiveAI).
@article{Srinivasan_2023,
title = {Beyond RMSE: Do Machine-Learned Models of Road User Interaction Produce Human-Like Behavior?},
author = {Aravinda Ramakrishnan Srinivasan and Yi-Shin Lin and Morris Antonello and Anthony Knittel and Mohamed Hasan and Majd Hawasly and John Redford and Subramanian Ramamoorthy and Matteo Leonetti and Jac Billington and Richard Romano and Gustav Markkula},
url = {http://dx.doi.org/10.1109/TITS.2023.3263358},
doi = {10.1109/tits.2023.3263358},
issn = {1558-0016},
year = {2023},
date = {2023-04-04},
urldate = {2023-04-04},
journal = {IEEE Transactions on Intelligent Transportation Systems (T-ITS)},
volume = {24},
number = {7},
pages = {7166–7177},
publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
abstract = {Autonomous vehicles use a variety of sensors and machine-learned models to predict the behavior of surrounding road users. Most of the machine-learned models in the literature focus on quantitative error metrics like the root mean square error (RMSE) to learn and report their models' capabilities. This focus on quantitative error metrics tends to ignore the more important behavioral aspect of the models, raising the question of whether these models really predict human-like behavior. Thus, we propose to analyze the output of machine-learned models much like we would analyze human data in conventional behavioral research. We introduce quantitative metrics to demonstrate presence of three different behavioral phenomena in a naturalistic highway driving dataset: 1) The kinematics-dependence of who passes a merging point first 2) Lane change by an on-highway vehicle to accommodate an on-ramp vehicle 3) Lane changes by vehicles on the highway to avoid lead vehicle conflicts. Then, we analyze the behavior of three machine-learned models using the same metrics. Even though the models' RMSE value differed, all the models captured the kinematic-dependent merging behavior but struggled at varying degrees to capture the more nuanced courtesy lane change and highway lane change behavior. Additionally, the collision aversion analysis during lane changes showed that the models struggled to capture the physical aspect of human driving: leaving adequate gap between the vehicles. Thus, our analysis highlighted the inadequacy of simple quantitative metrics and the need to take a broader behavioral perspective when analyzing machine-learned models of human driving predictions.},
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Todor Bozhinov Davchev
University of Edinburgh, 2023.
@phdthesis{nokey,
title = {Structured machine learning models for robustness against different factors of variability in robot control},
author = {Todor Bozhinov Davchev},
url = {http://dx.doi.org/10.7488/era/2930},
doi = {10.7488/era/2930},
year = {2023},
date = {2023-01-11},
urldate = {2023-01-11},
school = {University of Edinburgh},
abstract = {An important feature of human sensorimotor skill is our ability to learn to reuse them across different environmental contexts, in part due to our understanding of attributes of variability in these environments. This thesis explores how the structure of models used within learning for robot control could similarly help autonomous robots cope with variability, hence achieving skill generalisation. The overarching approach is to develop modular architectures that judiciously combine different forms of inductive bias for learning. In particular, we consider how models and policies should be structured in order to achieve robust behaviour in the face of different factors of variation - in the environment, in objects and in other internal parameters of a policy - with the end goal of more robust, accurate and data-efficient skill acquisition and adaptation.
At a high level, variability in skill is determined by variations in constraints presented by the external environment, and in task-specific perturbations that affect the specification of optimal action. A typical example of environmental perturbation would be variation in lighting and illumination, affecting the noise characteristics of perception. An example of task perturbations would be variation in object geometry, mass or friction, and in the specification of costs associated with speed or smoothness of execution. We counteract these factors of variation by exploring three forms of structuring: utilising separate data sets curated according to the relevant factor of variation, building neural network models that incorporate this factorisation into the very structure of the networks, and learning structured loss functions. The thesis is comprised of four projects exploring this theme within robotics planning and prediction tasks.
Firstly, in the setting of trajectory prediction in crowded scenes, we explore a modular architecture for learning static and dynamic environmental structure. We show that factorising the prediction problem from the individual representations allows for robust and label efficient forward modelling, and relaxes the need for full model re-training in new environments. This modularity explicitly allows for a more flexible and interpretable adaptation of trajectory prediction models to using
pre-trained state of the art models. We show that this results in more efficient motion prediction and allows for performance comparable to the state-of-the-art supervised 2D trajectory prediction.
Next, in the domain of contact-rich robotic manipulation, we consider a modular architecture that combines model-free learning from demonstration, in particular dynamic movement primitives (DMP), with modern model-free reinforcement learning (RL), using both on-policy and off-policy approaches. We show that factorising the skill learning problem to skill acquisition and error correction through policy adaptation strategies such as residual learning can help improve the overall performance of policies in the context of contact-rich manipulation. Our empirical evaluation demonstrates how to best do this with DMPs and propose “residual Learning from Demonstration“ (rLfD), a framework that combines DMPs with RL to learn a residual correction policy. Our evaluations, performed both in simulation and on a physical system, suggest that applying residual learning directly in task space and operating on the full pose of the robot can significantly improve the overall performance of DMPs. We show that rLfD offers a gentle to the joints solution that improves the task success and generalisation of DMPs. Last but not least, our study shows that the extracted correction policies can be transferred to different geometries and frictions through few-shot task adaptation.
Third, we employ meta learning to learn time-invariant reward functions, wherein both the objectives of a task (i.e., the reward functions) and the policy for performing that task optimally are learnt simultaneously. We propose a novel inverse reinforcement learning (IRL) formulation that allows us to 1) vary the length of execution by learning time-invariant costs, and 2) relax the temporal alignment requirements for learning from demonstration. We apply our method to two different types of cost formulations and evaluate their performance in the context of learning reward functions for simulated placement and peg in hole tasks executed on a 7DoF Kuka IIWA arm. Our results show that our approach enables learning temporally invariant rewards from misaligned demonstration that can also generalise spatially to out of distribution tasks.
Finally, we employ our observations to evaluate adversarial robustness in the context of transfer learning from a source trained on CIFAR 100 to a target network trained on CIFAR 10. Specifically, we study the effects of using robust optimisation in the source and target networks. This allows us to identify transfer learning strategies under which adversarial defences are successfully retained, in addition to revealing potential vulnerabilities. We study the extent to which adversarially robust features can preserve their defence properties against black and white-box attacks under three different transfer learning strategies. Our empirical evaluations give insights on how well adversarial robustness under transfer learning can generalise.},
howpublished = {Edinburgh Research Archive (ERA)},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
At a high level, variability in skill is determined by variations in constraints presented by the external environment, and in task-specific perturbations that affect the specification of optimal action. A typical example of environmental perturbation would be variation in lighting and illumination, affecting the noise characteristics of perception. An example of task perturbations would be variation in object geometry, mass or friction, and in the specification of costs associated with speed or smoothness of execution. We counteract these factors of variation by exploring three forms of structuring: utilising separate data sets curated according to the relevant factor of variation, building neural network models that incorporate this factorisation into the very structure of the networks, and learning structured loss functions. The thesis is comprised of four projects exploring this theme within robotics planning and prediction tasks.
Firstly, in the setting of trajectory prediction in crowded scenes, we explore a modular architecture for learning static and dynamic environmental structure. We show that factorising the prediction problem from the individual representations allows for robust and label efficient forward modelling, and relaxes the need for full model re-training in new environments. This modularity explicitly allows for a more flexible and interpretable adaptation of trajectory prediction models to using
pre-trained state of the art models. We show that this results in more efficient motion prediction and allows for performance comparable to the state-of-the-art supervised 2D trajectory prediction.
Next, in the domain of contact-rich robotic manipulation, we consider a modular architecture that combines model-free learning from demonstration, in particular dynamic movement primitives (DMP), with modern model-free reinforcement learning (RL), using both on-policy and off-policy approaches. We show that factorising the skill learning problem to skill acquisition and error correction through policy adaptation strategies such as residual learning can help improve the overall performance of policies in the context of contact-rich manipulation. Our empirical evaluation demonstrates how to best do this with DMPs and propose “residual Learning from Demonstration“ (rLfD), a framework that combines DMPs with RL to learn a residual correction policy. Our evaluations, performed both in simulation and on a physical system, suggest that applying residual learning directly in task space and operating on the full pose of the robot can significantly improve the overall performance of DMPs. We show that rLfD offers a gentle to the joints solution that improves the task success and generalisation of DMPs. Last but not least, our study shows that the extracted correction policies can be transferred to different geometries and frictions through few-shot task adaptation.
Third, we employ meta learning to learn time-invariant reward functions, wherein both the objectives of a task (i.e., the reward functions) and the policy for performing that task optimally are learnt simultaneously. We propose a novel inverse reinforcement learning (IRL) formulation that allows us to 1) vary the length of execution by learning time-invariant costs, and 2) relax the temporal alignment requirements for learning from demonstration. We apply our method to two different types of cost formulations and evaluate their performance in the context of learning reward functions for simulated placement and peg in hole tasks executed on a 7DoF Kuka IIWA arm. Our results show that our approach enables learning temporally invariant rewards from misaligned demonstration that can also generalise spatially to out of distribution tasks.
Finally, we employ our observations to evaluate adversarial robustness in the context of transfer learning from a source trained on CIFAR 100 to a target network trained on CIFAR 10. Specifically, we study the effects of using robust optimisation in the source and target networks. This allows us to identify transfer learning strategies under which adversarial defences are successfully retained, in addition to revealing potential vulnerabilities. We study the extent to which adversarially robust features can preserve their defence properties against black and white-box attacks under three different transfer learning strategies. Our empirical evaluations give insights on how well adversarial robustness under transfer learning can generalise.
2022
A Novel Design and Evaluation of a Dactylus-Equipped Quadruped Robot for Mobile Manipulation Proceedings Article
Yordan Tsvetkov, Subramanian Ramamoorthy
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022.
@inproceedings{tsvetkov2022noveldesignevaluationdactylusequipped,
title = {A Novel Design and Evaluation of a Dactylus-Equipped Quadruped Robot for Mobile Manipulation},
author = {Yordan Tsvetkov and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9982229
https://arxiv.org/abs/2207.08765},
doi = {10.1109/IROS47612.2022.9982229},
year = {2022},
date = {2022-12-26},
urldate = {2022-01-01},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
abstract = {Quadruped robots are usually equipped with additional arms for manipulation, negatively impacting price and weight. On the other hand, the requirements of legged locomotion mean that the legs of such robots often possess the needed torque and precision to perform manipulation. In this paper, we present a novel design for a small-scale quadruped robot equipped with two leg-mounted manipulators inspired by crustacean chelipeds and knuckle-walker forelimbs. By making use of the actuators already present in the legs, we can achieve manipulation using only 3 additional motors per limb. The design enables the use of small and inexpensive actuators relative to the leg motors, further reducing cost and weight. The moment of inertia impact on the leg is small thanks to an integrated cable/pulley system. As we show in a suite of tele-operation experiments, the robot is capable of performing single- and dual-limb manipulation, as well as transitioning between manipulation modes. The proposed design performs similarly to an additional arm while weighing and costing 5 times less per manipulator and enabling the completion of tasks requiring 2 manipulators.},
howpublished = {In Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Flash: Fast and Light Motion Prediction for Autonomous Driving with Bayesian Inverse Planning and Learned Motion Profiles Proceedings Article
Morris Antonello, Mihai Dobre, Stefano V. Albrecht, John Redford, Subramanian Ramamoorthy
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2022, ISBN: 978-1-6654-7927-1, (Work done at FiveAI).
@inproceedings{antonello2022flashfastlightmotion,
title = {Flash: Fast and Light Motion Prediction for Autonomous Driving with Bayesian Inverse Planning and Learned Motion Profiles},
author = {Morris Antonello and Mihai Dobre and Stefano V. Albrecht and John Redford and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9981347
https://arxiv.org/abs/2203.08251},
doi = {10.1109/IROS47612.2022.9981347},
isbn = {978-1-6654-7927-1},
year = {2022},
date = {2022-12-26},
urldate = {2022-12-26},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
publisher = {IEEE},
abstract = {Motion prediction of road users in traffic scenes is critical for autonomous driving systems that must take safe and robust decisions in complex dynamic environments. We present a novel motion prediction system for autonomous driving. Our system is based on the Bayesian inverse planning framework, which efficiently orchestrates map-based goal extraction, a classical control-based trajectory generator and a mixture of experts collection of light-weight neural networks specialised in motion profile prediction. In contrast to many alternative methods, this modularity helps isolate performance factors and better interpret results, without compromising performance. This system addresses multiple aspects of interest, namely multi-modality, motion profile uncertainty and trajectory physical feasibility. We report on several experiments with the popular highway dataset NGSIM, demonstrating state-of-the-art performance in terms of trajectory error. We also perform a detailed analysis of our system's components, along with experiments that stratify the data based on behaviours, such as change-lane versus follow-lane, to provide insights into the challenges in this domain. Finally, we present a qualitative analysis to show other benefits of our approach, such as the ability to interpret the outputs.},
howpublished = {In Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022. [Work done at Five]},
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning physics-informed simulation models for soft robotic manipulation: A case study with dielectric elastomer actuators Proceedings Article
Manu Lahariya, Craig Innes, Chris Develder, Subramanian Ramamoorthy
In: IIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022, ISBN: 978-1-6654-7927-1.
@inproceedings{lahariya2022learningphysicsinformedsimulationmodels,
title = {Learning physics-informed simulation models for soft robotic manipulation: A case study with dielectric elastomer actuators},
author = {Manu Lahariya and Craig Innes and Chris Develder and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9981373
https://arxiv.org/abs/2202.12977},
doi = {10.1109/IROS47612.2022.9981373},
isbn = {978-1-6654-7927-1},
year = {2022},
date = {2022-12-26},
urldate = {2022-01-01},
booktitle = {IIEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
abstract = {Soft actuators offer a safe, adaptable approach to tasks like gentle grasping and dexterous manipulation. Creating accurate models to control such systems however is challenging due to the complex physics of deformable materials. Accurate Finite Element Method (FEM) models incur prohibitive computational complexity for closed-loop use. Using a differentiable simulator is an attractive alternative, but their applicability to soft actuators and deformable materials remains underexplored. This paper presents a framework that combines the advantages of both. We learn a differentiable model consisting of a material properties neural network and an analytical dynamics model of the remainder of the manipulation task. This physics-informed model is trained using data generated from FEM, and can be used for closed-loop control and inference. We evaluate our framework on a dielectric elastomer actuator (DEA) coin-pulling task. We simulate the task of using DEA to pull a coin along a surface with frictional contact, using FEM, and evaluate the physics-informed model for simulation, control, and inference. Our model attains < 5% simulation error compared to FEM, and we use it as the basis for an MPC controller that requires fewer iterations to converge than model-free actor-critic, PD, and heuristic policies.},
howpublished = {In Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2022},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Risk-Driven Design of Perception Systems Proceedings Article
Anthony L. Corso, Sydney M. Katz, Craig Innes, Xin Du, Subramanian Ramamoorthy, Mykel J. Kochenderfer
In: Conference on Neural Information Processing Systems (NeurIPS), pp. 9894–9906, 2022.
@inproceedings{corso2022riskdrivendesignperceptionsystems,
title = {Risk-Driven Design of Perception Systems},
author = {Anthony L. Corso and Sydney M. Katz and Craig Innes and Xin Du and Subramanian Ramamoorthy and Mykel J. Kochenderfer},
url = {https://proceedings.neurips.cc/paper_files/paper/2022/file/40739b3bb584c117b3e2f418d17f63a1-Paper-Conference.pdf
https://arxiv.org/abs/2205.10677},
year = {2022},
date = {2022-12-01},
urldate = {2022-01-01},
booktitle = {Conference on Neural Information Processing Systems (NeurIPS)},
volume = {35},
pages = {9894--9906},
abstract = {Modern autonomous systems rely on perception modules to process complex sensor measurements into state estimates. These estimates are then passed to a controller, which uses them to make safety-critical decisions. It is therefore important that we design perception systems to minimize errors that reduce the overall safety of the system. We develop a risk-driven approach to designing perception systems that accounts for the effect of perceptual errors on the performance of the fully-integrated, closed-loop system. We formulate a risk function to quantify the effect of a given perceptual error on overall safety, and show how we can use it to design safer perception systems by including a risk-dependent term in the loss function and generating training data in risk-sensitive regions. We evaluate our techniques on a realistic vision-based aircraft detect and avoid application and show that risk-driven design reduces collision risk by 37% over a baseline system.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Formation Control for UAVs Using a Flux Guided Approach Journal Article
John Hartley, Hubert P. H. Shum, Edmond S. L. Ho, He Wang, Subramanian Ramamoorthy
In: Expert Systems with Applications, vol. 205, pp. 117665, 2022, ISBN: 0957-4174.
@article{hartley2022formationcontroluavsusing,
title = {Formation Control for UAVs Using a Flux Guided Approach},
author = {John Hartley and Hubert P. H. Shum and Edmond S. L. Ho and He Wang and Subramanian Ramamoorthy},
url = {https://www.sciencedirect.com/science/article/pii/S0957417422009666
https://arxiv.org/abs/2103.09184
https://github.com/jasminium/formationcontrolui},
doi = {/10.1016/j.eswa.2022.117665},
isbn = {0957-4174},
year = {2022},
date = {2022-11-01},
urldate = {2022-06-03},
journal = {Expert Systems with Applications},
volume = {205},
pages = {117665},
abstract = {Existing studies on formation control for unmanned aerial vehicles (UAV) have not considered encircling targets where an optimum coverage of the target is required at all times. Such coverage plays a critical role in many real-world applications such as tracking hostile UAVs. This paper proposes a new path planning approach called the Flux Guided (FG) method, which generates collision-free trajectories for multiple UAVs while maximising the coverage of target(s). Our method enables UAVs to track directly toward a target whilst maintaining maximum coverage. Furthermore, multiple scattered targets can be tracked by scaling the formation during flight. FG is highly scalable since it only requires communication between sub-set of UAVs on the open boundary of the formation's surface. Experimental results further validate that FG generates UAV trajectories 1.5× shorter than previous work and that trajectory planning for 9 leader/follower UAVs to surround a target in two different scenarios only requires 0.52 seconds and 0.88 seconds, respectively. The resulting trajectories are suitable for robotic controls after time-optimal parameterisation; we demonstrate this using a 3d dynamic particle system that tracks the desired trajectories using a PID controller.},
howpublished = {IEEE Robotics and Automation Letters (RA-L), 2022. Presented at the IEEE International Conference on Robotics and Automation (ICRA), 2022},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Line-scan Confocal Endomicroscopy for Rapid Digital Histology of Early Breast Cancer Proceedings Article
Khushi Vyas, Ahmed Ezzat, Martin Asenov, Manish Chauhan, Subramanian Ramamoorthy, Animesh Jha, Daniel Leff
In: Conference on Lasers and Electro-Optics (CLEO), IEEE, 2022, ISBN: 978-1-957171-05-0.
@inproceedings{Vyas:22,
title = {Line-scan Confocal Endomicroscopy for Rapid Digital Histology of Early Breast Cancer},
author = {Khushi Vyas and Ahmed Ezzat and Martin Asenov and Manish Chauhan and Subramanian Ramamoorthy and Animesh Jha and Daniel Leff},
url = {https://ieeexplore.ieee.org/document/9890516
https://opg.optica.org/abstract.cfm?URI=CLEO_AT-2022-ATh4I.7},
doi = {10.1364/CLEO_AT.2022.ATh4I.7},
isbn = {978-1-957171-05-0},
year = {2022},
date = {2022-09-23},
urldate = {2022-01-01},
booktitle = {Conference on Lasers and Electro-Optics (CLEO)},
journal = {Conference on Lasers and Electro-Optics},
publisher = {IEEE},
abstract = {We present a high-speed line-scan confocal laser endomicroscope, which enables digital histopathology of freshly excised un-fixed breast tissue specimens in real-time.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Perspectives on the system-level design of a safe autonomous driving stack Journal Article
Majd Hawasly, Jonathan Sadeghi, Morris Antonello, Stefano V. Albrecht, John Redford, Subramanian Ramamoorthy
In: AI Communications, Special Issue on Multi-agent Systems Research in the UK, vol. 35, no. 4, pp. 269-270, 2022, (Work done at FiveAI).
@article{doi:10.3233/AIC-229003,
title = {Perspectives on the system-level design of a safe autonomous driving stack},
author = {Majd Hawasly and Jonathan Sadeghi and Morris Antonello and Stefano V. Albrecht and John Redford and Subramanian Ramamoorthy},
url = {https://journals.sagepub.com/doi/abs/10.3233/AIC-229003},
doi = {10.3233/AIC-229003},
year = {2022},
date = {2022-09-02},
urldate = {2022-01-01},
journal = {AI Communications, Special Issue on Multi-agent Systems Research in the UK},
volume = {35},
number = {4},
pages = {269-270},
abstract = {Achieving safe and robust autonomy is the key bottleneck on the path towards broader adoption of autonomous vehicles technology. This motivates going beyond extrinsic metrics such as miles between disengagement, and calls for approaches that embody safety by design. In this paper, we address some aspects of this challenge, with emphasis on issues of motion planning and prediction. We do this through description of novel approaches taken to solving selected sub-problems within an autonomous driving stack, in the process introducing the design philosophy being adopted within Five. This includes safe-by-design planning, interpretable as well as verifiable prediction, and modelling of perception errors to enable effective sim-to-real and real-to-sim transfer within the testing pipeline of a realistic autonomous system.},
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Automated Testing With Temporal Logic Specifications for Robotic Controllers Using Adaptive Experiment Design Proceedings Article
Craig Innes, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2022, ISBN: 978-1-7281-9681-7.
@inproceedings{innes2022automatedtestingtemporallogic,
title = {Automated Testing With Temporal Logic Specifications for Robotic Controllers Using Adaptive Experiment Design},
author = {Craig Innes and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9811579
https://arxiv.org/abs/2109.08071},
doi = {10.1109/ICRA46639.2022.9811579},
isbn = {978-1-7281-9681-7},
year = {2022},
date = {2022-07-12},
urldate = {2022-01-01},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {Many robot control scenarios involve assessing system robustness against a task specification. If either the controller or environment are composed of "black-box" components with unknown dynamics, we cannot rely on formal verification to assess our system. Assessing robustness via exhaustive testing is also often infeasible if the space of environments is large compared to experiment cost.
Given limited budget, we provide a method to choose experiment inputs which give greatest insight into system performance against a given specification across the domain. By combining smooth robustness metrics for signal temporal logic with techniques from adaptive experiment design, our method chooses the most informative experimental inputs by incrementally constructing a surrogate model of the specification robustness. This model then chooses the next experiment to be in an area where there is either high prediction error or uncertainty.
Our experiments show how this adaptive experimental design technique results in sample-efficient descriptions of system robustness. Further, we show how to use the model built via the experiment design process to assess the behaviour of a data-driven control system under domain shift.},
howpublished = {In Proc. IEEE International Conference on Robotics and Automation (ICRA), 2022.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Given limited budget, we provide a method to choose experiment inputs which give greatest insight into system performance against a given specification across the domain. By combining smooth robustness metrics for signal temporal logic with techniques from adaptive experiment design, our method chooses the most informative experimental inputs by incrementally constructing a surrogate model of the specification robustness. This model then chooses the next experiment to be in an area where there is either high prediction error or uncertainty.
Our experiments show how this adaptive experimental design technique results in sample-efficient descriptions of system robustness. Further, we show how to use the model built via the experiment design process to assess the behaviour of a data-driven control system under domain shift.
Architectures for online simulation-based inference applied to robot motion planning PhD Thesis
Martin Asenov
University of Edinburgh, 2022.
@phdthesis{nokey,
title = {Architectures for online simulation-based inference applied to robot motion planning},
author = {Martin Asenov},
url = {http://dx.doi.org/10.7488/era/2339},
year = {2022},
date = {2022-06-13},
urldate = {2022-06-13},
school = {University of Edinburgh},
abstract = {Robotic systems have enjoyed significant adoption in industrial and field applications in structured environments, where clear specifications of the task and observations are available. Deploying robots in unstructured and dynamic environments remains a challenge, being addressed through emerging advances in machine learning. The key open issues in this area include the difficulty of achieving coverage of all factors of variation in the domain of interest, satisfying safety constraints, etc. One tool that has played a crucial role in addressing these issues is simulation - which is used to generate data, and sometimes as a world representation within the decision-making loop. When physical simulation modules are used in this way, a number of computational problems arise. Firstly, a suitable simulation representation and fidelity is required for the specific task of interest. Secondly, we need to perform parameter inference of physical variables being used in the simulation models. Thirdly, there is the need for data assimilation, which must be achieved in real-time if the resulting model is to be used within the online decision-making loop. These are the motivating problems for this thesis. In the first section of the thesis, we tackle the inference problem with respect to a fluid simulation model, where a sensorised UAV performs path planning with the objective of acquiring data including gas concentration/identity and IMU-based wind estimation readings. The task for the UAV is to localise the source of a gas leak, while accommodating the subsequent dispersion of the gas in windy conditions. We present a formulation of this problem that allows us to perform online and real-time active inference efficiently through problem-specific simplifications. In the second section of the thesis, we explore the problem of robot motion planning when the true state is not fully observable, and actions influence how much of the state is subsequently observed. This is motivated by the practical problem of a robot performing suction in the surgical automation setting. The objective is the efficient removal of liquid while respecting a safety constraint - to not touch the underlying tissue if possible. If the problem were represented in full generality, as one of planning under uncertainty and hidden state, it could be hard to find computationally efficient solutions. Once again, we make problem-specific simplifications. Crucially, instead of reasoning in general about fluid flows and arbitrary surfaces, we exploit the observations that the decision can be informed by the contour tree skeleton of the volume, and the configurations in which the fluid would come to rest if unperturbed. This allows us to address the problem as one of iterative shortest path computation, whose costs are informed by a model estimating the shape of the underlying surface. In the third and final section of the thesis, we propose a model for real-time parameter estimation directly from raw pixel observations. Through the use of a Variational Recurrent Neural Network model, where the latent space is further structured by penalising for fit to data from a physical simulation, we devise an efficient online inference scheme. This is first shown in the context of a representative dynamic manipulation task for a robot. This task involves reasoning about a bouncing ball that it must catch – using as input the raw video from an environment-mounted camera and accommodating noise and variations in the object and environmental conditions. We then show that the same architecture lends itself to solving inference problems involving more complex dynamics, by applying this to measurement inversion of ultrafast X-Ray scattering data to infer molecular geometry.},
howpublished = {Edinburgh Research Archive (ERA)},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Robust Learning from Observation with Model Misspecification Proceedings Article
Luca Viano, Yu-Ting Huang, Parameswaran Kamalaruban, Craig Innes, Subramanian Ramamoorthy, Adrian Weller
In: International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pp. 1337-1375, 2022, ISBN: 9781450392136.
@inproceedings{viano2022robustlearningobservationmodel,
title = {Robust Learning from Observation with Model Misspecification},
author = {Luca Viano and Yu-Ting Huang and Parameswaran Kamalaruban and Craig Innes and Subramanian Ramamoorthy and Adrian Weller},
url = {https://dl.acm.org/doi/10.5555/3535850.3535999
https://arxiv.org/abs/2202.06003},
isbn = {9781450392136},
year = {2022},
date = {2022-05-09},
urldate = {2022-01-01},
booktitle = {International Conference on Autonomous Agents and Multiagent Systems (AAMAS)},
pages = {1337-1375},
abstract = {Imitation learning (IL) is a popular paradigm for training policies in robotic systems when specifying the reward function is difficult. However, despite the success of IL algorithms, they impose the somewhat unrealistic requirement that the expert demonstrations must come from the same domain in which a new imitator policy is to be learned. We consider a practical setting, where (i) state-only expert demonstrations from the real (deployment) environment are given to the learner, (ii) the imitation learner policy is trained in a simulation (training) environment whose transition dynamics is slightly different from the real environment, and (iii) the learner does not have any access to the real environment during the training phase beyond the batch of demonstrations given. Most of the current IL methods, such as generative adversarial imitation learning and its state-only variants, fail to imitate the optimal expert behavior under the above setting. By leveraging insights from the Robust reinforcement learning (RL) literature and building on recent adversarial imitation approaches, we propose a robust IL algorithm to learn policies that can effectively transfer to the real environment without fine-tuning. Furthermore, we empirically demonstrate on continuous-control benchmarks that our method outperforms the state-of-the-art state-only IL method in terms of the zero-shot transfer performance in the real environment and robust performance under different testing conditions.},
howpublished = {In Proc. International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2022},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Preliminary findings of confocal laser endomicroscopy and Raman spectroscopy in human breast tissue characterisation Journal Article
Ahmed Ezzat, Khushi Vyas, Manish Chauhan, Martin Asenov, Anna Silvanto, Animesh Jha, Subramanian Ramamoorthy, Alexander Thompson, Daniel Richard Leff
In: European Journal of Surgical Oncology, vol. 48, no. 5, pp. e221–e222, 2022, ISSN: 0748-7983.
@article{Ezzat2022,
title = {Preliminary findings of confocal laser endomicroscopy and Raman spectroscopy in human breast tissue characterisation},
author = {Ahmed Ezzat and Khushi Vyas and Manish Chauhan and Martin Asenov and Anna Silvanto and Animesh Jha and Subramanian Ramamoorthy and Alexander Thompson and Daniel Richard Leff},
doi = {10.1016/j.ejso.2022.03.144},
issn = {0748-7983},
year = {2022},
date = {2022-05-00},
urldate = {2022-05-00},
journal = {European Journal of Surgical Oncology},
volume = {48},
number = {5},
pages = {e221--e222},
publisher = {Elsevier BV},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Portable confocal endomicroscopy for ductal feature characterization: Toward margin assessment in breast-conserving surgery Proceedings Article
Ahmed Ezzat, Khushi Vyas, Martin Asenov, Manish Chauhan, Animesh Jha, Subramanian Ramamoorthy, Daniel Leff
In: The American Society of Breast Surgeons Official Proceedings, pp. s190–s191, 2022, (The 23rd Annual Meeting of The American Society of Breast Surgeons, 2022, ASBrS 2022 ; Conference date: 06-04-2022 Through 10-04-2022).
@inproceedings{2755e73bfdcd4264842d50b57c34da9a,
title = {Portable confocal endomicroscopy for ductal feature characterization: Toward margin assessment in breast-conserving surgery},
author = {Ahmed Ezzat and Khushi Vyas and Martin Asenov and Manish Chauhan and Animesh Jha and Subramanian Ramamoorthy and Daniel Leff},
doi = {10.1245/s10434-022-11703-0},
year = {2022},
date = {2022-04-06},
urldate = {2022-04-06},
booktitle = {The American Society of Breast Surgeons Official Proceedings},
volume = {XXIII},
pages = {s190–s191},
note = {The 23rd Annual Meeting of The American Society of Breast Surgeons, 2022, ASBrS 2022 ; Conference date: 06-04-2022 Through 10-04-2022},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Residual Learning From Demonstration: Adapting DMPs for Contact-Rich Manipulation Journal Article
Todor Davchev, Kevin Sebastian Luck, Michael Burke, Franziska Meier, Stefan Schaal, Subramanian Ramamoorthy
In: IEEE Robotics and Automation Letters (RA-L), vol. 7, no. 2, pp. 4488–4495, 2022, ISSN: 2377-3774, ( Presented at ICRA 2022).
@article{Davchev_2022,
title = {Residual Learning From Demonstration: Adapting DMPs for Contact-Rich Manipulation},
author = {Todor Davchev and Kevin Sebastian Luck and Michael Burke and Franziska Meier and Stefan Schaal and Subramanian Ramamoorthy},
url = {http://dx.doi.org/10.1109/LRA.2022.3150024
https://sites.google.com/view/rlfd/
https://www.youtube.com/watch?v=Hn5sdjlAMQU},
doi = {10.1109/lra.2022.3150024},
issn = {2377-3774},
year = {2022},
date = {2022-02-10},
urldate = {2022-04-01},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {7},
number = {2},
pages = {4488–4495},
publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
abstract = {Manipulation skills involving contact and friction are inherent to many robotics tasks. Using the class of motor primitives for peg-in-hole like insertions, we study how robots can learn such skills. Dynamic Movement Primitives (DMP) are a popular way of extracting such policies through behaviour cloning (BC) but can struggle in the context of insertion. Policy adaptation strategies such as residual learning can help improve the overall performance of policies in the context of contact-rich manipulation. However, it is not clear how to best do this with DMPs. As a result, we consider several possible ways for adapting a DMP formulation and propose ``residual Learning from Demonstration`` (rLfD), a framework that combines DMPs with Reinforcement Learning (RL) to learn a residual correction policy. Our evaluations suggest that applying residual learning directly in task space and operating on the full pose of the robot can significantly improve the overall performance of DMPs. We show that rLfD offers a gentle to the joints solution that improves the task success and generalisation of DMPs rb{and enables transfer to different geometries and frictions through few-shot task adaptation}. The proposed framework is evaluated on a set of tasks. A simulated robot and a physical robot have to successfully insert pegs, gears and plugs into their respective sockets.},
note = { Presented at ICRA 2022},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Vision Checklist: Towards Testable Error Analysis of Image Models to Help System Designers Interrogate Model Capabilities Working paper
Xin Du, Benedicte Legastelois, Bhargavi Ganesh, Ajitha Rajan, Hana Chockler, Vaishak Belle, Stuart Anderson, Subramanian Ramamoorthy
2022.
@workingpaper{du2022visionchecklisttestableerror,
title = {Vision Checklist: Towards Testable Error Analysis of Image Models to Help System Designers Interrogate Model Capabilities},
author = {Xin Du and Benedicte Legastelois and Bhargavi Ganesh and Ajitha Rajan and Hana Chockler and Vaishak Belle and Stuart Anderson and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2201.11674},
year = {2022},
date = {2022-01-01},
urldate = {2022-01-01},
abstract = {Using large pre-trained models for image recognition tasks is becoming increasingly common owing to the well acknowledged success of recent models like vision transformers and other CNN-based models like VGG and Resnet. The high accuracy of these models on benchmark tasks has translated into their practical use across many domains including safety-critical applications like autonomous driving and medical diagnostics. Despite their widespread use, image models have been shown to be fragile to changes in the operating environment, bringing their robustness into question. There is an urgent need for methods that systematically characterise and quantify the capabilities of these models to help designers understand and provide guarantees about their safety and robustness. In this paper, we propose Vision Checklist, a framework aimed at interrogating the capabilities of a model in order to produce a report that can be used by a system designer for robustness evaluations. This framework proposes a set of perturbation operations that can be applied on the underlying data to generate test samples of different types. The perturbations reflect potential changes in operating environments, and interrogate various properties ranging from the strictly quantitative to more qualitative. Our framework is evaluated on multiple datasets like Tinyimagenet, CIFAR10, CIFAR100 and Camelyon17 and for models like ViT and Resnet. Our Vision Checklist proposes a specific set of evaluations that can be integrated into the previously proposed concept of a model card. Robustness evaluations like our checklist will be crucial in future safety evaluations of visual perception modules, and be useful for a wide range of stakeholders including designers, deployers, and regulators involved in the certification of these systems. Source code of Vision Checklist would be open for public use.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Robust Artificial Intelligence for Neurorobotics Book
Subramanian Ramamoorthy, Joe Hays, Christian Tetzlaff (Ed.)
Frontiers Media SA, 2022, ISBN: 9782889742462.
@book{2022,
title = {Robust Artificial Intelligence for Neurorobotics},
editor = {Subramanian Ramamoorthy and Joe Hays and Christian Tetzlaff},
doi = {10.3389/978-2-88974-246-2},
isbn = {9782889742462},
year = {2022},
date = {2022-00-00},
urldate = {2022-00-00},
publisher = {Frontiers Media SA},
abstract = {Neural computing is a powerful paradigm that has revolutionized machine learning. Building from early roots in the study of adaptive behavior and attempts to understand information processing in parallel and distributed neural architectures, modern neural networks have convincingly demonstrated successes in numerous areas—transforming the practice of computer vision, natural language processing, and even computational biology.
Applications in robotics bring stringent constraints on size, weight and power constraints (SWaP), which challenge the developers of these technologies in new ways. Indeed, these requirements take us back to the roots of the field of neural computing, forcing us to ask how it could be that the human brain achieves with as little as 12 watts of power what seems to require entire server farms with state of the art computational and numerical methods. Likewise, even lowly insects demonstrate a degree of adaptivity and resilience that still defy easy explanation or computational replication.
In this Research Topic, we have compiled the latest research addressing several aspects of these broadly defined challenge questions.},
keywords = {},
pubstate = {published},
tppubtype = {book}
}
Applications in robotics bring stringent constraints on size, weight and power constraints (SWaP), which challenge the developers of these technologies in new ways. Indeed, these requirements take us back to the roots of the field of neural computing, forcing us to ask how it could be that the human brain achieves with as little as 12 watts of power what seems to require entire server farms with state of the art computational and numerical methods. Likewise, even lowly insects demonstrate a degree of adaptivity and resilience that still defy easy explanation or computational replication.
In this Research Topic, we have compiled the latest research addressing several aspects of these broadly defined challenge questions.
2021
PILOT: Efficient Planning by Imitation Learning and Optimisation for Safe Autonomous Driving Proceedings Article
Henry Pulver, Francisco Eiras, Ludovico Carozza, Majd Hawasly, Stefano V. Albrecht, Subramanian Ramamoorthy
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021, ISBN: 978-1-6654-1714-3, (Also presented at CVPR Workshop on Autonomous Driving: Perception, Prediction and Planning, 2021. Work done at FiveAI.).
@inproceedings{pulver2021pilotefficientplanningimitation,
title = {PILOT: Efficient Planning by Imitation Learning and Optimisation for Safe Autonomous Driving},
author = {Henry Pulver and Francisco Eiras and Ludovico Carozza and Majd Hawasly and Stefano V. Albrecht and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9636862
https://arxiv.org/abs/2011.00509},
doi = {10.1109/IROS51168.2021.9636862},
isbn = {978-1-6654-1714-3},
year = {2021},
date = {2021-12-16},
urldate = {2021-12-16},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
abstract = {Achieving a proper balance between planning quality, safety and efficiency is a major challenge for autonomous driving. Optimisation-based motion planners are capable of producing safe, smooth and comfortable plans, but often at the cost of runtime efficiency. On the other hand, naïvely deploying trajectories produced by efficient-to-run deep imitation learning approaches might risk compromising safety. In this paper, we present PILOT a planning framework that comprises an imitation neural network followed by an efficient optimiser that actively rectifies the network’s plan, guaranteeing fulfilment of safety and comfort requirements. The objective of the efficient optimiser is the same as the objective of an expensive-to-run optimisation-based planning system that the neural network is trained offline to imitate. This efficient optimiser provides a key layer of online protection from learning failures or deficiency in out-of-distribution situations that might compromise safety or comfort. Using a state-of-the-art, runtime-intensive optimisation-based method as the expert, we demonstrate in simulated autonomous driving experiments in CARLA that PILOT achieves a seven-fold reduction in runtime when compared to the expert it imitates without sacrificing planning quality.},
note = {Also presented at CVPR Workshop on Autonomous Driving: Perception, Prediction and Planning, 2021. Work done at FiveAI.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Attainment Regions in Feature-Parameter Space for High-Level Debugging in Autonomous Robots Proceedings Article
Simón C. Smith, Subramanian Ramamoorthy
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021.
@inproceedings{smith2021attainmentregionsfeatureparameterspace,
title = {Attainment Regions in Feature-Parameter Space for High-Level Debugging in Autonomous Robots},
author = {Simón C. Smith and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9636336
https://arxiv.org/abs/2108.03150},
doi = {10.1109/IROS51168.2021.9636336},
year = {2021},
date = {2021-12-16},
urldate = {2021-01-01},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
publisher = {IEEE},
abstract = {Understanding a controller's performance in different scenarios is crucial for robots that are going to be deployed in safety-critical tasks. If we do not have a model of the dynamics of the world, which is often the case in complex domains, we may need to approximate a performance function of the robot based on its interaction with the environment. Such a performance function gives us insights into the behaviour of the robot, allowing us to fine-tune the controller with manual interventions. In high-dimensionality systems, where the actionstate space is large, fine-tuning a controller is non-trivial. To overcome this problem, we propose a performance function whose domain is defined by external features and parameters of the controller. Attainment regions are defined over such a domain defined by feature-parameter pairs, and serve the purpose of enabling prediction of successful execution of the task. The use of the feature-parameter space -in contrast to the action-state space- allows us to adapt, explain and finetune the controller over a simpler (i.e., lower dimensional space). When the robot successfully executes the task, we use the attainment regions to gain insights into the limits of the controller, and its robustness. When the robot fails to execute the task, we use the regions to debug the controller and find adaptive and counterfactual changes to the solutions. Another advantage of this approach is that we can generalise through the use of Gaussian processes regression of the performance function in the high-dimensional space. To test our approach, we demonstrate learning an approximation to the performance function in simulation, with a mobile robot traversing different terrain conditions. Then, with a sample-efficient method, we propagate the attainment regions to a physical robot in a similar environment.},
howpublished = {In Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Interpretable Goal Recognition in the Presence of Occluded Factors for Autonomous Vehicles Proceedings Article
Josiah P. Hanna, Arrasy Rahman, Elliot Fosong, Francisco Eiras, Mihai Dobre, John Redford, Subramanian Ramamoorthy, Stefano V. Albrecht
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021, ISBN: 978-1-6654-1714-3, (Work done at FiveAI).
@inproceedings{hanna2021interpretablegoalrecognitionpresence,
title = {Interpretable Goal Recognition in the Presence of Occluded Factors for Autonomous Vehicles},
author = {Josiah P. Hanna and Arrasy Rahman and Elliot Fosong and Francisco Eiras and Mihai Dobre and John Redford and Subramanian Ramamoorthy and Stefano V. Albrecht},
url = {https://ieeexplore.ieee.org/abstract/document/9635903
https://arxiv.org/abs/2108.02530},
doi = {10.1109/IROS51168.2021.9635903},
isbn = {978-1-6654-1714-3},
year = {2021},
date = {2021-12-16},
urldate = {2021-12-16},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
publisher = {IEEE},
abstract = {Recognising the goals or intentions of observed vehicles is a key step towards predicting the long-term future behaviour of other agents in an autonomous driving scenario. When there are unseen obstacles or occluded vehicles in a scenario, goal recognition may be confounded by the effects of these unseen entities on the behaviour of observed vehicles. Existing prediction algorithms that assume rational behaviour with respect to inferred goals may fail to make accurate long-horizon predictions because they ignore the possibility that the behaviour is influenced by such unseen entities. We introduce the Goal and Occluded Factor Inference (GOFI) algorithm which bases inference on inverse-planning to jointly infer a probabilistic belief over goals and potential occluded factors. We then show how these beliefs can be integrated into Monte Carlo Tree Search (MCTS). We demonstrate that jointly inferring goals and occluded factors leads to more accurate beliefs with respect to the true world state and allows an agent to safely navigate several scenarios where other baselines take unsafe actions leading to collisions.},
howpublished = {In Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021. [Work done at FiveAI]},
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Robust physical parameter identification through global linearisation of system dynamics Workshop
Yordan Hristov, Subramanian Ramamoorthy
2021, (NeurIPS Workshop on Safe and Robust Control of Uncertain Systems , SafeRL 2021).
@workshop{e94427e8c3af47e98d58a746ce1c98cc,
title = {Robust physical parameter identification through global linearisation of system dynamics},
author = {Yordan Hristov and Subramanian Ramamoorthy},
url = {https://www.pure.ed.ac.uk/ws/files/460667630/Robust_Physical_HRISTOV_DOA20102021_AFV.pdf
https://sites.google.com/view/safe-robust-control/home},
year = {2021},
date = {2021-12-13},
urldate = {2021-12-13},
pages = {1–8},
abstract = {Using neural networks to learn dynamical models from data is a powerful technique but can also suffer from problems like brittleness, overfitting and lack of safety guarantees. These problems are particularly acute when a distributional shift is observed in the dynamics of the same underlying system, caused by different values of its physical parameters. Casting the learned models in the framework of linear systems enhances our abilities to analyse and control them. However, it does not stop them from failing when having to extrapolate outside of their training distribution. By globally linearising the system’s dynamics, using ideas from Deep Koopman Theory, and combining them with off-the-shelf estimation techniques like Kalman filtering, we demonstrate a way of knowing when and what the model does not know and respectively how much we can trust its predictions. We showcase our ideas and results in the context of different rod lengths of the classical pendulum control environment.},
howpublished = {In Proc. NeurIPS Workshop on Safe and Robust Control of Uncertain Systems, 2021.},
note = {NeurIPS Workshop on Safe and Robust Control of Uncertain Systems , SafeRL 2021},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Composing diverse policies for long horizon tasks PhD Thesis
Daniel Angelov
University of Edinburgh, 2021.
@phdthesis{Angelov2021,
title = {Composing diverse policies for long horizon tasks},
author = {Daniel Angelov},
doi = {10.7488/era/1568},
year = {2021},
date = {2021-11-30},
urldate = {2021-11-30},
school = {University of Edinburgh},
abstract = {Humans utilise a large diversity of control and reasoning methods to solve different robot manipulation and motion planning tasks. This diversity should be reflected in the strategies used by robots in the same domains. In current practice involving sequential decision making over long horizons, even when the formulation is a hierarchical one, it is common for all elements of this hierarchy to adopt the same representation. For instance, the overall policy might be a switching model over Markov Decision Processes (MDPs) or local feedback control laws. This may not be well suited to a variety of naturally observed behaviours. For instance, when picking up a book from a crowded shelf, we naturally switch between goal-directed reaching, tactile regrasping, sliding the book until it is comfortably off an edge and then once again goal-directed pick and place. It is rare that a single representational form adequately captures this diversity, even in such a seemingly simple task. When the robot must learn or adapt policies from experience, this poses significant challenges. The mis-match between the representational choices and the diversity of task types can result in a significant (sometimes exponential) increase in complexity with respect to time, observation and state-space dimensionality and other attributes. These and other factors can make the learning of such tasks in a “tabula rasa” setting extremely difficult. However, if we were willing to adopt a multi-representational framing of the problem, and allow for some of these constituent modules to be learned in different ways (some from expert demonstration, some by trial and error, and perhaps some being controllers designed from first principles in model-based formulations) then the problem becomes much more tractable. The core hypothesis we explore is that it is possible to devise such learning methods, and that they significantly outperform conventional alternatives on robotic manipulation tasks of interest. In the first part of this thesis, we present a framework for sequentially composing diverse policies facilitating the solution of long-horizon tasks. We rely on demonstrations to provide a quick, not necessarily expert and optimal, way to convey the desired outcome. We model the similarity to demonstrated states in a Goal Scoring Estimator model. We show in a real robot experiment the benefits of diverse policies relying on their own strong inductive biases to efficiently solve different aspects of the task, through sequencing by the Goal Scoring Estimator model. Next, we demonstrate how we can elicit policy structure through causal analysis and task structure through more efficient demonstrations involving interventions. This allows us to alter the manner of execution of a particular policy to match a desired learned user specification. Building a surrogate model of the demonstrator gives us the ability to causally reason about different aspects of the policy and which parts of that policy are salient. We can observe how intervening in the world by placing additional symbols impacts the validity of the original plan. Finally, observing that ‘static’ imitation learning datasets can be limiting if we are aiming to create more robust policies, we present the Learning from Inverse Intervention framework. This allows the robot to simultaneously learn a policy while interacting with the demonstrator. In this interaction, the robot intervenes when there is little information gain and pushes the demonstrator to explore more informative areas even as the demonstration is being performed in real-time. This interaction brings the added benefit of drawing out information about the importance of different regions of the task. We verify the salience by visually inspecting samples from a generative model and by crafting plans that test these hypothetical areas. These methods give us the ability to use demonstrations of a task, to build policies for salient targets, to alter their manner of execution and inspect to understand the causal structure, and to sequence them to solve novel tasks.},
howpublished = {Edinburgh Research Archive (ERA)},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Efficient methods and architectures for deep neural network sequence models PhD Thesis
Emmanuel Kahembwe Mbabazi
University of Edinburgh, 2021.
@phdthesis{mbabazi2021,
title = {Efficient methods and architectures for deep neural network sequence models},
author = {Emmanuel Kahembwe Mbabazi},
doi = {10.7488/era/1710},
year = {2021},
date = {2021-11-30},
urldate = {2021-11-30},
school = {University of Edinburgh},
abstract = {The recent resurgence of neural networks, termed "Deep Learning", has led to a reinvigoration of the artificial intelligence research field and all related sub-fields; from robotics and vision to natural language processing and understanding. In the last decade, this field has seen incredible breakthroughs, primarily driven by improvements to computing capability that have allowed for ever larger neural network architectures. The key driving force behind this resurgence has been the graphics processing unit (GPU) and as deep neural networks (DNNs) get ever larger, efficiency has become a bottleneck issue. Even with ample amounts of GPUs and significant financial resources, the state-of-the-art neural network models and methods are out of reach for most scientists. The significance of this challenge is brought to bare when attempting to use DNNs on video, the most consumed form of data and media. Modelling high dimensional data such as video is already computationally expensive and challenging even with small neural networks.
With the 2020 Coronavirus pandemic, production and consumption of video has greatly increased as the global business population moves to working and interacting online. The low cost of video production and transmission is quickly making it the most common medium of digital communication for socially distanced humans. Video is also often the cheapest and most detailed source of information relied upon in fields such as robotics; for driverless cars, drones and teleoperated machines. As such, being able to efficiently model such data is of paramount importance to the field of AI.
In this thesis, we tackle the issue of efficient modelling of complex high dimensional sequential data such as video and language. We address this problem on two fronts, computational efficiency and algorithmic efficiency.
On the computational front, we propose a design methodology that significantly lowers the cost of video modelling tasks while improving performance. To enable this, we bring to bare the tools of hessian analysis in the most comprehensive analysis of generative video models to date.
We then go on to tackle sequential modelling from an algorithmic efficiency perspective. We propose methods that use the temporal dynamics of sequential data to improve modelling performance post-training. We highlight the new capabilities enabled when optimization is not restricted to training scenarios and conjecture that intelligent systems should never stop training. In a collaborative effort, we propose similar approaches for natural language modelling. To conclude, we demonstrate with a single commodity GPU, that our proposed methods and architectures realise state-of-the-art results often surpassing the performance of models trained on hundreds of GPUs at significant financial cost.
},
howpublished = {Edinburgh Research Archive (ERA)},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
With the 2020 Coronavirus pandemic, production and consumption of video has greatly increased as the global business population moves to working and interacting online. The low cost of video production and transmission is quickly making it the most common medium of digital communication for socially distanced humans. Video is also often the cheapest and most detailed source of information relied upon in fields such as robotics; for driverless cars, drones and teleoperated machines. As such, being able to efficiently model such data is of paramount importance to the field of AI.
In this thesis, we tackle the issue of efficient modelling of complex high dimensional sequential data such as video and language. We address this problem on two fronts, computational efficiency and algorithmic efficiency.
On the computational front, we propose a design methodology that significantly lowers the cost of video modelling tasks while improving performance. To enable this, we bring to bare the tools of hessian analysis in the most comprehensive analysis of generative video models to date.
We then go on to tackle sequential modelling from an algorithmic efficiency perspective. We propose methods that use the temporal dynamics of sequential data to improve modelling performance post-training. We highlight the new capabilities enabled when optimization is not restricted to training scenarios and conjecture that intelligent systems should never stop training. In a collaborative effort, we propose similar approaches for natural language modelling. To conclude, we demonstrate with a single commodity GPU, that our proposed methods and architectures realise state-of-the-art results often surpassing the performance of models trained on hundreds of GPUs at significant financial cost.
ProbRobScene: A Probabilistic Specification Language for 3D Robotic Manipulation Environments Proceedings Article
Craig Innes, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2021, ISBN: 978-1-7281-9077-8.
@inproceedings{innes2021probrobsceneprobabilisticspecificationlanguage,
title = {ProbRobScene: A Probabilistic Specification Language for 3D Robotic Manipulation Environments},
author = {Craig Innes and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9562038
https://arxiv.org/abs/2011.01126},
doi = {10.1109/ICRA48506.2021.9562038},
isbn = {978-1-7281-9077-8},
year = {2021},
date = {2021-10-18},
urldate = {2021-01-01},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
publisher = {IEEE},
abstract = {Robotic control tasks are often first run in simulation for the purposes of verification, debugging and data augmentation. Many methods exist to specify what task a robot must complete, but few exist to specify what range of environments a user expects such tasks to be achieved in. ProbRobScene is a probabilistic specification language for describing robotic manipulation environments. Using the language, a user need only specify the relational constraints that must hold between objects in a scene. ProbRobScene will then automatically generate scenes which conform to this specification. By combining aspects of probabilistic programming languages and convex geometry, we provide a method for sampling this space of possible environments efficiently. We demonstrate the usefulness of our language by using it to debug a robotic controller in a tabletop robot manipulation environment.},
howpublished = {In Proc. IEEE International Conference on Robotics and Automation (ICRA), 2021.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Active Altruism Learning and Information Sufficiency for Autonomous Driving Working paper
Jack Geary, Henry Gouk, Subramanian Ramamoorthy
2021.
@workingpaper{2110.04580,
title = {Active Altruism Learning and Information Sufficiency for Autonomous Driving},
author = {Jack Geary and Henry Gouk and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2110.04580},
year = {2021},
date = {2021-10-09},
urldate = {2021-01-01},
abstract = {Safe interaction between vehicles requires the ability to choose actions that reveal the preferences of the other vehicles. Since exploratory actions often do not directly contribute to their objective, an interactive vehicle must also able to identify when it is appropriate to perform them. In this work we demonstrate how Active Learning methods can be used to incentivise an autonomous vehicle (AV) to choose actions that reveal information about the altruistic inclinations of another vehicle. We identify a property, Information Sufficiency, that a reward function should have in order to keep exploration from unnecessarily interfering with the pursuit of an objective. We empirically demonstrate that reward functions that do not have Information Sufficiency are prone to inadequate exploration, which can result in sub-optimal behaviour. We propose a reward definition that has Information Sufficiency, and show that it facilitates an AV choosing exploratory actions to estimate altruistic tendency, whilst also compensating for the possibility of conflicting beliefs between vehicles.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Building Affordance Relations for Robotic Agents - A Review Proceedings Article
Paola Ardón, Èric Pairet, Katrin S. Lohan, Subramanian Ramamoorthy, Ron P. A. Petrick
In: Proceedings of Joint Conference on Artificial Intelligence (IJCAI), pp. 4302–4311, 2021.
@inproceedings{Ardón2021,
title = {Building Affordance Relations for Robotic Agents - A Review},
author = {Paola Ardón and Èric Pairet and Katrin S. Lohan and Subramanian Ramamoorthy and Ron P. A. Petrick},
url = {https://arxiv.org/abs/2105.06706
https://paolaardon.github.io/affordance_in_robotic_tasks_survey/},
doi = {10.24963/ijcai.2021/590},
year = {2021},
date = {2021-08-01},
urldate = {2021-08-00},
booktitle = {Proceedings of Joint Conference on Artificial Intelligence (IJCAI)},
pages = {4302--4311},
abstract = {Affordances describe the possibilities for an agent to perform actions with an object. While the significance of the affordance concept has been previously studied from varied perspectives, such as psychology and cognitive science, these approaches are not always sufficient to enable direct transfer, in the sense of implementations, to artificial intelligence (AI)-based systems and robotics. However, many efforts have been made to pragmatically employ the concept of affordances, as it represents great potential for AI agents to effectively bridge perception to action. In this survey, we review and find common ground amongst different strategies that use the concept of affordances within robotic tasks, and build on these methods to provide guidance for including affordances as a mechanism to improve autonomy. To this end, we outline common design choices for building representations of affordance relations, and their implications on the generalisation capabilities of an agent when facing previously unseen scenarios. Finally, we identify and discuss a range of interesting research directions involving affordances that have the potential to improve the capabilities of an AI agent.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Interactive robot learning with human alignment PhD Thesis
Yordan Hristov
2021.
@phdthesis{nokey,
title = {Interactive robot learning with human alignment},
author = {Yordan Hristov},
url = {http://dx.doi.org/10.7488/era/1219},
year = {2021},
date = {2021-07-31},
urldate = {2021-07-31},
institution = {University of Edinburgh},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Learning Time-Invariant Reward Functions through Model-Based Inverse Reinforcement Learning Working paper
Todor Davchev, Sarah Bechtle, Subramanian Ramamoorthy, Franziska Meier
2021.
@workingpaper{davchev2021learningtimeinvariantrewardfunctions,
title = {Learning Time-Invariant Reward Functions through Model-Based Inverse Reinforcement Learning},
author = {Todor Davchev and Sarah Bechtle and Subramanian Ramamoorthy and Franziska Meier},
url = {https://arxiv.org/abs/2107.03186},
year = {2021},
date = {2021-07-07},
urldate = {2021-01-01},
abstract = {Inverse reinforcement learning is a paradigm motivated by the goal of learning general reward functions from demonstrated behaviours. Yet the notion of generality for learnt costs is often evaluated in terms of robustness to various spatial perturbations only, assuming deployment at fixed speeds of execution. However, this is impractical in the context of robotics and building, time-invariant solutions is of crucial importance. In this work, we propose a formulation that allows us to 1) vary the length of execution by learning time-invariant costs, and 2) relax the temporal alignment requirements for learning from demonstration. We apply our method to two different types of cost formulations and evaluate their performance in the context of learning reward functions for simulated placement and peg in hole tasks executed on a 7DoF Kuka IIWA arm. Our results show that our approach enables learning temporally invariant rewards from misaligned demonstration that can also generalise spatially to out of distribution tasks.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
A Two-Stage Optimization-based Motion Planner for Safe Urban Driving Journal Article
Francisco Eiras, Majd Hawasly, Stefano V. Albrecht, Subramanian Ramamoorthy
In: IEEE Transactions on Robotics (T-RO), vol. 38, pp. 822-834, 2021, ISBN: 1552-3098, (Work done at FiveAI).
@article{eiras2021twostageoptimizationbasedmotionplanner,
title = {A Two-Stage Optimization-based Motion Planner for Safe Urban Driving},
author = {Francisco Eiras and Majd Hawasly and Stefano V. Albrecht and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9473026
https://arxiv.org/abs/2002.02215
https://www.five.ai/a-two-stage-optimization-based-motion-planner-for-safe-urban-driving},
doi = {10.1109/TRO.2021.3088009},
isbn = {1552-3098},
year = {2021},
date = {2021-07-02},
urldate = {2021-01-01},
booktitle = {IEEE Transactions on Robotics (T-RO)
},
journal = {IEEE Transactions on Robotics (T-RO)},
volume = {38},
pages = {822-834},
abstract = {Recent road trials have shown that guaranteeing the safety of driving decisions is essential for the wider adoption of autonomous vehicle technology. One promising direction is to pose safety requirements as planning constraints in nonlinear, non-convex optimization problems of motion synthesis. However, many implementations of this approach are limited by uncertain convergence and local optimality of the solutions achieved, affecting overall robustness. To improve upon these issues, we propose a novel two-stage optimization framework: in the first stage, we find a solution to a Mixed-Integer Linear Programming (MILP) formulation of the motion synthesis problem, the output of which initializes a second Nonlinear Programming (NLP) stage. The MILP stage enforces hard constraints of safety and road rule compliance generating a solution in the right subspace, while the NLP stage refines the solution within the safety bounds for feasibility and smoothness. We demonstrate the effectiveness of our framework via simulated experiments of complex urban driving scenarios, outperforming a state-of-the-art baseline in metrics of convergence, comfort and progress.},
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Resolving Conflict in Decision-Making for Autonomous Driving Proceedings Article
Jack Geary, Subramanian Ramamoorthy, Henry Gouk
In: Robotics: Science and Systems (RSS), 2021.
@inproceedings{geary2021resolvingconflictdecisionmakingautonomous,
title = {Resolving Conflict in Decision-Making for Autonomous Driving},
author = {Jack Geary and Subramanian Ramamoorthy and Henry Gouk},
url = {https://www.roboticsproceedings.org/rss17/p049.html
https://arxiv.org/abs/2009.06394},
doi = {10.15607/RSS.2021.XVII.049},
year = {2021},
date = {2021-07-01},
urldate = {2021-07-01},
booktitle = {Robotics: Science and Systems (RSS)},
abstract = {Recent work on decision making and planning for autonomous driving has made use of game theoretic methods to model interaction between agents. We demonstrate that methods based on the Stackelberg game formulation of this problem are susceptible to an issue that we refer to as conflict. Our results show that when conflict occurs, it causes sub-optimal and potentially dangerous behaviour. In response, we develop a theoretical framework for analysing the extent to which such methods are impacted by conflict, and apply this framework to several existing approaches modelling interaction between agents. Moreover, we propose Augmented Altruism, a novel approach to modelling interaction between players in a Stackelberg game, and show that it is less prone to conflict than previous techniques. Finally, we investigate the behavioural assumptions that underpin our approach by performing experiments with human participants. The results show that our model explains human decision-making better than existing game-theoretic models of interactive driving.},
howpublished = {Robotics: Science and Systems (R:SS), 2021},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Automatic Synthesis of Experiment Designs from Probabilistic Environment Specifications Proceedings Article
Craig Innes, Yordan Hristov, Georgios Kamaras, Subramanian Ramamoorthy
In: 10th Workshop on Synthesis (SYNT 2021), Co-located with International Conference on Computer Aided Verification (CAV), 2021.
@inproceedings{innes2021automaticsynthesisexperimentdesigns,
title = {Automatic Synthesis of Experiment Designs from Probabilistic Environment Specifications},
author = {Craig Innes and Yordan Hristov and Georgios Kamaras and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2107.00093},
year = {2021},
date = {2021-06-21},
urldate = {2021-01-01},
booktitle = {10th Workshop on Synthesis (SYNT 2021), Co-located with International Conference on Computer Aided Verification (CAV)},
abstract = {This paper presents an extension to the probabilistic programming language ProbRobScene, allowing users to automatically synthesize uniform experiment designs directly from environment specifications. We demonstrate its effectiveness on a number of environment specification snippets from tabletop manipulation, and show that our method generates reliably low-discrepancy designs.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Expectations and Perceptions of Healthcare Professionals for Robot Deployment in Hospital Environments During the COVID-19 Pandemic Journal Article
Sergio D. Sierra Marín, Daniel Gomez-Vargas, Nathalia Céspedes, Marcela Múnera, Flavio Roberti, Patricio Barria, Subramanian Ramamoorthy, Marcelo Becker, Ricardo Carelli, Carlos A. Cifuentes
In: Frontiers in Robotics and AI, vol. 8, 2021, ISSN: 2296-9144.
@article{SierraMarín2021,
title = {Expectations and Perceptions of Healthcare Professionals for Robot Deployment in Hospital Environments During the COVID-19 Pandemic},
author = {Sergio D. Sierra Marín and Daniel Gomez-Vargas and Nathalia Céspedes and Marcela Múnera and Flavio Roberti and Patricio Barria and Subramanian Ramamoorthy and Marcelo Becker and Ricardo Carelli and Carlos A. Cifuentes},
doi = {10.3389/frobt.2021.612746},
issn = {2296-9144},
year = {2021},
date = {2021-06-02},
urldate = {2021-06-02},
journal = {Frontiers in Robotics and AI},
volume = {8},
publisher = {Frontiers Media SA},
abstract = {Several challenges to guarantee medical care have been exposed during the current COVID-19 pandemic. Although the literature has shown some robotics applications to overcome the potential hazards and risks in hospital environments, the implementation of those developments is limited, and few studies measure the perception and the acceptance of clinicians. This work presents the design and implementation of several perception questionnaires to assess healthcare provider's level of acceptance and education toward robotics for COVID-19 control in clinic scenarios. Specifically, 41 healthcare professionals satisfactorily accomplished the surveys, exhibiting a low level of knowledge about robotics applications in this scenario. Likewise, the surveys revealed that the fear of being replaced by robots remains in the medical community. In the Colombian context, 82.9% of participants indicated a positive perception concerning the development and implementation of robotics in clinic environments. Finally, in general terms, the participants exhibited a positive attitude toward using robots and recommended them to be used in the current panorama.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Interpretable Goal-based Prediction and Planning for Autonomous Driving Proceedings Article
Stefano V. Albrecht, Cillian Brewitt, John Wilhelm, Balint Gyevnar, Francisco Eiras, Mihai Dobre, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), IEEE, 2021, ISBN: 978-1-7281-9077-8, (Work done at FiveAI).
@inproceedings{albrecht2021interpretablegoalbasedpredictionplanning,
title = {Interpretable Goal-based Prediction and Planning for Autonomous Driving},
author = {Stefano V. Albrecht and Cillian Brewitt and John Wilhelm and Balint Gyevnar and Francisco Eiras and Mihai Dobre and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2002.02277
https://www.five.ai/igp2},
doi = {10.1109/ICRA48506.2021.9560849},
isbn = {978-1-7281-9077-8},
year = {2021},
date = {2021-05-31},
urldate = {2021-01-01},
booktitle = { IEEE International Conference on Robotics and Automation (ICRA)},
publisher = {IEEE},
abstract = {We propose an integrated prediction and planning system for autonomous driving which uses rational inverse planning to recognise the goals of other vehicles. Goal recognition informs a Monte Carlo Tree Search (MCTS) algorithm to plan optimal maneuvers for the ego vehicle. Inverse planning and MCTS utilise a shared set of defined maneuvers and macro actions to construct plans which are explainable by means of rationality principles. Evaluation in simulations of urban driving scenarios demonstrate the system's ability to robustly recognise the goals of other vehicles, enabling our vehicle to exploit non-trivial opportunities to significantly reduce driving times. In each scenario, we extract intuitive explanations for the predictions which justify the system's decisions.},
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning from Demonstration with Weakly Supervised Disentanglement Proceedings Article
Yordan Hristov, Subramanian Ramamoorthy
In: International Conference on Learning Representations (ICLR), 2021.
@inproceedings{hristov2021learningdemonstrationweaklysupervised,
title = {Learning from Demonstration with Weakly Supervised Disentanglement},
author = {Yordan Hristov and Subramanian Ramamoorthy},
url = {https://openreview.net/forum?id=Ldau9eHU-qO
https://arxiv.org/abs/2006.09107
https://sites.google.com/view/weak-label-lfd
https://www.youtube.com/watch?v=2s5EC_HjH0Q},
year = {2021},
date = {2021-05-05},
urldate = {2021-05-05},
booktitle = {International Conference on Learning Representations (ICLR)},
abstract = {Robotic manipulation tasks, such as wiping with a soft sponge, require control from multiple rich sensory modalities. Human-robot interaction, aimed at teaching robots, is difficult in this setting as there is potential for mismatch between human and machine comprehension of the rich data streams. We treat the task of interpretable learning from demonstration as an optimisation problem over a probabilistic generative model. To account for the high-dimensionality of the data, a high-capacity neural network is chosen to represent the model. The latent variables in this model are explicitly aligned with high-level notions and concepts that are manifested in a set of demonstrations. We show that such alignment is best achieved through the use of labels from the end user, in an appropriately restricted vocabulary, in contrast to the conventional approach of the designer picking a prior over the latent variables. Our approach is evaluated in the context of two table-top robot manipulation tasks performed by a PR2 robot -- that of dabbing liquids with a sponge (forcefully pressing a sponge and moving it along a surface) and pouring between different containers. The robot provides visual information, arm joint positions and arm joint efforts. },
howpublished = {International Conference on Learning Representations(ICLR)},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning data association without data association: An EM approach to neural assignment prediction Working paper
Michael Burke, Subramanian Ramamoorthy
2021.
@workingpaper{burke2021learningdataassociationdata,
title = {Learning data association without data association: An EM approach to neural assignment prediction},
author = {Michael Burke and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2105.00369},
year = {2021},
date = {2021-05-02},
urldate = {2021-01-01},
abstract = {Data association is a fundamental component of effective multi-object tracking. Current approaches to data-association tend to frame this as an assignment problem relying on gating and distance-based cost matrices, or offset the challenge of data association to a problem of tracking by detection. The latter is typically formulated as a supervised learning problem, and requires labelling information about tracked object identities to train a model for object recognition. This paper introduces an expectation maximisation approach to train neural models for data association, which does not require labelling information. Here, a Sinkhorn network is trained to predict assignment matrices that maximise the marginal likelihood of trajectory observations. Importantly, networks trained using the proposed approach can be re-used in downstream tracking applications.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Learning Structured Representations of Spatial and Interactive Dynamics for Trajectory Prediction in Crowded Scenes Journal Article
Todor Davchev, Michael Burke, Subramanian Ramamoorthy
In: IEEE Robotics and Automation Letters (RA-L), vol. 6, iss. 2, no. 2, pp. 707–714, 2021, ISSN: 2377-3774.
@article{Davchev_2021,
title = {Learning Structured Representations of Spatial and Interactive Dynamics for Trajectory Prediction in Crowded Scenes},
author = {Todor Davchev and Michael Burke and Subramanian Ramamoorthy},
doi = {10.1109/lra.2020.3047778},
issn = {2377-3774},
year = {2021},
date = {2021-04-01},
urldate = {2021-04-01},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {6},
number = {2},
issue = {2},
pages = {707–714},
publisher = {Institute of Electrical and Electronics Engineers (IEEE)},
abstract = {Context plays a significant role in the generation of motion for dynamic agents in interactive environments. This work proposes a modular method that utilises a learned model of the environment for motion prediction. This modularity explicitly allows for unsupervised adaptation of trajectory prediction models to unseen environments and new tasks by relying on unlabelled image data only. We model both the spatial and dynamic aspects of a given environment alongside the per agent motions. This results in more informed motion prediction and allows for performance comparable to the state-of-the-art. We highlight the model's prediction capability using a benchmark pedestrian prediction problem and a robot manipulation task and show that we can transfer the predictor across these tasks in a completely unsupervised way. The proposed approach allows for robust and label efficient forward modelling, and relaxes the need for full model re-training in new environments.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Self-Explainable Robots in Remote Environments Proceedings Article
Francisco J. Chiyah Garcia, Simón C. Smith, José Lopes, Subramanian Ramamoorthy, Helen Hastie
In: Companion of the 2021 ACM/IEEE International Conference on Human-Robot Interaction, pp. 662–664, ACM, 2021.
@inproceedings{ChiyahGarcia2021,
title = {Self-Explainable Robots in Remote Environments},
author = {Francisco J. Chiyah Garcia and Simón C. Smith and José Lopes and Subramanian Ramamoorthy and Helen Hastie},
url = {https://dl.acm.org/doi/10.1145/3434074.3447275
https://www.youtube.com/watch?v=w1jniAuIdMs},
doi = {10.1145/3434074.3447275},
year = {2021},
date = {2021-03-08},
urldate = {2021-03-08},
booktitle = {Companion of the 2021 ACM/IEEE International Conference on Human-Robot Interaction},
pages = {662--664},
publisher = {ACM},
abstract = {As robots and autonomous systems become more adept at handling complex scenarios, their underlying mechanisms also become increasingly complex and opaque. This lack of transparency can give rise to unverifiable behaviours, limiting the use of robots in a number of applications including high-stakes scenarios, e.g. self-driving cars or first responders. In this paper and accompanying video, we present a system that learns from demonstrations to inspect areas in a remote environment and to explain robot behaviour. Using semi-supervised learning, the robot is able to inspect an offshore platform autonomously, whilst explaining its decision process both through both image-based and natural language-based interfaces.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Action sequencing using visual permutations Journal Article
Michael Burke, Kartic Subr, Subramanian Ramamoorthy
In: IEEE Robotics and Automation Letters (RA-L), pp. 1745-1752, 2021, ISBN: 2377-3766, (Presented at ICRA 2021).
@article{burke2021actionsequencingusingvisual,
title = {Action sequencing using visual permutations},
author = {Michael Burke and Kartic Subr and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9354890
https://arxiv.org/abs/2008.01156
https://www.youtube.com/watch?v=F86hHFQDGW4},
doi = {10.1109/LRA.2021.3059630},
isbn = {2377-3766},
year = {2021},
date = {2021-02-16},
urldate = {2021-02-16},
booktitle = {IEEE Robotics and Automation Letters },
journal = {IEEE Robotics and Automation Letters (RA-L)},
pages = {1745-1752},
abstract = {Humans can easily reason about the sequence of high level actions needed to complete tasks, but it is particularly difficult to instil this ability in robots trained from relatively few examples. This work considers the task of neural action sequencing conditioned on a single reference visual state. This task is extremely challenging as it is not only subject to the significant combinatorial complexity that arises from large action sets, but also requires a model that can perform some form of symbol grounding, mapping high dimensional input data to actions, while reasoning about action relationships. This paper takes a permutation perspective and argues that action sequencing benefits from the ability to reason about both permutations and ordering concepts. Empirical analysis shows that neural models trained with latent permutations outperform standard neural architectures in constrained action sequencing tasks. Results also show that action sequencing using visual permutations is an effective mechanism to initialise and speed up traditional planning techniques and successfully scales to far greater action set sizes than models considered previously.},
howpublished = {IEEE Robotics and Automation Letters, 2021. Presented at the IEEE International Conference on Robotics and Automation (ICRA), 2021},
note = {Presented at ICRA 2021},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Stir to Pour: Efficient Calibration of Liquid Properties for Pouring Actions Proceedings Article
Tatiana Lopez Guevara, Rita Pucci, Nicholas Taylor, Michael U Gutmann, Ram Ramamoorthy, Kartic Subr
In: 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Institute of Electrical and Electronics Engineers, United States, 2021, ISBN: 978-1-7281-6213-3, (2020 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2020 ; Conference date: 25-10-2020 Through 29-10-2020).
@inproceedings{60ff9ec2c0e44fdda1741f1734f4c4f7,
title = {Stir to Pour: Efficient Calibration of Liquid Properties for Pouring Actions},
author = {Tatiana Lopez Guevara and Rita Pucci and Nicholas Taylor and Michael U Gutmann and Ram Ramamoorthy and Kartic Subr},
url = {https://www.iros2020.org/index.html
https://www.youtube.com/watch?v=iu5iaBc-rWc
https://rad.inf.ed.ac.uk/data/publications/2020/lopez-guevara2020stir.pdf},
doi = {10.1109/IROS45743.2020.9340852},
isbn = {978-1-7281-6213-3},
year = {2021},
date = {2021-02-10},
urldate = {2021-02-10},
booktitle = {2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
publisher = {Institute of Electrical and Electronics Engineers},
address = {United States},
abstract = {Humans use simple probing actions to develop intuition about the physical behaviour of common objects. Such intuition is particularly useful for adaptive estimation of favourable manipulation strategies of those objects in novel contexts. For example, observing the effect of tilt on a transparent bottle containing an unknown liquid provides clues on how the liquid might be poured. It is desirable to equip general-purpose robotic systems with this capability because it is inevitable that they will encounter novel objects and scenarios. In this paper, we teach a robot to use a simple, specified probing strategy – stirring with a stick – to reduce spillage while pouring unknown liquids. In the probing step, we continuously observe the effects of a real robot stirring a liquid, while simultaneously tuning the parameters to a model (simulator) until the two outputs are in agreement. We obtain optimal simulation parameters, characterising the unknown liquid, via a Bayesian Optimiser that minimises the discrepancy between real and simulated outcomes. Then, we optimise the pouring policy conditioning on the optimal simulation parameters determined via stirring. We show that using stirring as a probing strategy results in reduced spillage for three qualitatively different liquids when executed on a UR10 Robot, compared to probing via pouring. Finally, we provide quantitative insights into the reason for stirring being a suitable calibration task for pouring – a step towards automatic discovery of probing strategies.},
note = {2020 IEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2020 ; Conference date: 25-10-2020 Through 29-10-2020},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Self-Assessment of Grasp Affordance Transfer Proceedings Article
Paola Ardón, Èric Pairet, Ronald P. A. Petrick, Subramanian Ramamoorthy, Katrin S. Lohan
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), IEEE, 2021, ISBN: 978-1-7281-6212-6.
@inproceedings{ardón2020selfassessmentgraspaffordancetransfer,
title = {Self-Assessment of Grasp Affordance Transfer},
author = {Paola Ardón and Èric Pairet and Ronald P. A. Petrick and Subramanian Ramamoorthy and Katrin S. Lohan},
url = {https://ieeexplore.ieee.org/document/9340841
https://arxiv.org/abs/2007.02132
https://www.youtube.com/watch?v=nCCc3_Rk8Ks},
doi = { 10.1109/IROS45743.2020.9340841},
isbn = {978-1-7281-6212-6},
year = {2021},
date = {2021-02-10},
urldate = {2021-02-10},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
publisher = {IEEE},
abstract = {Reasoning about object grasp affordances allows an autonomous agent to estimate the most suitable grasp to execute a task. While current approaches for estimating grasp affordances are effective, their prediction is driven by hypotheses on visual features rather than an indicator of a proposal's suitability for an affordance task. Consequently, these works cannot guarantee any level of performance when executing a task and, in fact, not even ensure successful task completion. In this work, we present a pipeline for SAGAT based on prior experiences. We visually detect a grasp affordance region to extract multiple grasp affordance configuration candidates. Using these candidates, we forward simulate the outcome of executing the affordance task to analyse the relation between task outcome and grasp candidates. The relations are ranked by performance success with a heuristic confidence function and used to build a library of affordance task experiences. The library is later queried to perform one-shot transfer estimation of the best grasp configuration on new objects. Experimental evaluation shows that our method exhibits a significant performance improvement up to 11.7% against current state-of-the-art methods on grasp affordance detection. Experiments on a PR2 robotic platform demonstrate our method's highly reliable deployability to deal with real-world task affordance problems.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Affordance-Aware Handovers with Human Arm Mobility Constraints Journal Article
Paola Ardón, Maria E. Cabrera, Èric Pairet, Ronald P. A. Petrick, Subramanian Ramamoorthy, Katrin S. Lohan, Maya Cakmak
In: IEEE Robotics and Automation Letters (RA-L), vol. 6, no. 2, pp. 3136-3143, 2021, (Presented atICRA 2021 and its Workshop on Learning for Caregiving Robots in which the article received best workshop presentation award).
@article{ardón2021affordanceawarehandovershumanarm,
title = {Affordance-Aware Handovers with Human Arm Mobility Constraints},
author = {Paola Ardón and Maria E. Cabrera and Èric Pairet and Ronald P. A. Petrick and Subramanian Ramamoorthy and Katrin S. Lohan and Maya Cakmak},
url = {https://ieeexplore.ieee.org/document/9366406
https://arxiv.org/abs/2010.15436
https://www.youtube.com/watch?v=oJIeMWeH9mk},
doi = {10.1109/LRA.2021.3062808},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {6},
number = {2},
pages = {3136-3143},
abstract = {Reasoning about object handover configurations allows an assistive agent to estimate the appropriateness of handover for a receiver with different arm mobility capacities. While there are existing approaches for estimating the effectiveness of handovers, their findings are limited to users without arm mobility impairments and to specific objects. Therefore, current state-of-the-art approaches are unable to hand over novel objects to receivers with different arm mobility capacities. We propose a method that generalises handover behaviours to previously unseen objects, subject to the constraint of a user's arm mobility levels and the task context. We propose a heuristic-guided hierarchically optimised cost whose optimisation adapts object configurations for receivers with low arm mobility. },
howpublished = {IEEE Robotics and Automation Letters, 2021. Presented at the IEEE International Conference on Robotics and Automation (ICRA) and ICRA 2021 Workshop on Learning for Caregiving Robots, 2021},
note = {Presented atICRA 2021 and its Workshop on Learning for Caregiving Robots in which the article received best workshop presentation award},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Applications and Techniques for Fast Machine Learning in Science Journal Article
Allison McCarn Deiana, Nhan Tran, Joshua Agar, Michaela Blott, Giuseppe Di Guglielmo, Javier Duarte, Philip Harris, Scott Hauck, Mia Liu, Mark S. Neubauer, Jennifer Ngadiuba, Seda Ogrenci-Memik, Maurizio Pierini, Thea Aarrestad, Steffen Bahr, Jurgen Becker, Anne-Sophie Berthold, Richard J. Bonventre, Tomas E. Muller Bravo, Markus Diefenthaler, Zhen Dong, Nick Fritzsche, Amir Gholami, Ekaterina Govorkova, Kyle J Hazelwood, Christian Herwig, Babar Khan, Sehoon Kim, Thomas Klijnsma, Yaling Liu, Kin Ho Lo, Tri Nguyen, Gianantonio Pezzullo, Seyedramin Rasoulinezhad, Ryan A. Rivera, Kate Scholberg, Justin Selig, Sougata Sen, Dmitri Strukov, William Tang, Savannah Thais, Kai Lukas Unger, Ricardo Vilalta, Belinavon Krosigk, Thomas K. Warburton, Maria Acosta Flechas, Anthony Aportela, Thomas Calvet, Leonardo Cristella, Daniel Diaz, Caterina Doglioni, Maria Domenica Galati, Elham E Khoda, Farah Fahim, Davide Giri, Benjamin Hawks, Duc Hoang, Burt Holzman, Shih-Chieh Hsu, Sergo Jindariani, Iris Johnson, Raghav Kansal, Ryan Kastner, Erik Katsavounidis, Jeffrey Krupa, Pan Li, Sandeep Madireddy, Ethan Marx, Patrick McCormack, Andres Meza, Jovan Mitrevski, Mohammed Attia Mohammed, Farouk Mokhtar, Eric Moreno, Srishti Nagu, Rohin Narayan, Noah Palladino, Zhiqiang Que, Sang Eon Park, Subramanian Ramamoorthy, Dylan Rankin, Simon Rothman, Ashish Sharma, Sioni Summers, Pietro Vischia, Jean-Roch Vlimant, Olivia Weng
In: Front. Big Data 5, 787421 (2022), 2021.
@article{2110.13041,
title = {Applications and Techniques for Fast Machine Learning in Science},
author = {Allison McCarn Deiana and Nhan Tran and Joshua Agar and Michaela Blott and Giuseppe Di Guglielmo and Javier Duarte and Philip Harris and Scott Hauck and Mia Liu and Mark S. Neubauer and Jennifer Ngadiuba and Seda Ogrenci-Memik and Maurizio Pierini and Thea Aarrestad and Steffen Bahr and Jurgen Becker and Anne-Sophie Berthold and Richard J. Bonventre and Tomas E. Muller Bravo and Markus Diefenthaler and Zhen Dong and Nick Fritzsche and Amir Gholami and Ekaterina Govorkova and Kyle J Hazelwood and Christian Herwig and Babar Khan and Sehoon Kim and Thomas Klijnsma and Yaling Liu and Kin Ho Lo and Tri Nguyen and Gianantonio Pezzullo and Seyedramin Rasoulinezhad and Ryan A. Rivera and Kate Scholberg and Justin Selig and Sougata Sen and Dmitri Strukov and William Tang and Savannah Thais and Kai Lukas Unger and Ricardo Vilalta and Belinavon Krosigk and Thomas K. Warburton and Maria Acosta Flechas and Anthony Aportela and Thomas Calvet and Leonardo Cristella and Daniel Diaz and Caterina Doglioni and Maria Domenica Galati and Elham E Khoda and Farah Fahim and Davide Giri and Benjamin Hawks and Duc Hoang and Burt Holzman and Shih-Chieh Hsu and Sergo Jindariani and Iris Johnson and Raghav Kansal and Ryan Kastner and Erik Katsavounidis and Jeffrey Krupa and Pan Li and Sandeep Madireddy and Ethan Marx and Patrick McCormack and Andres Meza and Jovan Mitrevski and Mohammed Attia Mohammed and Farouk Mokhtar and Eric Moreno and Srishti Nagu and Rohin Narayan and Noah Palladino and Zhiqiang Que and Sang Eon Park and Subramanian Ramamoorthy and Dylan Rankin and Simon Rothman and Ashish Sharma and Sioni Summers and Pietro Vischia and Jean-Roch Vlimant and Olivia Weng},
doi = {10.3389/fdata.2022.787421},
year = {2021},
date = {2021-01-01},
urldate = {2021-01-01},
journal = {Front. Big Data 5, 787421 (2022)},
abstract = {In this community review report, we discuss applications and techniques for fast machine learning (ML) in science -- the concept of integrating power ML methods into the real-time experimental data processing loop to accelerate scientific discovery. The material for the report builds on two workshops held by the Fast ML for Science community and covers three main areas: applications for fast ML across a number of scientific domains; techniques for training and implementing performant and resource-efficient ML algorithms; and computing architectures, platforms, and technologies for deploying these algorithms. We also present overlapping challenges across the multiple scientific domains where common solutions can be found. This community report is intended to give plenty of examples and inspiration for scientific discovery through integrated and accelerated ML solutions. This is followed by a high-level overview and organization of technical advances, including an abundance of pointers to source material, which can enable these breakthroughs.},
howpublished = {Front. Big Data 5, 787421 (2022)},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2020
Counterfactual Explanation and Causal Inference in Service of Robustness in Robot Control Proceedings Article
Simón C. Smith, Subramanian Ramamoorthy
In: IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob), IEEE, 2020.
@inproceedings{smith2020counterfactualexplanationcausalinference,
title = {Counterfactual Explanation and Causal Inference in Service of Robustness in Robot Control},
author = {Simón C. Smith and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/9278061
https://arxiv.org/abs/2009.08856},
doi = {10.1109/ICDL-EpiRob48136.2020.9278061},
year = {2020},
date = {2020-12-14},
urldate = {2020-01-01},
booktitle = {IEEE International Conference on Development and Learning and Epigenetic Robotics (ICDL-EpiRob)},
publisher = {IEEE},
abstract = {We propose an architecture for training generative models of counterfactual conditionals of the form, 'can we modify event A to cause B instead of C?', motivated by applications in robot control. Using an 'adversarial training' paradigm, an image-based deep neural network model is trained to produce small and realistic modifications to an original image in order to cause user-defined effects. These modifications can be used in the design process of image-based robust control - to determine the ability of the controller to return to a working regime by modifications in the input space, rather than by adaptation. In contrast to conventional control design approaches, where robustness is quantified in terms of the ability to reject noise, we explore the space of counterfactuals that might cause a certain requirement to be violated, thus proposing an alternative model that might be more expressive in certain robotics applications. So, we propose the generation of counterfactuals as an approach to explanation of black-box models and the envisioning of potential movement paths in autonomous robotic control. Firstly, we demonstrate this approach in a set of classification tasks, using the well known MNIST and CelebFaces Attributes datasets. Then, addressing multi-dimensional regression, we demonstrate our approach in a reaching task with a physical robot, and in a navigation task with a robot in a digital twin simulation.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Inversion of Ultrafast X-ray Scattering with Dynamics Constraints Workshop
Martin Asenov, Nikola Zotev, Subramanian Ramamoorthy, Adam Kirrander
NeurIPS Workshop on Machine Learning and the Physical Sciences, 2020.
@workshop{f13c9da1ae6a42be88d7fa2e34e696ae,
title = {Inversion of Ultrafast X-ray Scattering with Dynamics Constraints},
author = {Martin Asenov and Nikola Zotev and Subramanian Ramamoorthy and Adam Kirrander},
url = {https://www.research.ed.ac.uk/en/publications/inversion-of-ultrafast-x-ray-scattering-with-dynamics-constraints
https://ml4physicalsciences.github.io/2020/
https://sites.google.com/view/mlscattering/
},
year = {2020},
date = {2020-12-11},
urldate = {2020-12-11},
booktitle = {NeurIPS Workshop on Machine Learning and the Physical Sciences},
abstract = {Studying molecular transformations on an ultrafast time-scale is vital for understanding chemical reactivity, but interpreting the relevant experiments is challenging because chemical dynamics need to be inferred from an indirect and often incomplete sequence of observations. We propose a method that uses a form of variational recurrent neural network to tackle the problem of inversion of time resolved X-ray scattering from molecules recorded on a detector. By training our model with molecular trajectories, dynamic correlations and constraints associated with molecular motion can be learned. We show this leads to a more accurate inversion from a detector signal to atom-atom distances, compared to the traditional frame-by-frame approach.},
howpublished = {In Proc. NeurIPS Workshop on Machine Learning and the Physical Sciences},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Simón C. Smith, Subramanian Ramamoorthy
vol. 319, Electronic Proceedings in Theoretical Computer Science Open Publishing Association, 2020.
@workshop{EPTCS319.7,
title = {Semi-supervised Learning From Demonstration Through Program Synthesis: An Inspection Robot Case Study},
author = {Simón C. Smith and Subramanian Ramamoorthy},
editor = {Rafael C. Cardoso and Angelo Ferrando and Daniela Briola and Claudio Menghi and Tobias Ahlbrecht},
url = {https://cgi.cse.unsw.edu.au/~eptcs/paper.cgi?AREA2020.7
https://arxiv.org/abs/2007.12500},
doi = {10.4204/EPTCS.319.7},
year = {2020},
date = {2020-12-04},
urldate = {2020-12-04},
volume = {319},
pages = {81-101},
publisher = {Open Publishing Association},
series = {Electronic Proceedings in Theoretical Computer Science},
abstract = {Semi-supervised learning improves the performance of supervised machine learning by leveraging methods from unsupervised learning to extract information not explicitly available in the labels. Through the design of a system that enables a robot to learn inspection strategies from a human operator, we present a hybrid semi-supervised system capable of learning interpretable and verifiable models from demonstrations. The system induces a controller program by learning from immersive demonstrations using sequential importance sampling. These visual servo controllers are parametrised by proportional gains and are visually verifiable through observation of the position of the robot in the environment. Clustering and effective particle size filtering allows the system to discover goals in the state space. These goals are used to label the original demonstration for end-to-end learning of behavioural models. The behavioural models are used for autonomous model predictive control and scrutinised for explanations. We implement causal sensitivity analysis to identify salient objects and generate counterfactual conditional explanations. These features enable decision making interpretation and post hoc discovery of the causes of a failure. The proposed system expands on previous approaches to program synthesis by incorporating repellers in the attribution prior of the sampling process. We successfully learn the hybrid system from an inspection scenario where an unmanned ground vehicle has to inspect, in a specific order, different areas of the environment. The system induces an interpretable computer program of the demonstration that can be synthesised to produce novel inspection behaviours. Importantly, the robot successfully runs the synthesised program on an unseen configuration of the environment while presenting explanations of its autonomous behaviour.},
howpublished = {Workshop on Agents and Robots for reliable Engineered Autonomy (AREA) colocated with ECAI},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Lower dimensional kernels for video discriminators Journal Article
Emmanuel Kahembwe, Subramanian Ramamoorthy
In: Neural Networks, vol. 132, pp. 506–520, 2020, ISSN: 0893-6080.
@article{Kahembwe_2020,
title = {Lower dimensional kernels for video discriminators},
author = {Emmanuel Kahembwe and Subramanian Ramamoorthy},
url = {http://dx.doi.org/10.1016/j.neunet.2020.09.016
https://arxiv.org/abs/1912.08860},
doi = {10.1016/j.neunet.2020.09.016},
issn = {0893-6080},
year = {2020},
date = {2020-12-01},
urldate = {2020-12-01},
journal = {Neural Networks},
volume = {132},
pages = {506–520},
publisher = {Elsevier BV},
abstract = {This work presents an analysis of the discriminators used in Generative Adversarial Networks (GANs) for Video. We show that unconstrained video discriminator architectures induce a loss surface with high curvature which make optimisation difficult. We also show that this curvature becomes more extreme as the maximal kernel dimension of video discriminators increases. With these observations in hand, we propose a family of efficient Lower-Dimensional Video Discriminators for GANs (LDVD GANs). The proposed family of discriminators improve the performance of video GAN models they are applied to and demonstrate good performance on complex and diverse datasets such as UCF-101. In particular, we show that they can double the performance of Temporal-GANs and provide for state-of-the-art performance on a single GPU.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Surfing on an uncertain edge: Precision cutting of soft tissue using torque-based medium classification Proceedings Article
Artūras Straižys, Michael Burke, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2020, ISBN: 978-1-7281-7395-5.
@inproceedings{straižys2019surfinguncertainedgeprecision,
title = {Surfing on an uncertain edge: Precision cutting of soft tissue using torque-based medium classification},
author = {Artūras Straižys and Michael Burke and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1909.07247},
doi = {10.1109/ICRA40945.2020.9196623},
isbn = {978-1-7281-7395-5},
year = {2020},
date = {2020-09-15},
urldate = {2019-01-01},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {Precision cutting of soft-tissue remains a challenging problem in robotics, due to the complex and unpredictable mechanical behaviour of tissue under manipulation. Here, we consider the challenge of cutting along the boundary between two soft mediums, a problem that is made extremely difficult due to visibility constraints, which means that the precise location of the cutting trajectory is typically unknown. This paper introduces a novel strategy to address this task, using a binary medium classifier trained using joint torque measurements, and a closed loop control law that relies on an error signal compactly encoded in the decision boundary of the classifier. We illustrate this on a grapefruit cutting task, successfully modulating a nominal trajectory fit using dynamic movement primitives to follow the boundary between grapefruit pulp and peel using torque based medium classification. Results show that this control strategy is successful in 72 % of attempts in contrast to control using a nominal trajectory, which only succeeds in 50 % of attempts.},
howpublished = {In Proc. IEEE International Conference on Robotics and Automation (ICRA), 2020.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Autonomous Driving with Interpretable Goal Recognition and Monte Carlo Tree Search Workshop
Cillian Brewitt, Stefano V Albrecht, John Wilhelm, Balint Gyevnar, Francisco Eiras, Mihai Dobre, Subramanian Ramamoorthy
2020, (Work done at FiveAI).
@workshop{brewittautonomous,
title = {Autonomous Driving with Interpretable Goal Recognition and Monte Carlo Tree Search},
author = {Cillian Brewitt and Stefano V Albrecht and John Wilhelm and Balint Gyevnar and Francisco Eiras and Mihai Dobre and Subramanian Ramamoorthy},
url = {https://sites.google.com/view/ida2020
https://www.research.ed.ac.uk/en/publications/autonomous-driving-with-interpretable-goal-recognition-and-monte-},
year = {2020},
date = {2020-07-13},
urldate = {2020-07-13},
abstract = {The ability to predict the intentions and driving trajectories of other vehicles is a key problem for autonomous driving. We propose an integrated planning and prediction system which leverages the computational benefit of using a finite space of maneuvers, and extend the approach to planning and prediction of sequences of maneuvers via rational inverse planning to recognise the goals of other vehicles. Goal recognition informs a Monte Carlo Tree Search (MCTS) algorithm to plan optimal maneuvers for the ego vehicle. Our system constructs plans which are explainable by means of rationality. Evaluation in simulations of four urban driving scenarios demonstrate the system’s ability to robustly recognise the goals of other vehicles while generating near-optimal plans.},
howpublished = {Workshop on Interaction and Decision-Making in Autonomous-Driving colocated with RSS },
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
An Optimization-based Motion Planner for Safe Autonomous Driving Workshop
Francisco Eiras, Majd Hawasly, Stefano V Albrecht, Subramanian Ramamoorthy
2020, (Work done at FiveAI).
@workshop{eiras2020optimization,
title = {An Optimization-based Motion Planner for Safe Autonomous Driving},
author = {Francisco Eiras and Majd Hawasly and Stefano V Albrecht and Subramanian Ramamoorthy},
url = {https://sites.google.com/view/rss2020robustautonomy/program
https://openreview.net/pdf?id=s4nJ5EZy_N1},
year = {2020},
date = {2020-07-13},
urldate = {2020-07-13},
abstract = {Guaranteeing safety in motion planning is a crucial bottleneck on the path towards wider adoption of autonomous driving technology. A promising direction is to pose safety requirements as planning constraints in nonlinear optimization problems of motion synthesis. However, many implementations of this approach are hindered by uncertain convergence and local optimality of the solutions, affecting the planner’s overall robustness. In this paper, we propose a novel two-stage optimization framework: we first find the solution to a Mixed-Integer Linear Programming (MILP) approximation of the motion synthesis problem, which in turn initializes a second Nonlinear Programming (NLP) formulation. We show that initializing the NLP stage with the MILP solution leads to better convergence, lower costs, and outperforms a state-of-the-art Nonlinear Model Predictive Control baseline in both progress and comfort metrics.},
howpublished = {RSS Workshop in Robust Autonomy},
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Separating manners of execution of forceful tasks when learning from multimodal demonstrations Workshop
Yordan Hristov, Subramanian Ramamoorthy
2020.
@workshop{hristovmanner2020,
title = {Separating manners of execution of forceful tasks when learning from multimodal demonstrations},
author = {Yordan Hristov and Subramanian Ramamoorthy},
url = {https://assistive-autonomy.ed.ac.uk/wp-content/uploads/2025/09/hristov2020separating-1.pdf},
year = {2020},
date = {2020-07-12},
urldate = {2020-07-12},
abstract = {As physically embodied agents, robots can use a diversity of modalities to sense and affect their surrounding environment. Unfortunately, such high-dimensional streams of information are hard for human comprehension, making human-robot interaction and teaching nontrivial. Thus, we pose the problem of interpretable learning from demonstration as an optimisation one over a probabilistic generative model. To account for the high-dimensionality of the data, a high-parameter neural network is chosen to represent the model. Its latent variables are explicitly aligned with high-level notions and concepts, manifested in the demonstrations. We show that such alignment can be achieved through the usage of restricted user labels. The method is evaluated in the context of table-top dabbing (pressing against a surface with a sponge) with a PR2 robot which provides us with visual information, arm joint positions and arm joint efforts.},
howpublished = {In Proc. Workshop on Advances & Challenges in Imitation Learning for Robotics, Robotics: Science and Systems (R:SS), 2020},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Elaborating on Learned Demonstrations with Temporal Logic Specifications Proceedings Article
Craig Innes, Subramanian Ramamoorthy
In: Robotics: Science and Systems (RSS), 2020.
@inproceedings{innes2020elaboratinglearneddemonstrationstemporal,
title = {Elaborating on Learned Demonstrations with Temporal Logic Specifications},
author = {Craig Innes and Subramanian Ramamoorthy},
url = {https://www.roboticsproceedings.org/rss16/p004.html
https://arxiv.org/abs/2002.00784
https://roboticsconference.org/2020/program/papers/4.html},
doi = {10.15607/RSS.2020.XVI.004},
year = {2020},
date = {2020-07-01},
urldate = {2020-07-01},
booktitle = {Robotics: Science and Systems (RSS)},
abstract = {Most current methods for learning from demonstrations assume that those demonstrations alone are sufficient to learn the underlying task. This is often untrue, especially if extra safety specifications exist which were not present in the original demonstrations. In this paper, we allow an expert to elaborate on their original demonstration with additional specification information using linear temporal logic (LTL). Our system converts LTL specifications into a differentiable loss. This loss is then used to learn a dynamic movement primitive that satisfies the underlying specification, while remaining close to the original demonstration. Further, by leveraging adversarial training, our system learns to robustly satisfy the given LTL specification on unseen inputs, not just those seen in training. We show that our method is expressive enough to work across a variety of common movement specification patterns such as obstacle avoidance, patrolling, keeping steady, and speed limitation. In addition, we show that our system can modify a base demonstration with complex specifications by incrementally composing multiple simpler specifications. We also implement our system on a PR-2 robot to show how a demonstrator can start with an initial (sub-optimal) demonstration, then interactively improve task success by including additional specifications enforced with our differentiable LTL loss.},
howpublished = {Robotics: Science and Systems (R:SS), 2020},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
From Demonstrations to Task-Space Specifications. Using Causal Analysis to Extract Rule Parameterization from Demonstrations Journal Article
Daniel Angelov, Yordan Hristov, Subramanian Ramamoorthy
In: Autonomous Agents and Multi-Agent Systems (JAAMAS), vol. 34, iss. 45, 2020.
@article{angelov2020demonstrationstaskspacespecificationsusing,
title = {From Demonstrations to Task-Space Specifications. Using Causal Analysis to Extract Rule Parameterization from Demonstrations},
author = {Daniel Angelov and Yordan Hristov and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/2006.11300
https://link.springer.com/article/10.1007/s10458-020-09471-w},
doi = {10.1007/s10458-020-09471-w},
year = {2020},
date = {2020-06-17},
urldate = {2020-06-17},
journal = {Autonomous Agents and Multi-Agent Systems (JAAMAS)},
volume = {34},
issue = {45},
abstract = {Learning models of user behaviour is an important problem that is broadly applicable across many application domains requiring human-robot interaction. In this work, we show that it is possible to learn generative models for distinct user behavioural types, extracted from human demonstrations, by enforcing clustering of preferred task solutions within the latent space. We use these models to differentiate between user types and to find cases with overlapping solutions. Moreover, we can alter an initially guessed solution to satisfy the preferences that constitute a particular user type by backpropagating through the learned differentiable models. An advantage of structuring generative models in this way is that we can extract causal relationships between symbols that might form part of the user's specification of the task, as manifested in the demonstrations. We further parameterize these specifications through constraint optimization in order to find a safety envelope under which motion planning can be performed. We show that the proposed method is capable of correctly distinguishing between three user types, who differ in degrees of cautiousness in their motion, while performing the task of moving objects with a kinesthetically driven robot in a tabletop environment. Our method successfully identifies the correct type, within the specified time, in 99% [97.8 - 99.8] of the cases, which outperforms an IRL baseline. We also show that our proposed method correctly changes a default trajectory to one satisfying a particular user specification even with unseen objects. The resulting trajectory is shown to be directly implementable on a PR2 humanoid robot completing the same task.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Affordances in Robotic Tasks – A Survey Working paper
Paola Ardón, Èric Pairet, Katrin S. Lohan, Subramanian Ramamoorthy, Ronald P. A. Petrick
2020.
@workingpaper{ardón2020affordancesrobotictasks,
title = {Affordances in Robotic Tasks – A Survey},
author = {Paola Ardón and Èric Pairet and Katrin S. Lohan and Subramanian Ramamoorthy and Ronald P. A. Petrick},
url = {https://arxiv.org/abs/2004.07400},
year = {2020},
date = {2020-04-15},
urldate = {2020-04-15},
abstract = {Affordances are key attributes of what must be perceived by an autonomous robotic agent in order to effectively interact with novel objects. Historically, the concept derives from the literature in psychology and cognitive science, where affordances are discussed in a way that makes it hard for the definition to be directly transferred to computational specifications useful for robots. This review article is focused specifically on robotics, so we discuss the related literature from this perspective. In this survey, we classify the literature and try to find common ground amongst different approaches with a view to application in robotics. We propose a categorisation based on the level of prior knowledge that is assumed to build the relationship among different affordance components that matter for a particular robotic task. We also identify areas for future improvement and discuss possible directions that are likely to be fruitful in terms of impact on robotics practice.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Composing Diverse Policies for Temporally Extended Tasks Journal Article
Daniel Angelov, Yordan Hristov, Michael Burke, Subramanian Ramamoorthy
In: IEEE Robotics and Automation Letters (RA-L), vol. 5, iss. 2, pp. 2658-2665, 2020, ISBN: 2377-3766.
@article{8989819,
title = {Composing Diverse Policies for Temporally Extended Tasks},
author = {Daniel Angelov and Yordan Hristov and Michael Burke and Subramanian Ramamoorthy},
url = {https://ieeexplore.ieee.org/document/8989819
https://arxiv.org/abs/1907.08199
https://youtu.be/b2WhYp2aNC8},
doi = {10.1109/LRA.2020.2972794},
isbn = {2377-3766},
year = {2020},
date = {2020-02-10},
urldate = {2020-02-10},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {5},
issue = {2},
pages = {2658-2665},
abstract = {Robot control policies for temporally extended and sequenced tasks are often characterized by discontinuous switches between different local dynamics. These change-points are often exploited in hierarchical motion planning to build approximate models and to facilitate the design of local, region-specific controllers. However, it becomes combinatorially challenging to implement such a pipeline for complex temporally extended tasks, especially when the sub-controllers work on different information streams, time scales and action spaces. In this letter, we introduce a method that can automatically compose diverse policies comprising motion planning trajectories, dynamic motion primitives and neural network controllers. We introduce a global goal scoring estimator that uses local, per-motion primitive dynamics models and corresponding activation state-space sets to sequence diverse policies in a locally optimal fashion. We use expert demonstrations to convert what is typically viewed as a gradient-based learning process into a planning process without explicitly specifying pre- and post-conditions. We first illustrate the proposed framework using an MDP benchmark to showcase robustness to action and model dynamics mismatch, and then with a particularly complex physical gear assembly task, solved on a PR2 robot. We show that the proposed approach successfully discovers the optimal sequence of controllers and solves both tasks efficiently.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2019
Vid2Param: Modeling of Dynamics Parameters From Video Journal Article
Martin Asenov, Michael Burke, Daniel Angelov, Todor Davchev, Kartic Subr, Subramanian Ramamoorthy
In: IEEE Robotics and Automation Letters (RA-L), vol. 5, no. 2, pp. 414-421, 2019, (Presented at ICRA 2020).
@article{8931564,
title = {Vid2Param: Modeling of Dynamics Parameters From Video},
author = {Martin Asenov and Michael Burke and Daniel Angelov and Todor Davchev and Kartic Subr and Subramanian Ramamoorthy},
url = {https://www.youtube.com/watch?v=JqtJYrj0mHs},
doi = {10.1109/LRA.2019.2959476},
year = {2019},
date = {2019-12-12},
urldate = {2020-01-01},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {5},
number = {2},
pages = {414-421},
abstract = {Sensors are routinely mounted on robots to acquire various forms of measurements in spatio-temporal fields. Locating features within these fields and reconstruction (mapping) of the dense fields can be challenging in resource-constrained situations, such as when trying to locate the source of a gas leak from a small number of measurements. In such cases, a model of the underlying complex dynamics can be exploited to discover informative paths within the field. We use a fluid simulator as a model, to guide inference for the location of a gas leak. We perform localization via minimization of the discrepancy between observed measurements and gas concentrations predicted by the simulator. Our method is able to account for dynamically varying parameters of wind flow (e.g., direction and strength), and its effects on the observed distribution of gas. We develop algorithms for off-line inference as well as for on-line path discovery via active sensing. We demonstrate the efficiency, accuracy and versatility of our algorithm using experiments with a physical robot conducted in outdoor environments. We deploy an unmanned air vehicle (UAV) mounted with a CO2 sensor to automatically seek out a gas cylinder emitting CO2 via a nozzle. We evaluate the accuracy of our algorithm by measuring the error in the inferred location of the nozzle, based on which we show that our proposed approach is competitive with respect to state of the art baselines.},
note = {Presented at ICRA 2020},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Disentangled Relational Representations for Explaining and Learning from Demonstration Honorable Mention Proceedings Article
Yordan Hristov, Daniel Angelov, Michael Burke, Alex Lascarides, Subramanian Ramamoorthy
In: Conference on Robot Learning (CoRL), pp. 870-884, PMLR, 2019.
@inproceedings{hristov2019disentangledrelationalrepresentationsexplaining,
title = {Disentangled Relational Representations for Explaining and Learning from Demonstration},
author = {Yordan Hristov and Daniel Angelov and Michael Burke and Alex Lascarides and Subramanian Ramamoorthy},
url = {https://proceedings.mlr.press/v100/hristov20a.html
https://arxiv.org/abs/1907.13627
https://sites.google.com/view/explain-n-repeat},
year = {2019},
date = {2019-10-30},
urldate = {2019-10-01},
booktitle = {Conference on Robot Learning (CoRL)},
volume = {100},
pages = {870-884},
publisher = {PMLR},
series = {Proceedings of Machine Learning Research},
abstract = {Learning from demonstration is an effective method for human users to instruct desired robot behaviour. However, for most non-trivial tasks of practical interest, efficient learning from demonstration depends crucially on inductive bias in the chosen structure for rewards/costs and policies. We address the case where this inductive bias comes from an exchange with a human user. We propose a method in which a learning agent utilizes the information bottleneck layer of a high-parameter variational neural model, with auxiliary loss terms, in order to ground abstract concepts such as spatial relations. The concepts are referred to in natural language instructions and are manifested in the high-dimensional sensory input stream the agent receives from the world. We evaluate the properties of the latent space of the learned model in a photorealistic synthetic environment and particularly focus on examining its usability for downstream tasks. Additionally, through a series of controlled table-top manipulation experiments, we demonstrate that the learned manifold can be used to ground demonstrations as symbolic plans, which can then be executed on a PR2 robot.},
howpublished = {Conference on Robot Learning (CoRL), 2019. [Best Paper Award Runner-up]},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Hybrid system identification using switching density networks Proceedings Article
Michael Burke, Yordan Hristov, Subramanian Ramamoorthy
In: Conference on Robot Learning (CoRL), pp. 172-181, PMLR, 2019.
@inproceedings{burke2019hybrididentificationusingswitching,
title = {Hybrid system identification using switching density networks},
author = {Michael Burke and Yordan Hristov and Subramanian Ramamoorthy},
url = {https://proceedings.mlr.press/v100/burke20a.html
https://arxiv.org/abs/1907.04360
},
year = {2019},
date = {2019-10-30},
urldate = {2019-01-01},
booktitle = {Conference on Robot Learning (CoRL)},
volume = {100},
pages = {172-181},
publisher = {PMLR},
series = {Proceedings of Machine Learning Research},
abstract = {Behaviour cloning is a commonly used strategy for imitation learning and can be extremely effective in constrained domains. However, in cases where the dynamics of an environment may be state dependent and varying, behaviour cloning places a burden on model capacity and the number of demonstrations required. This paper introduces switching density networks, which rely on a categorical reparametrisation for hybrid system identification. This results in a network comprising a classification layer that is followed by a regression layer. We use switching density networks to predict the parameters of hybrid control laws, which are toggled by a switching layer to produce different controller outputs, when conditioned on an input state. This work shows how switching density networks can be used for hybrid system identification in a variety of tasks, successfully identifying the key joint angle goals that make up manipulation tasks, while simultaneously learning image-based goal classifiers and regression networks that predict joint angles from images. We also show that they can cluster the phase space of an inverted pendulum, identifying the balance, spin and pump controllers required to solve this task. Switching density networks can be difficult to train, but we introduce a cross entropy regularisation loss that stabilises training.},
howpublished = {Conference on Robot Learning (CoRL), 2019},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
5G Network Enabled Robotics Applications Presentation
Subramanian Ramamoorthy, John Thompson, Cyrill von Tiesenhausen, Yongshun Zhang
14.10.2019.
@misc{Ramamoorthy5g2019,
title = {5G Network Enabled Robotics Applications},
author = {Subramanian Ramamoorthy and John Thompson and Cyrill von Tiesenhausen and Yongshun Zhang
},
url = {https://www.research.ed.ac.uk/en/publications/5g-network-enabled-robotics-applications},
year = {2019},
date = {2019-10-14},
urldate = {2019-10-14},
abstract = {Fifth generation (5G) wireless networks will help to support a revolution in healthcare, supporting more effective and lower cost medical services [1,2]. Ubiquitous wireless communications can help to enable smart medical data collection and processing, more efficient and timely medical interventions and enable robotic systems to support clinicians effectively in their daily work.},
keywords = {},
pubstate = {published},
tppubtype = {presentation}
}
Certification of Highly Automated Vehicles for Use on UK Roads: Creating An Industry-Wide Framework for Safety Presentation
Philip Koopman, Rob Hierons, Siddartha Khastgir, John Clark, Michael Fisher, Rob Alexander, Kerstin Eder, Pete Thomas, Geoff Barrett, Philip Torr, others
01.10.2019.
@misc{koopman2019certification,
title = {Certification of Highly Automated Vehicles for Use on UK Roads: Creating An Industry-Wide Framework for Safety},
author = {Philip Koopman and Rob Hierons and Siddartha Khastgir and John Clark and Michael Fisher and Rob Alexander and Kerstin Eder and Pete Thomas and Geoff Barrett and Philip Torr and others},
url = {https://www.five.ai/certification-of-highly-automated-vehicles-for-use-on-uk-roads-creating-an-industry-wide-framework-for-safety
},
year = {2019},
date = {2019-10-01},
urldate = {2019-01-01},
publisher = {Five AI Ltd},
abstract = {With the launch of this paper, Five AI is calling on industry and government to come together and agree on a framework that will ensure the safety of highly automated vehicles on UK roads.
We’ve united globally leading thinkers in the verification of complex autonomous systems and put together a set of insight and research-backed proposals and questions for industry and government, on the challenge of seeking and sharing verification evidence.},
keywords = {},
pubstate = {published},
tppubtype = {presentation}
}
We’ve united globally leading thinkers in the verification of complex autonomous systems and put together a set of insight and research-backed proposals and questions for industry and government, on the challenge of seeking and sharing verification evidence.
FPR—Fast Path Risk Algorithm to Evaluate Collision Probability Journal Article
Andrew Blake, Alejandro Bordallo, Kamen Brestnichki, Majd Hawasly, Svetlin Valentinov Penkov, Subramanian Ramamoorthy, Alexandre Silva
In: IEEE Robotics and Automation Letters (RA-L), vol. 5, no. 1, pp. 1-7, 2019, (Work done at FiveAI).
@article{blake2020,
title = {FPR—Fast Path Risk Algorithm to Evaluate Collision Probability},
author = {Andrew Blake and Alejandro Bordallo and Kamen Brestnichki and Majd Hawasly and Svetlin Valentinov Penkov and Subramanian Ramamoorthy and Alexandre Silva},
url = {https://ieeexplore.ieee.org/abstract/document/8846054
https://arxiv.org/abs/1804.05384},
doi = {10.1109/LRA.2019.2943074},
year = {2019},
date = {2019-09-23},
urldate = {2019-09-23},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {5},
number = {1},
pages = {1-7},
abstract = {As mobile robots and autonomous vehicles become increasingly prevalent in human-centred environments, there is a need to control the risk of collision. Perceptual modules, for example machine vision, provide uncertain estimates of object location. In that context, the frequently made assumption of an exactly known free-space is invalid. Clearly, no paths can be guaranteed to be collision free. Instead, it is necessary to compute the probabilistic risk of collision on any proposed path. The FPR algorithm, proposed here, efficiently calculates an upper bound on the risk of collision for a robot moving on the plane. That computation orders candidate trajectories according to (the bound on) their degree of risk. Then paths within a user-defined threshold of primary risk could be selected according to secondary criteria such as comfort and efficiency. The key contribution of this letter is the FPR algorithm and its `convolution trick' to factor the integrals used to bound the risk of collision. As a consequence of the convolution trick, given K obstacles and N candidate paths, the computational load is reduced from the naive O(NK), to the qualitatively faster O(N + K).},
note = {Work done at FiveAI},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Coarse preferences: representation, elicitation, and decision making PhD Thesis
Pavlos Andreadis
University of Edinburgh, 2019.
@phdthesis{andreadis2019coarse,
title = {Coarse preferences: representation, elicitation, and decision making},
author = {Pavlos Andreadis},
url = {http://hdl.handle.net/1842/35502},
year = {2019},
date = {2019-07-01},
urldate = {2019-07-01},
school = {University of Edinburgh},
abstract = {In this thesis we present a theory for learning and inference of user preferences with a novel hierarchical representation that captures preferential indifference. Such models of ’Coarse Preferences’ represent the space of solutions with a uni-dimensional, discrete latent space of ’categories’. This results in a partitioning of the space of solutions into preferential equivalence classes. This hierarchical model significantly reduces the computational burden of learning and inference, with improvements both in computation time and convergence behaviour with respect to number of samples. We argue that this Coarse Preferences model facilitates the efficient solution of previously computationally prohibitive recommendation procedures. The new problem of ’coordination through set recommendation’ is one such procedure where we formulate an optimisation problem by leveraging the factored nature of our representation. Furthermore, we show how an on-line learning algorithm can be used for the efficient solution of this problem. Other benefits of our proposed model include increased quality of recommendations in Recommender Systems applications, in domains where users’ behaviour
is consistent with such a hierarchical preference structure. We evaluate the usefulness of our proposed model and algorithms through experiments with two recommendation domains - a clothing retailer’s online interface, and a popular movie database. Our experimental results demonstrate computational gains over state of the art methods that use an additive decomposition of preferences in on-line active learning for recommendation.},
howpublished = {Edinburgh Research Archive (ERA)},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
is consistent with such a hierarchical preference structure. We evaluate the usefulness of our proposed model and algorithms through experiments with two recommendation domains - a clothing retailer’s online interface, and a popular movie database. Our experimental results demonstrate computational gains over state of the art methods that use an additive decomposition of preferences in on-line active learning for recommendation.
Learning structured task related abstractions PhD Thesis
Svetlin Valentinov Penkov
University of Edinburgh, 2019.
@phdthesis{penkov2019learningstructured,
title = {Learning structured task related abstractions},
author = {Svetlin Valentinov Penkov},
url = {https://era.ed.ac.uk/handle/1842/35875},
year = {2019},
date = {2019-07-01},
urldate = {2019-07-01},
school = {University of Edinburgh},
abstract = {As robots and autonomous agents are to assist people with more tasks in various domains they need the ability to quickly gain contextual awareness in unseen environments and learn new tasks. Current state of the art methods rely predominantly on statistical learning techniques which tend to overfit to sensory signals and often fail to extract structured task related abstractions. The obtained environment and task models are typically represented as black box objects that cannot be easily updated or inspected and provide limited generalisation capabilities. We address the aforementioned shortcomings of current methods by explicitly studying the problem of learning structured task related abstractions. In particular, we are interested in extracting symbolic representations of the environment from sensory signals and encoding the task to be executed as a computer program. We consider the standard problem of learning to solve a task by mapping sensory signals to actions and propose the decomposition of such a mapping into two stages: i) perceiving symbols from sensory data and ii) using a program to manipulate those symbols in order to make decisions. This thesis studies the bidirectional interactions between the agent’s capabilities to perceive symbols and the programs it can execute in order to
solve a task. In the first part of the thesis we demonstrate that access to a programmatic description of the task provides a strong inductive bias which facilitates the learning of structured task related representations of the environment. In order to do so, we first consider a collaborative human-robot interaction setup and propose a framework for Grounding and Learning Instances through Demonstration and Eye tracking (GLIDE)
which enables robots to learn symbolic representations of the environment from few demonstrations. In order to relax the constraints on the task encoding program which GLIDE assumes, we introduce the perceptor gradients algorithm and prove that it can be applied with any task encoding program.
In the second part of the thesis we investigate the complement problem of inducing task encoding programs assuming that a symbolic representations of the environment is available. Therefore, we propose the p-machine – a novel program induction framework which combines standard enumerative search techniques with a stochastic gradient descent optimiser in order to obtain an efficient program synthesiser.
We show that the induction of task encoding programs is applicable to various problems such as learning physics laws, inspecting neural networks and learning in human-robot interaction setups.},
howpublished = {Edinburgh Research Archive (ERA)},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
solve a task. In the first part of the thesis we demonstrate that access to a programmatic description of the task provides a strong inductive bias which facilitates the learning of structured task related representations of the environment. In order to do so, we first consider a collaborative human-robot interaction setup and propose a framework for Grounding and Learning Instances through Demonstration and Eye tracking (GLIDE)
which enables robots to learn symbolic representations of the environment from few demonstrations. In order to relax the constraints on the task encoding program which GLIDE assumes, we introduce the perceptor gradients algorithm and prove that it can be applied with any task encoding program.
In the second part of the thesis we investigate the complement problem of inducing task encoding programs assuming that a symbolic representations of the environment is available. Therefore, we propose the p-machine – a novel program induction framework which combines standard enumerative search techniques with a stochastic gradient descent optimiser in order to obtain an efficient program synthesiser.
We show that the induction of task encoding programs is applicable to various problems such as learning physics laws, inspecting neural networks and learning in human-robot interaction setups.
Reasoning on Grasp-Action Affordances Honorable Mention Proceedings Article
Paola Ardón, Èric Pairet, Ron Petrick, Subramanian Ramamoorthy, Katrin Lohan
In: Annual Conference Towards Autonomous Robotic Systems (TAROS), pp. 3-15, Springer, Cham, 2019.
@inproceedings{ardón2019reasoninggraspactionaffordances,
title = {Reasoning on Grasp-Action Affordances},
author = {Paola Ardón and Èric Pairet and Ron Petrick and Subramanian Ramamoorthy and Katrin Lohan},
url = {https://link.springer.com/chapter/10.1007/978-3-030-23807-0_1
https://arxiv.org/abs/1905.10610},
doi = {https://doi.org/10.1007/978-3-030-23807-0_1},
year = {2019},
date = {2019-06-28},
urldate = {2019-06-28},
booktitle = {Annual Conference Towards Autonomous Robotic Systems (TAROS)},
volume = {11649},
pages = {3-15},
publisher = {Springer, Cham},
series = { Lecture Notes in Computer Science},
abstract = {Artificial intelligence is essential to succeed in challenging activities that involve dynamic environments, such as object manipulation tasks in indoor scenes. Most of the state-of-the-art literature explores robotic grasping methods by focusing exclusively on attributes of the target object. When it comes to human perceptual learning approaches, these physical qualities are not only inferred from the object, but also from the characteristics of the surroundings. This work proposes a method that includes environmental context to reason on an object affordance to then deduce its grasping regions. This affordance is reasoned using a ranked association of visual semantic attributes harvested in a knowledge base graph representation. The framework is assessed using standard learning evaluation metrics and the zero-shot affordance prediction scenario. The resulting grasping areas are compared with unseen labelled data to asses their accuracy matching percentage. The outcome of this evaluation suggest the autonomy capabilities of the proposed method for object interaction applications in indoor environments.},
howpublished = {In Proc. Annual Conference Towards Autonomous Robotic Systems (TAROS), 2019. [Best Paper Award Nominee]},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
DynoPlan: Combining Motion Planning and Deep Neural Network based Controllers for Safe HRL Proceedings Article
Daniel Angelov, Yordan Hristov, Subramanian Ramamoorthy
In: Conference on Reinforcement Learning and Decision Making (RLDM), 2019.
@inproceedings{angelov2019dynoplancombiningmotionplanning,
title = {DynoPlan: Combining Motion Planning and Deep Neural Network based Controllers for Safe HRL},
author = {Daniel Angelov and Yordan Hristov and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1906.10099
https://rldm.org/papers/extendedabstracts.pdf},
year = {2019},
date = {2019-06-24},
urldate = {2019-01-01},
booktitle = {Conference on Reinforcement Learning and Decision Making (RLDM)},
abstract = {Many realistic robotics tasks are best solved compositionally, through control architectures that sequentially invoke primitives and achieve error correction through the use of loops and conditionals taking the system back to alternative earlier states. Recent end-to-end approaches to task learning attempt to directly learn a single controller that solves an entire task, but this has been difficult for complex control tasks that would have otherwise required a diversity of local primitive moves, and the resulting solutions are also not easy to inspect for plan monitoring purposes. In this work, we aim to bridge the gap between hand designed and learned controllers, by representing each as an option in a hybrid hierarchical Reinforcement Learning framework - DynoPlan. We extend the options framework by adding a dynamics model and the use of a nearness-to-goal heuristic, derived from demonstrations. This translates the optimization of a hierarchical policy controller to a problem of planning with a model predictive controller. By unrolling the dynamics of each option and assessing the expected value of each future state, we can create a simple switching controller for choosing the optimal policy within a constrained time horizon similarly to hill climbing heuristic search. The individual dynamics model allows each option to iterate and be activated independently of the specific underlying instantiation, thus allowing for a mix of motion planning and deep neural network based primitives. We can assess the safety regions of the resulting hybrid controller by investigating the initiation sets of the different options, and also by reasoning about the completeness and performance guarantees of the underpinning motion planners.},
howpublished = {In Proc. The Multi-disciplinary Conference on Reinforcement Learning and Decision Making (RLDM), 2019.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
An Empirical Evaluation of Adversarial Robustness under Transfer Learning Workshop
Todor Davchev, Timos Korres, Stathi Fotiadis, Nick Antonopoulos, Subramanian Ramamoorthy
2019.
@workshop{davchev2019empiricalevaluationadversarialrobustness,
title = {An Empirical Evaluation of Adversarial Robustness under Transfer Learning},
author = {Todor Davchev and Timos Korres and Stathi Fotiadis and Nick Antonopoulos and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1905.02675},
year = {2019},
date = {2019-06-14},
urldate = {2019-01-01},
abstract = {In this work, we evaluate adversarial robustness in the context of transfer learning from a source trained on CIFAR 100 to a target network trained on CIFAR 10. Specifically, we study the effects of using robust optimisation in the source and target networks. This allows us to identify transfer learning strategies under which adversarial defences are successfully retained, in addition to revealing potential vulnerabilities. We study the extent to which features learnt by a fast gradient sign method (FGSM) and its iterative alternative (PGD) can preserve their defence properties against black and white-box attacks under three different transfer learning strategies. We find that using PGD examples during training on the source task leads to more general robust features that are easier to transfer. Furthermore, under successful transfer, it achieves 5.2% more accuracy against white-box PGD attacks than suitable baselines. Overall, our empirical evaluations give insights on how well adversarial robustness under transfer learning can generalise.},
howpublished = {In Proc. ICML Workshop on Understanding and Improving Generalization in Deep Learning},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
From Explanation to Synthesis: Compositional Program Induction for Learning from Demonstration Proceedings Article
Michael Burke, Svetlin Valentinov Penkov, Subramanian Ramamoorthy
In: Robotics: Science and Systems (RSS), 2019.
@inproceedings{Burke_2019,
title = {From Explanation to Synthesis: Compositional Program Induction for Learning from Demonstration},
author = {Michael Burke and Svetlin Valentinov Penkov and Subramanian Ramamoorthy},
url = {http://dx.doi.org/10.15607/RSS.2019.XV.015
https://www.youtube.com/watch?v=K_GDe8azqyY},
doi = {10.15607/rss.2019.xv.015},
year = {2019},
date = {2019-06-01},
urldate = {2019-06-01},
booktitle = {Robotics: Science and Systems (RSS)},
series = {RSS2019},
abstract = {Hybrid systems are a compact and natural mechanism with which to address problems in robotics. This work introduces an approach to learning hybrid systems from demonstrations, with an emphasis on extracting models that are explicitly verifiable and easily interpreted by robot operators. We fit a sequence of controllers using sequential importance sampling under a generative switching proportional controller task model. Here, we parameterise controllers using a proportional gain and a visually verifiable joint angle goal. Inference under this model is challenging, but we address this by introducing an attribution prior extracted from a neural end-to-end visuomotor control model. Given the sequence of controllers comprising a task, we simplify the trace using grammar parsing strategies, taking advantage of the sequence compositionality, before grounding the controllers by training perception networks to predict goals given images. Using this approach, we are successfully able to induce a program for a visuomotor reaching task involving loops and conditionals from a single demonstration and a neural end-to-end model. In addition, we are able to discover the program used for a tower building task. We argue that computer program-like control systems are more interpretable than alternative end-to-end learning approaches, and that hybrid systems inherently allow for better generalisation across task configurations.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Using Causal Analysis to Learn Specifications from Task Demonstrations Proceedings Article
Daniel Angelov, Yordan Hristov, Subramanian Ramamoorthy
In: International Conference on Autonomous Agents and MultiAgent Systems (AAMAS), pp. 1341–1349, 2019, ISBN: 9781450363099.
@inproceedings{10.5555/3306127.3331841,
title = {Using Causal Analysis to Learn Specifications from Task Demonstrations},
author = {Daniel Angelov and Yordan Hristov and Subramanian Ramamoorthy},
url = {https://dl.acm.org/citation.cfm?id=3306127.3331841
https://rad.inf.ed.ac.uk/data/publications/2019/angelov2019causal.pdf},
isbn = {9781450363099},
year = {2019},
date = {2019-05-08},
urldate = {2019-01-01},
booktitle = {International Conference on Autonomous Agents and MultiAgent Systems (AAMAS)},
pages = {1341–1349},
abstract = {Learning models of user behaviour is an important problem that is broadly applicable across many application domains requiring human-robot interaction. In this work we show that it is possible to learn a generative model for distinct user behavioral types, extracted from human demonstrations, by enforcing clustering of preferred task solutions within the latent space. We use this model to differentiate between user types and to find cases with overlapping solutions. Moreover, we can alter an initially guessed solution to satisfy the preferences that constitute a particular user type by backpropagating through the learned differentiable model. An advantage of structuring generative models in this way is that it allows us to extract causal relationships between symbols that might form part of the user's specification of the task, as manifested in the demonstrations. We show that the proposed method is capable of correctly distinguishing between three user types, who differ in degrees of cautiousness in their motion, while performing the task of moving objects with a kinesthetically driven robot in a tabletop environment. Our method successfully identifies the correct type, within the specified time, in 99% [97.8 - 99.8] of the cases, which outperforms an IRL baseline. We also show that our proposed method correctly changes a default trajectory to one satisfying a particular user specification even with unseen objects. The resulting trajectory is shown to be directly implementable on a PR2 humanoid robot completing the same task.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning Programmatically Structured Representations with Perceptor Gradients Proceedings Article
Svetlin Penkov, Subramanian Ramamoorthy
In: International Conference on Learning Representations (ICLR), 2019.
@inproceedings{<LineBreak>penkov2018learning,
title = {Learning Programmatically Structured Representations with Perceptor Gradients},
author = {Svetlin Penkov and Subramanian Ramamoorthy},
url = {https://openreview.net/forum?id=SJggZnRcFQ
https://arxiv.org/abs/1905.00956},
year = {2019},
date = {2019-05-05},
urldate = {2019-01-01},
booktitle = {International Conference on Learning Representations (ICLR)},
abstract = {We present the perceptor gradients algorithm -- a novel approach to learning symbolic representations based on the idea of decomposing an agent's policy into i) a perceptor network extracting symbols from raw observation data and ii) a task encoding program which maps the input symbols to output actions. We show that the proposed algorithm is able to learn representations that can be directly fed into a Linear-Quadratic Regulator (LQR) or a general purpose A* planner. Our experimental results confirm that the perceptor gradients algorithm is able to efficiently learn transferable symbolic representations as well as generate new observations according to a semantically meaningful specification.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
To Stir or Not to Stir: Online Estimation of Liquid Properties for Pouring Actions Workshop
Tatiana Lopez-Guevara, Rita Pucci, Nicholas Taylor, Michael U. Gutmann, Subramanian Ramamoorthy, Kartic Subr
2019.
@workshop{guavara2019stir,
title = {To Stir or Not to Stir: Online Estimation of Liquid Properties for Pouring Actions},
author = {Tatiana Lopez-Guevara and Rita Pucci and Nicholas Taylor and Michael U. Gutmann and Subramanian Ramamoorthy and Kartic Subr},
url = {https://arxiv.org/abs/1904.02431},
year = {2019},
date = {2019-04-04},
abstract = {Our brains are able to exploit coarse physical models of fluids to solve everyday manipulation tasks. There has been considerable interest in developing such a capability in robots so that they can autonomously manipulate fluids adapting to different conditions. In this paper, we investigate the problem of adaptation to liquids with different characteristics. We develop a simple calibration task (stirring with a stick) that enables rapid inference of the parameters of the liquid from RBG data. We perform the inference in the space of simulation parameters rather than on physically accurate parameters. This facilitates prediction and optimization tasks since the inferred parameters may be fed directly to the simulator. We demonstrate that our "stirring" learner performs better than when the robot is calibrated with pouring actions. We show that our method is able to infer properties of three different liquids -- water, glycerin and gel -- and present experimental results by executing stirring and pouring actions on a UR10. We believe that decoupling of the training actions from the goal task is an important step towards simple, autonomous learning of the behavior of different fluids in unstructured environments.},
howpublished = {Workshop on Learning and Inference in Robotics: Integrating Structure, Priors and Models in RSS 2018 and Workshop on Modeling the Physical World: Perception, Learning, and Control in NeurIPS 2018.},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Autonomous multi-species environmental gas sensing using drone-based Fourier-transform infrared spectroscopy Journal Article
Marius Rutkauskas, Martin Asenov, Subramanian Ramamoorthy, Derryck T. Reid
In: Opt. Express, vol. 27, no. 7, pp. 9578–9587, 2019.
@article{Rutkauskas:19,
title = {Autonomous multi-species environmental gas sensing using drone-based Fourier-transform infrared spectroscopy},
author = {Marius Rutkauskas and Martin Asenov and Subramanian Ramamoorthy and Derryck T. Reid},
url = {https://opg.optica.org/oe/abstract.cfm?URI=oe-27-7-9578},
doi = {10.1364/OE.27.009578},
year = {2019},
date = {2019-03-19},
urldate = {2019-04-01},
journal = {Opt. Express},
volume = {27},
number = {7},
pages = {9578–9587},
publisher = {Optica Publishing Group},
abstract = {Unmanned aerial vehicles (UAVs)—or drones—present compelling new opportunities for airborne gas sensing in applications such as environmental monitoring, hazardous scene assessment, and facilities’ inspection. Instrumenting a UAV for this purpose encounters trade-offs between sensor size, weight, power, and performance, which drives the adoption of lightweight electrochemical and photo-ionisation detectors. However, this occurs at the expense of speed, selectivity, sensitivity, accuracy, resolution, and traceability. Here, we report on the design and integration of a broadband Fourier-transform infrared spectrometer with an autonomous UAV, providing ro-vibrational spectroscopy throughout the molecular fingerprint region from 3 – 11 µm (3333 – 909 cm−1) and enabling rapid, quantitative aerial surveys of multiple species simultaneously with an estimated noise-limited performance of 18 ppm (propane). Bayesian interpolation of the acquired gas concentrations is shown to provide both localization of a point source with approximately one meter accuracy, and distribution mapping of a gas cloud, with accompanying uncertainty quantification.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Multi-Species Environmental Gas Sensing Using Drone-Based Fourier-Transform Infrared Spectroscopy Proceedings Article
M. Rutkauskas, M. Asenov, S. Ramamoorthy, D. T. Reid
In: Optical Sensors and Sensing Congress, pp. 9578-9587, Optica Publishing Group, 2019.
@inproceedings{Rutkauskas:20,
title = {Multi-Species Environmental Gas Sensing Using Drone-Based Fourier-Transform Infrared Spectroscopy},
author = {M. Rutkauskas and M. Asenov and S. Ramamoorthy and D. T. Reid},
url = {https://opg.optica.org/oe/fulltext.cfm?uri=oe-27-7-9578&id=407522},
doi = {10.1364/OE.27.009578},
year = {2019},
date = {2019-03-19},
urldate = {2019-03-19},
booktitle = {Optical Sensors and Sensing Congress},
journal = {Optical Sensors and Sensing Congress},
volume = {27},
pages = {9578-9587},
publisher = {Optica Publishing Group},
abstract = {A 3-11 pm FTIR spectrometer is integrated with an autonomous UAV, enabling multi-species environmental gas sensing with a sensitivity of 37 ppm and noise-limited performance of 18 ppm (propane). Source localization is demonstrated using Bayesian interpolation.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning Best Response Strategies for Agents in Ad Exchanges Proceedings Article
Stavros Gerakaris, Subramanian Ramamoorthy
In: European Conference on Multi-Agent Systems (EUMAS), pp. 77–93, Springer International Publishing, 2019, ISSN: 1611-3349.
@inproceedings{Gerakaris_2019,
title = {Learning Best Response Strategies for Agents in Ad Exchanges},
author = {Stavros Gerakaris and Subramanian Ramamoorthy},
url = {http://dx.doi.org/10.1007/978-3-030-14174-5_6
https://www.springer.com/us/book/9783030141738},
doi = {10.1007/978-3-030-14174-5_6},
issn = {1611-3349},
year = {2019},
date = {2019-02-17},
urldate = {2019-01-01},
booktitle = {European Conference on Multi-Agent Systems (EUMAS)},
pages = {77–93},
publisher = {Springer International Publishing},
series = {Lecture Notes in Computer Science},
abstract = {Ad exchanges are widely used in platforms for online display advertising. Autonomous agents operating in these exchanges must learn policies for interacting profitably with a diverse, continually changing, but unknown market. We consider this problem from the perspective of a publisher, strategically interacting with an advertiser through a posted price mechanism. The learning problem for this agent is made difficult by the fact that information is censored, i.e., the publisher knows if an impression is sold but no other quantitative information. We address this problem using the Harsanyi-Bellman Ad Hoc Coordination (HBA) algorithm, which conceptualises this interaction in terms of a Stochastic Bayesian Game and arrives at optimal actions by best responding with respect to probabilistic beliefs maintained over a candidate set of opponent behaviour profiles. We adapt and apply HBA to the censored information setting of ad exchanges. Also, addressing the case of stochastic opponents, we devise a strategy based on a Kaplan-Meier estimator for opponent modelling. We evaluate the proposed method using simulations wherein we show that HBA-KM achieves substantially better competitive ratio and lower variance of return than baselines, including a Q-learning agent and a UCB-based online learning agent, and comparable to the offline optimal algorithm.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Active Localization of Gas Leaks Using Fluid Simulation Journal Article
Martin Asenov, Marius Rutkauskas, Derryck Reid, Kartic Subr, Subramanian Ramamoorthy
In: IEEE Robotics and Automation Letters (RA-L), vol. 4, no. 2, pp. 1776-1783, 2019, (Presented at ICRA 20219).
@article{8629026,
title = {Active Localization of Gas Leaks Using Fluid Simulation},
author = {Martin Asenov and Marius Rutkauskas and Derryck Reid and Kartic Subr and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1901.09608
https://www.youtube.com/watch?v=-ARfEpfLVD0},
doi = {10.1109/LRA.2019.2895820},
year = {2019},
date = {2019-01-29},
urldate = {2019-01-01},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {4},
number = {2},
pages = {1776-1783},
abstract = {Sensors are routinely mounted on robots to acquire various forms of measurements in spatio-temporal fields. Locating features within these fields and reconstruction (mapping) of the dense fields can be challenging in resource-constrained situations, such as when trying to locate the source of a gas leak from a small number of measurements. In such cases, a model of the underlying complex dynamics can be exploited to discover informative paths within the field. We use a fluid simulator as a model, to guide inference for the location of a gas leak. We perform localization via minimization of the discrepancy between observed measurements and gas concentrations predicted by the simulator. Our method is able to account for dynamically varying parameters of wind flow (e.g., direction and strength), and its effects on the observed distribution of gas. We develop algorithms for off-line inference as well as for on-line path discovery via active sensing. We demonstrate the efficiency, accuracy and versatility of our algorithm using experiments with a physical robot conducted in outdoor environments. We deploy an unmanned air vehicle (UAV) mounted with a CO2 sensor to automatically seek out a gas cylinder emitting CO2 via a nozzle. We evaluate the accuracy of our algorithm by measuring the error in the inferred location of the nozzle, based on which we show that our proposed approach is competitive with respect to state of the art baselines.},
note = {Presented at ICRA 20219},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Object affordances by inferring on the surroundings Proceedings Article
Paola Ardón Ramírez, Subramanian Ramamoorthy, Katrin Solveig Lohan
In: IEEE Workshop on Advanced Robotics and its Social Impacts (ARSO), IEEE, 2019.
@inproceedings{Paola2019object,
title = {Object affordances by inferring on the surroundings},
author = {Paola Ardón Ramírez and Subramanian Ramamoorthy and Katrin Solveig Lohan },
doi = {10.1109/ARSO.2018.8625829},
year = {2019},
date = {2019-01-27},
urldate = {2019-01-27},
booktitle = {IEEE Workshop on Advanced Robotics and its Social Impacts (ARSO)},
publisher = {IEEE},
abstract = {Robotic cognitive manipulation methods aim to imitate the human-object interactive process. Most of the of the state-of-the-art literature explore these methods by focusing on the target object or on the robot’s morphology, without including the surrounding environment. Most recent approaches suggest that taking into account the semantic properties of the surrounding environment improves the object recognition. When it comes to human cognitive development methods, these physical qualities are not only inferred from the object but also from the semantic characteristics of the surroundings. Thus the importance of affordances. In affordances, the representation of the perceived physical qualities of the objects gives valuable information about the possible manipulation actions. Hence, our research pursuits to develop a cognitive affordances map by (i) considering the object and the characteristics of the environment in which this object is more likely to appear, and (ii) achieving a learning mechanism that will intrinsically learn these affordances from self-experience.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Iterative Model-Based Reinforcement Learning Using Simulations in the Differentiable Neural Computer Workshop
Adeel Mufti, Svetlin Penkov, Subramanian Ramamoorthy
2019.
@workshop{mufti2019iterativemodelbasedreinforcementlearning,
title = {Iterative Model-Based Reinforcement Learning Using Simulations in the Differentiable Neural Computer},
author = {Adeel Mufti and Svetlin Penkov and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1906.07248},
year = {2019},
date = {2019-01-01},
urldate = {2019-01-01},
abstract = {We propose a lifelong learning architecture, the Neural Computer Agent (NCA), where a Reinforcement Learning agent is paired with a predictive model of the environment learned by a Differentiable Neural Computer (DNC). The agent and DNC model are trained in conjunction iteratively. The agent improves its policy in simulations generated by the DNC model and rolls out the policy to the live environment, collecting experiences in new portions or tasks of the environment for further learning. Experiments in two synthetic environments show that DNC models can continually learn from pixels alone to simulate new tasks as they are encountered by the agent, while the agents can be successfully trained to solve the tasks using Proximal Policy Optimization entirely in simulations.},
howpublished = {Workshop on Multi-Task and Lifelong Reinforcement Learning colocated with ICML},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Learning Grasp Affordance Reasoning Through Semantic Relations Journal Article
Paola Ardón, Èric Pairet, Ronald P. A. Petrick, Subramanian Ramamoorthy, Katrin S. Lohan
In: IEEE Robotics and Automation Letters (RA-L), vol. 4, no. 4, pp. 4571-4578, 2019, (Presented at IROS 2019).
@article{8790777,
title = {Learning Grasp Affordance Reasoning Through Semantic Relations},
author = {Paola Ardón and Èric Pairet and Ronald P. A. Petrick and Subramanian Ramamoorthy and Katrin S. Lohan},
url = {https://arxiv.org/abs/1906.09836
https://www.youtube.com/watch?v=vQTerupKrG0},
doi = {10.1109/LRA.2019.2933815},
year = {2019},
date = {2019-01-01},
urldate = {2019-01-01},
journal = {IEEE Robotics and Automation Letters (RA-L)},
volume = {4},
number = {4},
pages = {4571-4578},
abstract = {Reasoning about object affordances allows an autonomous agent to perform generalised manipulation tasks among object instances. While current approaches to grasp affordance estimation are effective, they are limited to a single hypothesis. We present an approach for detection and extraction of multiple grasp affordances on an object via visual input. We define semantics as a combination of multiple attributes, which yields benefits in terms of generalisation for grasp affordance prediction. We use Markov Logic Networks to build a knowledge base graph representation to obtain a probability distribution of grasp affordances for an object. To harvest the knowledge base, we collect and make available a novel dataset that relates different semantic attributes. We achieve reliable mappings of the predicted grasp affordances on the object by learning prototypical grasping patches from several examples. We show our method's generalisation capabilities on grasp affordance prediction for novel instances and compare with similar methods in the literature. Moreover, using a robotic platform, on simulated and real scenarios, we evaluate the success of the grasping task when conditioned on the grasp affordance prediction.},
note = {Presented at IROS 2019},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2018
Topological signatures for fast mobility analysis Proceedings Article
Abhirup Ghosh, Benedek Rozemberczki, Subramanian Ramamoorthy, Rik Sarkar
In: ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL), pp. 159–168, ACM, Seattle, Washington, 2018, ISBN: 9781450358897.
@inproceedings{10.1145/3274895.3274952,
title = {Topological signatures for fast mobility analysis},
author = {Abhirup Ghosh and Benedek Rozemberczki and Subramanian Ramamoorthy and Rik Sarkar},
url = {https://doi.org/10.1145/3274895.3274952
https://rad.inf.ed.ac.uk/data/publications/2018/sarkar2018topological.pdf},
doi = {10.1145/3274895.3274952},
isbn = {9781450358897},
year = {2018},
date = {2018-11-06},
urldate = {2018-01-01},
booktitle = {ACM International Conference on Advances in Geographic Information Systems (SIGSPATIAL)},
pages = {159–168},
publisher = {ACM},
address = {Seattle, Washington},
abstract = {Analytic methods can be difficult to build and costly to train for mobility data. We show that information about the topology of the space and how mobile objects navigate the obstacles can be used to extract insights about mobility at larger distance scales. The main contribution of this paper is a topological signature that maps each trajectory to a relatively low dimensional Euclidean space, so that now they are amenable to standard analytic techniques. Data mining tasks: nearest neighbor search with locality sensitive hashing, clustering, regression, etc., work more efficiently in this signature space. We define the problem of mobility prediction at different distance scales, and show that with the signatures simple k nearest neighbor based regression perform accurate prediction. Experiments on multiple real datasets show that the framework using topological signatures is accurate on all tasks, and substantially more efficient than machine learning applied to raw data. Theoretical results show that the signatures contain enough topological information to reconstruct non-self-intersecting trajectories upto homotopy type. The construction of signatures is based on a differential form that can be generated in a distributed setting using local communication, and a signature can be locally and inexpensively updated and communicated by a mobile agent.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Interpretable Latent Spaces for Learning from Demonstration Proceedings Article
Yordan Hristov, Alex Lascarides, Subramanian Ramamoorthy
In: Conference on Robot Learning (CoRL), pp. 957-968, PMLR, 2018.
@inproceedings{hristov2018interpretablelatentspaceslearning,
title = {Interpretable Latent Spaces for Learning from Demonstration},
author = {Yordan Hristov and Alex Lascarides and Subramanian Ramamoorthy},
url = {https://proceedings.mlr.press/v87/hristov18a.html
https://arxiv.org/abs/1807.06583
},
year = {2018},
date = {2018-10-29},
urldate = {2018-01-01},
booktitle = {Conference on Robot Learning (CoRL)},
volume = {87},
pages = {957-968},
publisher = {PMLR},
series = {Proceedings of Machine Learning Research},
abstract = {Effective human-robot interaction, such as in robot learning from human demonstration, requires the learning agent to be able to ground abstract concepts (such as those contained within instructions) in a corresponding high-dimensional sensory input stream from the world. Models such as deep neural networks, with high capacity through their large parameter spaces, can be used to compress the high-dimensional sensory data to lower dimensional representations. These low-dimensional representations facilitate symbol grounding, but may not guarantee that the representation would be human-interpretable. We propose a method which utilises the grouping of user-defined symbols and their corresponding sensory observations in order to align the learnt compressed latent representation with the semantic notions contained in the abstract labels. We demonstrate this through experiments with both simulated and real-world object data, showing that such alignment can be achieved in a process of physical symbol grounding.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Towards Robust Grasps: Using the Environment Semantics for Robotic Object Affordances Proceedings Article
Paola Ardon, Eric Pairet, Subramanian Ramamoorthy, Katrin Solveig Lohan
In: AAAI Fall Symposium. Reasoning and Learning in Real-World Systems for Long-Term Autonomy, AAAI, 2018.
@inproceedings{ardon2018towards,
title = {Towards Robust Grasps: Using the Environment Semantics for Robotic Object Affordances},
author = {Paola Ardon and Eric Pairet and Subramanian Ramamoorthy and Katrin Solveig Lohan},
url = {https://assistive-autonomy.ed.ac.uk/wp-content/uploads/2025/09/ardon2018towards.pdf},
year = {2018},
date = {2018-10-18},
booktitle = {AAAI Fall Symposium. Reasoning and Learning in Real-World Systems for Long-Term Autonomy},
publisher = {AAAI},
abstract = {Artificial Intelligence is essential to achieve a reliable human-robot interaction, especially when it comes to manipulation tasks. Most of the state-of-the-art literature explores robotics grasping methods by focusing on the target object or the robot’s morphology, without including the environment. When it comes to human cognitive development approaches, these physical qualities are not only inferred from the object, but also from the semantic characteristics of the surroundings. The same analogy can be used in robotic affordances for improving objects grasps, where the perceived physical qualities of the objects give valuable information about the possible manipulation actions. This work proposes a framework able to reason on the object affordances and grasping regions. Each calculated grasping area is the result of a sequence of concrete ranked decisions based on the inference of different highly related attributes. The results show that the system is able to infer on good grasping areas depending on its affordance without having any a-priori knowledge on the shape nor the grasping points.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Dynamic Evaluation of Neural Sequence Models Proceedings Article
Ben Krause, Emmanuel Kahembwe, Iain Murray, Steve Renals
In: International Conference on Machine Learning (ICML), pp. 2766-2775, PMLR, 2018.
@inproceedings{krause2017dynamicevaluationneuralsequence,
title = {Dynamic Evaluation of Neural Sequence Models},
author = {Ben Krause and Emmanuel Kahembwe and Iain Murray and Steve Renals},
url = {https://proceedings.mlr.press/v80/krause18a.html
https://arxiv.org/abs/1709.07432},
year = {2018},
date = {2018-07-10},
urldate = {2017-01-01},
booktitle = {International Conference on Machine Learning (ICML)},
volume = {80},
pages = {2766-2775},
publisher = {PMLR},
series = {Proceedings of Machine Learning Research},
abstract = {We present methodology for using dynamic evaluation to improve neural sequence models. Models are adapted to recent history via a gradient descent based mechanism, causing them to assign higher probabilities to re-occurring sequential patterns. Dynamic evaluation outperforms existing adaptation approaches in our comparisons. Dynamic evaluation improves the state-of-the-art word-level perplexities on the Penn Treebank and WikiText-2 datasets to 51.1 and 44.3 respectively, and the state-of-the-art character-level cross-entropies on the text8 and Hutter Prize datasets to 1.19 bits/char and 1.08 bits/char respectively.},
howpublished = {International Conference on Machine Learning (ICML), 2018. },
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning from demonstration of trajectory preferences through causal modeling and inference Workshop
Daniel Angelov, Subramanian Ramamoorthy
2018.
@workshop{angelov2018,
title = {Learning from demonstration of trajectory preferences through causal modeling and inference},
author = {Daniel Angelov and Subramanian Ramamoorthy},
url = {https://www.research.ed.ac.uk/en/publications/learning-from-demonstration-of-trajectory-preferences-through-cau},
year = {2018},
date = {2018-06-30},
abstract = {Learning from demonstration is associated with acquiring a solution to a task by mimicking a teacher demonstrator. Understanding the underlying reasons and in turn preferences that lead to a demonstration can yield better task comprehension. We present a generative model that describes a table-top task in terms of a causal model with respect to known concepts (e.g., the notion of a fork). Causal reasoning in the latent space of this generative model fully describes the meaning of the demonstration, e.g., that we would like to move far away from the fork. We show that by sampling from the model latent space, we can learn a solution to the problem that defines the task being demonstrated. We use a simulated kitchen tabletop environment to show changes in the underlying trajectory preference of demonstrations for different objects. The ability to generate additional data through introspection of the latent space allows us to confirm the causal model for the problem.},
howpublished = {Workshop on Perspectives on Robot Learning: Casualty and Imitation colocated with RSS18},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
The Active Inference Approach to Ecological Perception: General Information Dynamics for Natural and Artificial Embodied Cognition Journal Article
Adam Linson, Andy Clark, Subramanian Ramamoorthy, Karl Friston
In: Frontiers in Robotics and AI, vol. Volume 5, 2018, ISSN: 2296-9144.
@article{10.3389/frobt.2018.00021,
title = {The Active Inference Approach to Ecological Perception: General Information Dynamics for Natural and Artificial Embodied Cognition},
author = {Adam Linson and Andy Clark and Subramanian Ramamoorthy and Karl Friston},
url = {https://www.frontiersin.org/journals/robotics-and-ai/articles/10.3389/frobt.2018.00021},
doi = {10.3389/frobt.2018.00021},
issn = {2296-9144},
year = {2018},
date = {2018-03-08},
urldate = {2018-01-01},
journal = {Frontiers in Robotics and AI},
volume = {Volume 5},
abstract = {The emerging neurocomputational vision of humans as embodied, ecologically embedded, social agents—who shape and are shaped by their environment—offers a golden opportunity to revisit and revise ideas about the physical and information-theoretic underpinnings of life, mind, and consciousness itself. In particular, the active inference framework (AIF) makes it possible to bridge connections from computational neuroscience and robotics/AI to ecological psychology and phenomenology, revealing common underpinnings and overcoming key limitations. AIF opposes the mechanistic to the reductive, while staying fully grounded in a naturalistic and information-theoretic foundation, using the principle of free energy minimization. The latter provides a theoretical basis for a unified treatment of particles, organisms, and interactive machines, spanning from the inorganic to organic, non-life to life, and natural to artificial agents. We provide a brief introduction to AIF, then explore its implications for evolutionary theory, ecological psychology, embodied phenomenology, and robotics/AI research. We conclude the paper by considering implications for machine consciousness.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
The ORCA Hub: Explainable Offshore Robotics through Intelligent Interfaces Workshop
Helen Hastie, Katrin Lohan, Mike Chantler, David A. Robb, Subramanian Ramamoorthy, Ron Petrick, Sethu Vijayakumar, David Lane
2018.
@workshop{hastie2018orca,
title = {The ORCA Hub: Explainable Offshore Robotics through Intelligent Interfaces},
author = {Helen Hastie and Katrin Lohan and Mike Chantler and David A. Robb and Subramanian Ramamoorthy and Ron Petrick and Sethu Vijayakumar and David Lane},
url = {https://arxiv.org/abs/1803.02100},
year = {2018},
date = {2018-03-06},
abstract = {We present the UK Robotics and Artificial Intelligence Hub for Offshore Robotics for Certification of Assets (ORCA Hub), a 3.5 year EPSRC funded, multi-site project. The ORCA Hub vision is to use teams of robots and autonomous intelligent systems (AIS) to work on offshore energy platforms to enable cheaper, safer and more efficient working practices. The ORCA Hub will research, integrate, validate and deploy remote AIS solutions that can operate with existing and future offshore energy assets and sensors, interacting safely in autonomous or semi-autonomous modes in complex and cluttered environments, co-operating with remote operators. The goal is that through the use of such robotic systems offshore, the need for personnel will decrease. To enable this to happen, the remote operator will need a high level of situation awareness and key to this is the transparency of what the autonomous systems are doing and why. This increased transparency will facilitate a trusting relationship, which is particularly key in high-stakes, hazardous situations.},
howpublished = {In Workshop on Explainable Robotic Systems Workshop, ACM HRI},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
2017
Adaptable Pouring: Teaching Robots Not to Spill using Fast but Approximate Fluid Simulation Proceedings Article
Tatiana Lopez-Guevara, Nicholas K Taylor, Michael U Gutmann, Subramanian Ramamoorthy, Kartic Subr
In: Conference on Robot Learning, pp. 77-86, PMLR, 2017.
@inproceedings{guevara2017pour,
title = {Adaptable Pouring: Teaching Robots Not to Spill using Fast but Approximate Fluid Simulation},
author = {Tatiana Lopez-Guevara and Nicholas K Taylor and Michael U Gutmann and Subramanian Ramamoorthy and Kartic Subr },
url = {https://proceedings.mlr.press/v78/lopez-guevara17a.html},
year = {2017},
date = {2017-11-13},
booktitle = {Conference on Robot Learning},
volume = {78},
pages = {77-86},
publisher = {PMLR},
series = {Proceedings of Machine Learning Research},
abstract = {Humans manipulate fluids intuitively using intuitive approximations of the underlying physical model. In this paper, we explore a general methodology that robots may use to develop and improve strategies for overcoming manipulation tasks associated with appropriately defined loss functions. We focus on the specific task of pouring a liquid from a container (pourer) to another container (receiver) while minimizing the mass of liquid that spills outside the receiver. We present a solution, based on guidance from approximate simulation, that is fast, flexible and adaptable to novel containers as long as their shapes can be sensed. Our key idea is to decouple the optimization of the parameter space of the simulator from the optimization over action space for determining robot control actions. We perform the former in a training (calibration) stage and the latter during run-time (deployment). For the purpose of this paper we use pouring in both stages, even though separate actions could be chosen. We compare four different strategies for calibration and three different strategies for deployment. Our results demonstrate that fast fluid simulations are effective, even if they are only approximate, in guiding automatic strategies for pouring liquids.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Multi-scale Activity Estimation with Spatial Abstractions Proceedings Article
Majd Hawasly, Florian T. Pokorny, Subramanian Ramamoorthy
In: Geometric Science of Information, Springer, Cham, 2017.
@inproceedings{hawasly2017multi,
title = {Multi-scale Activity Estimation with Spatial Abstractions},
author = {Majd Hawasly and Florian T. Pokorny and Subramanian Ramamoorthy },
doi = {10.1007/978-3-319-68445-1_32},
year = {2017},
date = {2017-10-24},
booktitle = {Geometric Science of Information},
volume = {10589},
publisher = {Springer, Cham},
series = {Lecture Notes in Computer Science},
abstract = {Estimation and forecasting of dynamic state are fundamental to the design of autonomous systems such as intelligent robots. State-of-the-art algorithms, such as the particle filter, face computational limitations when needing to maintain beliefs over a hypothesis space that is made large by the dynamic nature of the environment. We propose an algorithm that utilises a hierarchy of such filters, exploiting a filtration arising from the geometry of the underlying hypothesis space. In addition to computational savings, such a method can accommodate the availability of evidence at varying degrees of coarseness. We show, using synthetic trajectory datasets, that our method achieves a better normalised error in prediction and better time to convergence to a true class when compared against baselines that do not similarly exploit geometric structure.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Grounding Symbols in Multi-Modal Instructions Workshop
Yordan Hristov, Svetlin Penkov, Alex Lascarides, Subramanian Ramamoorthy
2017.
@workshop{hristov-etal-2017-grounding,
title = {Grounding Symbols in Multi-Modal Instructions},
author = {Yordan Hristov and Svetlin Penkov and Alex Lascarides and Subramanian Ramamoorthy},
url = {https://aclanthology.org/W17-2807/
https://arxiv.org/abs/1706.00355},
doi = {10.18653/v1/W17-2807},
year = {2017},
date = {2017-08-01},
abstract = {As robots begin to cohabit with humans in semi-structured environments, the need arises to understand instructions involving rich variability—for instance, learning to ground symbols in the physical world. Realistically, this task must cope with small datasets consisting of a particular users’ contextual assignment of meaning to terms. We present a method for processing a raw stream of cross-modal input—i.e., linguistic instructions, visual perception of a scene and a concurrent trace of 3D eye tracking fixations—to produce the segmentation of objects with a correspondent association to high-level concepts. To test our framework we present experiments in a table-top object manipulation scenario. Our results show our model learns the user’s notion of colour and shape from a small number of physical demonstrations, generalising to identifying physical referents for novel combinations of the words.},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Physical symbol grounding and instance learning through demonstration and eye tracking Proceedings Article
Svetlin Penkov, Alejandro Bordallo, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2017.
@inproceedings{penkov2017physical,
title = {Physical symbol grounding and instance learning through demonstration and eye tracking},
author = {Svetlin Penkov and Alejandro Bordallo and Subramanian Ramamoorthy },
doi = {10.1109/ICRA.2017.7989697},
year = {2017},
date = {2017-07-24},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {It is natural for humans to work with abstract plans which are often an intuitive and concise way to represent a task. However, high level task descriptions contain symbols and concepts which need to be grounded within the environment if the plan is to be executed by an autonomous robot. The problem of learning the mapping between abstract plan symbols and their physical instances in the environment is known as the problem of physical symbol grounding. In this paper, we propose a framework for Grounding and Learning Instances through Demonstration and Eye tracking (GLIDE). We associate traces of task demonstration to a sequence of fixations which we call fixation programs and exploit their properties in order to perform physical symbol grounding. We formulate the problem as a probabilistic generative model and present an algorithm for computationally feasible inference over the proposed model. A key aspect of our work is that we estimate fixation locations within the environment which enables the appearance of symbol instances to be learnt. Instance learning is a crucial ability when the robot does not have any knowledge about the model or the appearance of the symbols referred to in the plan instructions. We have conducted human experiments and demonstrate that GLIDE successfully grounds plan symbols and learns the appearance of their instances, thus enabling robots to autonomously execute tasks in initially unknown environments.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Intention prediction for interactive navigation in distributed robotic systems PhD Thesis
Alejandro Bordallo
University of Edinburgh, 2017.
@phdthesis{bordallo2017,
title = {Intention prediction for interactive navigation in distributed robotic systems},
author = {Alejandro Bordallo
},
url = {https://era.ed.ac.uk/handle/1842/28802},
year = {2017},
date = {2017-07-07},
urldate = {2017-07-07},
school = {University of Edinburgh},
abstract = {Modern applications of mobile robots require them to have the ability to safely and effectively navigate in human environments. New challenges arise when these robots must plan their motion in a human-aware fashion. Current methods addressing this problem have focused mainly on the activity forecasting aspect, aiming at improving predictions without considering the active nature of the interaction, i.e. the robot’s effect on the environment and consequent issues such as reciprocity. Furthermore, many methods rely on computationally expensive offline training of predictive models that may not be well suited to rapidly evolving dynamic environments. This thesis presents a novel approach for enabling autonomous robots to navigate socially in environments with humans. Following formulations of the inverse planning problem, agents reason about the intentions of other agents and make predictions about their future interactive motion. A technique is proposed to implement counterfactual reasoning over a parametrised set of light-weight reciprocal motion models, thus making it more tractable to maintain beliefs over the future trajectories of other agents towards plausible goals. The speed of inference and the effectiveness of the algorithms is demonstrated via physical robot experiments, where computationally constrained robots navigate amongst humans in a distributed multi-sensor setup, able to infer other agents’ intentions as fast as 100ms after the first observation. While intention inference is a key aspect of successful human-robot interaction, executing any task requires planning that takes into account the predicted goals and trajectories of other agents, e.g., pedestrians. It is well known that robots demonstrate unwanted behaviours, such as freezing or becoming sluggishly responsive, when placed in dynamic and cluttered environments, due to the way in which safety margins according to simple heuristics end up covering the entire feasible space of motion. The presented approach makes more refined predictions about future movement, which enables robots to find collision-free paths quickly and efficiently. This thesis describes a novel technique for generating "interactive costmaps", a representation of the planner’s costs and rewards across time and space, providing an autonomous robot with the information required to navigate socially given the estimate of other agents’ intentions. This multi-layered costmap deters the robot from obstructing while encouraging social navigation respectful of other agents’ activity. Results show that this approach minimises collisions and near-collisions, minimises travel times for agents, and importantly offers the same computational cost as the most common costmap alternatives for navigation. A key part of the practical deployment of such technologies is their ease of implementation and configuration. Since every use case and environment is different and distinct, the presented methods use online adaptation to learn parameters of the navigating agents during runtime. Furthermore, this thesis includes a novel technique for allocating tasks in distributed robotics systems, where a tool is provided to maximise the performance on any distributed setup by automatic parameter tuning. All of these methods are implemented in ROS and distributed as open-source. The ultimate aim is to provide an accessible and efficient framework that may be seamlessly deployed on modern robots, enabling widespread use of intention prediction for interactive navigation in distributed robotic systems.},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Using program induction to interpret transition system dynamics Workshop
Svetlin Penkov, Subramanian Ramamoorthy
2017.
@workshop{penkov2017program,
title = {Using program induction to interpret transition system dynamics},
author = {Svetlin Penkov and Subramanian Ramamoorthy},
url = {https://openreview.net/pdf?id=Bk7CEtxXW
https://arxiv.org/abs/1708.00376},
year = {2017},
date = {2017-06-19},
abstract = {Explaining and reasoning about processes which underlie observed black-box phenomena enables the discovery of causal mechanisms, derivation of suitable abstract representations and the formulation of more robust predictions. We propose to learn high level functional programs in order to represent abstract models which capture the invariant structure in the observed data. We introduce the pi-machine (program-induction machine) -- an architecture able to induce interpretable LISP-like programs from observed data traces. We propose an optimisation procedure for program learning based on backpropagation, gradient descent and A* search. We apply the proposed method to two problems: system identification of dynamical systems and explaining the behaviour of a DQN agent. Our results show that the pi-machine can efficiently induce interpretable programs from individual data traces.
},
howpublished = {Workshop on Human Interpretability in Machine Learning colocated with ICML},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Explaining Transition Systems through Program Induction Working paper
Svetlin Penkov, Subramanian Ramamoorthy
2017.
@workingpaper{penkov2017explainingtransitionsystemsprogram,
title = {Explaining Transition Systems through Program Induction},
author = {Svetlin Penkov and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1705.08320},
year = {2017},
date = {2017-05-23},
urldate = {2017-01-01},
abstract = {Explaining and reasoning about processes which underlie observed black-box phenomena enables the discovery of causal mechanisms, derivation of suitable abstract representations and the formulation of more robust predictions. We propose to learn high level functional programs in order to represent abstract models which capture the invariant structure in the observed data. We introduce the π-machine (program-induction machine) -- an architecture able to induce interpretable LISP-like programs from observed data traces. We propose an optimisation procedure for program learning based on backpropagation, gradient descent and A* search. We apply the proposed method to three problems: system identification of dynamical systems, explaining the behaviour of a DQN agent and learning by demonstration in a human-robot interaction scenario. Our experimental results show that the π-machine can efficiently induce interpretable programs from individual data traces.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Predicting Future Agent Motions for Dynamic Environments Proceedings Article
Fabio Previtali, Alejandro Bordallo, Luca Iocchi, Subramanian Ramamoorthy
In: IEEE International Conference on Machine Learning and Applications (ICMLA), IEEE, 2017.
@inproceedings{Previtali2017predict,
title = {Predicting Future Agent Motions for Dynamic Environments},
author = {Fabio Previtali and Alejandro Bordallo and Luca Iocchi and Subramanian Ramamoorthy},
doi = {10.1109/ICMLA.2016.0024},
year = {2017},
date = {2017-02-02},
booktitle = {IEEE International Conference on Machine Learning and Applications (ICMLA)},
publisher = {IEEE},
abstract = {Understanding activities of people in a monitored environment is a topic of active research, motivated by applications requiring context-awareness. Inferring future agent motion is useful not only for improving tracking accuracy, but also for planning in an interactive motion task. Despite rapid advances in the area of activity forecasting, many state-of-the-art methods are still cumbersome for use in realistic robots. This is due to the requirement of having good semantic scene and map labelling, as well as assumptions made regarding possible goals and types of motion. Many emerging applications require robots with modest sensory and computational ability to robustly perform such activity forecasting in high density and dynamic environments. We address this by combining a novel multi-camera tracking method, efficient multi-resolution representations of state and a standard Inverse Reinforcement Learning (IRL) technique, to demonstrate performance that is better than the state-of-the-art in the literature. In this framework, the IRL method uses agent trajectories from a distributed tracker and estimates a reward function within a Markov Decision Process (MDP) model. This reward function can then be used to estimate the agent's motion in future novel task instances. We present empirical experiments using data gathered in our own lab and external corpora (VIRAT), based on which we find that our algorithm is not only efficiently implementable on a resource constrained platform but is also competitive in terms of accuracy with state-of-the-art alternatives (e.g., up to 20% better than the results reported in [1]).
},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
2016
Automatic configuration of ROS applications for near-optimal performance Proceedings Article
José Cano, Alejandro Bordallo, Vijay Nagarajan, Subramanian Ramamoorthy, Sethu Vijayakumar
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2016.
@inproceedings{cano206automatic,
title = {Automatic configuration of ROS applications for near-optimal performance},
author = {José Cano and Alejandro Bordallo and Vijay Nagarajan and Subramanian Ramamoorthy and Sethu Vijayakumar},
doi = {10.1109/IROS.2016.7759347},
year = {2016},
date = {2016-12-01},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
abstract = {The performance of a ROS application is a function of the individual performance of its constituent nodes. Since ROS nodes are typically configurable (parameterised), the specific parameter values adopted will determine the level of performance generated. In addition, ROS applications may be distributed across multiple computation devices, thus providing different options for node allocation. We address two configuration problems that the typical ROS user is confronted with: i) Determining parameter values and node allocations for maximising performance; ii) Determining node allocations for minimising hardware resources that can guarantee the desired performance. We formalise these problems with a mathematical model, a constrained form of a multiple-choice multiple knapsack problem. We propose a greedy algorithm for optimising each problem, using linear regression for predicting the performance of an individual ROS node over a continuum set of parameter combinations. We evaluate the algorithms through simulation and we validate them in a real ROS scenario, showing that the expected performance levels only deviate from the real measurements by an average of 2.5%.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
We, Anthrobot: Learning from Human Forms of Interaction and Esprit de Corps to Develop More Plural Social Robotics Journal Article
Luis de Miranda, Subramanian Ramamoorthy, Michael Rovatsos
In: Frontiers in Artificial Intelligence and Applications, vol. 290, pp. 48-59, 2016.
@article{miranda2016,
title = {We, Anthrobot: Learning from Human Forms of Interaction and Esprit de Corps to Develop More Plural Social Robotics},
author = {Luis de Miranda and Subramanian Ramamoorthy and Michael Rovatsos},
doi = {10.3233/978-1-61499-708-5-48},
year = {2016},
date = {2016-10-01},
journal = {Frontiers in Artificial Intelligence and Applications},
volume = {290},
pages = {48-59},
abstract = {We contend that our relationship with robots is too often seen within a universalistic and individualistic mind-frame. We propose a specific perspective in social robotics that we call anthrobotics. Anthrobotics starts with the choice to consider the human-machine intertwining as a dynamic union of more or less institutionalised collectives rather than separated discrete realities (individual humans, on one side, and discrete individualised machines on the other). We draw on our research in types of social interaction and esprit de corps to imagine more plural and harmonious forms of shared natural-artificial cognitive systems. We propose to look at four types of organised groups: conformative, autonomist, creative, and universalistic, that may provide guiding principles for the design of more diverse anthrobots.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Diversity-aware recommendation for human collectives Workshop
Pavlos Andreadis, Sofia Ceppi, Michael Rovatsos, Subramanian Ramamoorthy
2016.
@workshop{andrealis2016diversity,
title = {Diversity-aware recommendation for human collectives},
author = {Pavlos Andreadis and Sofia Ceppi and Michael Rovatsos and Subramanian Ramamoorthy},
url = {https://assistive-autonomy.ed.ac.uk/wp-content/uploads/2025/09/diversity16.pdf},
year = {2016},
date = {2016-08-29},
urldate = {2016-08-29},
abstract = {Sharing economy applications need to coordinate humans, each of whom may have different preferences over the provided service. Traditional approaches model this as a resource allocation problem and solve it by identifying matches between users and resources. These require knowledge of user preferences and, crucially, assume that users act deterministically or, equivalently, that each of them is expected to accept the proposed match. This assumption is unrealistic for applications like ridesharing and house sharing (such as Airbnb), where user coordination requires handling the diversity and uncertainty in human behavior.
We address this shortcoming by proposing a diversity-aware recommender system that leaves decision-making power to users but still assists them in coordinating their activities. We achieve this through taxation, which indirectly modifies users’ preferences over options by imposing a penalty on those that, if selected, are expected to lead to less favorable outcomes from the perspective of the collective. The framework we use to identify the options to recommend consists of three optimization steps, each centered on a mixed-integer linear program. By combining these three programs, we can compute solutions that balance the global goals of the collective with individual users’ interests. We demonstrate the effectiveness of our approach through two experiments in a simulated ridesharing scenario, showing: (a) significantly better coordination results with our approach compared to recommendations without taxation, (b) that we can propose a set of recommendations to users instead of imposing a single allocation without loss to the collective, and (c) that our system allows for an adaptive trade-off between conflicting criteria.},
howpublished = {Workshop on Diversity-aware Artificial Intelligence colocated with ECAI},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
We address this shortcoming by proposing a diversity-aware recommender system that leaves decision-making power to users but still assists them in coordinating their activities. We achieve this through taxation, which indirectly modifies users’ preferences over options by imposing a penalty on those that, if selected, are expected to lead to less favorable outcomes from the perspective of the collective. The framework we use to identify the options to recommend consists of three optimization steps, each centered on a mixed-integer linear program. By combining these three programs, we can compute solutions that balance the global goals of the collective with individual users’ interests. We demonstrate the effectiveness of our approach through two experiments in a simulated ridesharing scenario, showing: (a) significantly better coordination results with our approach compared to recommendations without taxation, (b) that we can propose a set of recommendations to users instead of imposing a single allocation without loss to the collective, and (c) that our system allows for an adaptive trade-off between conflicting criteria.
Estimating Activity at Multiple Scales using Spatial Abstractions Working paper
Majd Hawasly, Florian T. Pokorny, Subramanian Ramamoorthy
2016.
@workingpaper{hawasly2016estimatingactivitymultiplescales,
title = {Estimating Activity at Multiple Scales using Spatial Abstractions},
author = {Majd Hawasly and Florian T. Pokorny and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1607.07311},
year = {2016},
date = {2016-07-25},
urldate = {2016-01-01},
abstract = {Autonomous robots operating in dynamic environments must maintain beliefs over a hypothesis space that is rich enough to represent the activities of interest at different scales. This is important both in order to accommodate the availability of evidence at varying degrees of coarseness, such as when interpreting and assimilating natural instructions, but also in order to make subsequent reactive planning more efficient. We present an algorithm that combines a topology-based trajectory clustering procedure that generates hierarchically-structured spatial abstractions with a bank of particle filters at each of these abstraction levels so as to produce probability estimates over an agent's navigation activity that is kept consistent across the hierarchy. We study the performance of the proposed method using a synthetic trajectory dataset in 2D, as well as a dataset taken from AIS-based tracking of ships in an extended harbour area. We show that, in comparison to a baseline which is a particle filter that estimates activity without exploiting such structure, our method achieves a better normalised error in predicting the trajectory as well as better time to convergence to a true class when compared against ground truth.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Inverse eye tracking for intention inference and symbol grounding in human-robot collaboration Workshop
Svetlin Penkov, Alejandro Bordallo, Subramanian Ramamoorthy
2016.
@workshop{penkov2016inverse,
title = {Inverse eye tracking for intention inference and symbol grounding in human-robot collaboration},
author = {Svetlin Penkov and Alejandro Bordallo and Subramanian Ramamoorthy},
url = {https://www.research.ed.ac.uk/en/publications/inverse-eye-tracking-for-intention-inference-and-symbol-grounding
https://people.csail.mit.edu/cdarpino/RSS2016WorkshopHRcolla/abstracts/RSS16WS_07_InverseEyeTracking.pdf},
year = {2016},
date = {2016-06-18},
urldate = {2016-06-18},
abstract = {People and robots are required to cooperatively perform tasks which neither one could complete independently. Such collaboration requires efficient and intuitive human-robot interfaces which impose minimal overhead. We propose a humanrobot interface based on the use of eye tracking as a signal for intention inference. We achieve this by learning a probabilistic generative model of fixations conditioned on the task which the person is executing. Intention inference is then achieved through inversion of this model. Importantly, fixations depend on the location of objects or regions of interest in the environment. Thus we use the model to ground plan symbols to their representation in the environment. We report on early experimental results using mobile eye tracking glasses in a human-robot interaction setting, validating the usefulness of our model. We conclude with a discussion of how this model improves collaborative humanrobot assembly operations by enabling intuitive interactions.},
howpublished = {Workshop on Planning for Human-Robot Interaction in RSS},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Task Variant Allocation in Distributed Robotics Proceedings Article
Jose Cano, David R. White, Alejandro Bordallo, Ciaran McCreesh, Patrick Prosser, Jeremy Singer, Vijay Nagarajan
In: Robotics: Science and Systems (RSS), 2016.
@inproceedings{cano2016task,
title = {Task Variant Allocation in Distributed Robotics},
author = {Jose Cano and David R. White and Alejandro Bordallo and Ciaran McCreesh and Patrick Prosser and Jeremy Singer and Vijay Nagarajan
},
url = {https://www.roboticsproceedings.org/rss12/p45.html},
doi = {10.15607/RSS.2016.XII.045},
year = {2016},
date = {2016-06-01},
urldate = {2016-06-01},
booktitle = {Robotics: Science and Systems (RSS)},
abstract = {We consider the problem of assigning software pro- cesses (or tasks) to hardware processors in distributed robotics environments. We introduce the notion of a task variant, which supports the adaptation of software to specific hardware con- figurations. Task variants facilitate the trade-off of functional quality versus the requisite capacity and type of target execution processors. We formalise the problem of assigning task variants to processors as a mathematical model that incorporates typical con- straints found in robotics applications; the model is a constrained form of a multi-objective, multi-dimensional, multiple-choice knapsack problem. We propose and evaluate three different solution methods to the problem: constraint programming, a constructive greedy heuristic and a local search metaheuristic. Furthermore, we demonstrate the use of task variants in a real in- stance of a distributed interactive multi-agent navigation system, showing that our best solution method (constraint programming) improves the system's quality of service, as compared to the local search metaheuristic, the greedy heuristic and a randomised solution, by an average of 16%, 41% and 56% respectively.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Belief and truth in hypothesised behaviours Journal Article
Stefano V. Albrecht, Jacob W. Crandall, Subramanian Ramamoorthy
In: Artificial Intelligence Journal, vol. 235, pp. 63-94, 2016.
@article{albrecht2016belief,
title = {Belief and truth in hypothesised behaviours},
author = {Stefano V. Albrecht and Jacob W. Crandall and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1507.07688},
doi = {10.1016/j.artint.2016.02.004},
year = {2016},
date = {2016-06-01},
urldate = {2016-06-01},
journal = {Artificial Intelligence Journal},
volume = {235},
pages = {63-94},
abstract = {There is a long history in game theory on the topic of Bayesian or “rational” learning, in which each player maintains beliefs over a set of alternative behaviours, or types, for the other players. This idea has gained increasing interest in the artificial intelligence (AI) community, where it is used as a method to control a single agent in a system composed of multiple agents with unknown behaviours. The idea is to hypothesise a set of types, each specifying a possible behaviour for the other agents, and to plan our own actions with respect to those types which we believe are most likely, given the observed actions of the agents. The game theory literature studies this idea primarily in the context of equilibrium attainment. In contrast, many AI applications have a focus on task completion and payoff maximisation. With this perspective in mind, we identify and address a spectrum of questions pertaining to belief and truth in hypothesised types. We formulate three basic ways to incorporate evidence into posterior beliefs and show when the resulting beliefs are correct, and when they may fail to be correct. Moreover, we demonstrate that prior beliefs can have a significant impact on our ability to maximise payoffs in the long-term, and that they can be computed automatically with consistent performance effects. Furthermore, we analyse the conditions under which we are able complete our task optimally, despite inaccuracies in the hypothesised types. Finally, we show how the correctness of hypothesised types can be ascertained during the interaction via an automated statistical analysis.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Clustering Markov Decision Processes For Continual Transfer Working paper
M. M. Hassan Mahmud, Majd Hawasly, Benjamin Rosman, Subramanian Ramamoorthy
2016.
@workingpaper{mahmud2016clusteringmarkovdecisionprocesses,
title = {Clustering Markov Decision Processes For Continual Transfer},
author = {M. M. Hassan Mahmud and Majd Hawasly and Benjamin Rosman and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1311.3959},
year = {2016},
date = {2016-05-01},
urldate = {2016-01-01},
abstract = {We present algorithms to effectively represent a set of Markov decision processes (MDPs), whose optimal policies have already been learned, by a smaller source subset for lifelong, policy-reuse-based transfer learning in reinforcement learning. This is necessary when the number of previous tasks is large and the cost of measuring similarity counteracts the benefit of transfer. The source subset forms an `ϵ-net' over the original set of MDPs, in the sense that for each previous MDP Mp, there is a source Ms whose optimal policy has <ϵ regret in Mp. Our contributions are as follows. We present EXP-3-Transfer, a principled policy-reuse algorithm that optimally reuses a given source policy set when learning for a new MDP. We present a framework to cluster the previous MDPs to extract a source subset. The framework consists of (i) a distance dV over MDPs to measure policy-based similarity between MDPs; (ii) a cost function g(⋅) that uses dV to measure how good a particular clustering is for generating useful source tasks for EXP-3-Transfer and (iii) a provably convergent algorithm, MHAV, for finding the optimal clustering. We validate our algorithms through experiments in a surveillance domain.},
keywords = {},
pubstate = {published},
tppubtype = {workingpaper}
}
Exploiting causality for selective belief filtering in dynamic Bayesian network Journal Article
Stefano V. Albrecht, Subramanian Ramamoorthy
In: Journal of Artificial Intelligence Research (JAIR), vol. 55, 2016, (Exptended abstract published in IJCAI2017).
@article{albrecht2016explore,
title = {Exploiting causality for selective belief filtering in dynamic Bayesian network},
author = {Stefano V. Albrecht and Subramanian Ramamoorthy
},
url = {https://arxiv.org/pdf/1907.05850},
doi = {10.1613/jair.5044},
year = {2016},
date = {2016-04-28},
journal = {Journal of Artificial Intelligence Research (JAIR)},
volume = {55},
abstract = {Dynamic Bayesian networks (DBNs) are a general model for stochastic processes with partially observed states. Belief filtering in DBNs is the task of inferring the belief state (i.e. the probability distribution over process states) based on incomplete and noisy observations. This can be a hard problem in complex processes with large state spaces. In this article, we explore the idea of accelerating the filtering task by automatically exploiting causality in the process. We consider a specific type of causal relation, called passivity, which pertains to how state variables cause changes in other variables. We present the Passivity-based Selective Belief Filtering (PSBF) method, which maintains a factored belief representation and exploits passivity to perform selective updates over the belief factors. PSBF produces exact belief states under certain assumptions and approximate belief states otherwise, where the approximation error is bounded by the degree of uncertainty in the process. We show empirically, in synthetic processes with varying sizes and degrees of passivity, that PSBF is faster than several alternative methods while achieving competitive accuracy. Furthermore, we demonstrate how passivity occurs naturally in a complex system such as a multi-robot warehouse, and how PSBF can exploit this to accelerate the filtering task.},
note = {Exptended abstract published in IJCAI2017},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Bayesian policy reuse Journal Article
Benjamin Rosman, Majd Hawasly, Subramanian Ramamoorthy
In: Machine Learning, vol. 104, pp. 99-127, 2016.
@article{rosman2016bayesian,
title = {Bayesian policy reuse},
author = {Benjamin Rosman and Majd Hawasly and Subramanian Ramamoorthy},
url = {http://arxiv.org/abs/1507.07688},
doi = {10.1007/s10994-016-5547-y},
year = {2016},
date = {2016-02-22},
journal = {Machine Learning},
volume = {104},
pages = {99-127},
abstract = {A long-lived autonomous agent should be able to respond online to novel instances of tasks from a familiar domain. Acting online requires 'fast' responses, in terms of rapid convergence, especially when the task instance has a short duration, such as in applications involving interactions with humans. These requirements can be problematic for many established methods for learning to act. In domains where the agent knows that the task instance is drawn from a family of related tasks, albeit without access to the label of any given instance, it can choose to act through a process of policy reuse from a library, rather than policy learning from scratch. In policy reuse, the agent has prior knowledge of the class of tasks in the form of a library of policies that were learnt from sample task instances during an offline training phase. We formalise the problem of policy reuse, and present an algorithm for efficiently responding to a novel task instance by reusing a policy from the library of existing policies, where the choice is based on observed 'signals' which correlate to policy performance. We achieve this by posing the problem as a Bayesian choice problem with a corresponding notion of an optimal response, but the computation of that response is in many cases intractable. Therefore, to reduce the computation cost of the posterior, we follow a Bayesian optimisation approach and define a set of policy selection functions, which balance exploration in the policy library against exploitation of previously tried policies, together with a model of expected performance of the policy library on their corresponding task instances. We validate our method in several simulated domains of interactive, short-duration episodic tasks, showing rapid convergence in unknown task variations.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2015
Counterfactual reasoning about intent for interactive navigation in dynamic environments Bachelor Thesis
Alejandro Bordallo, Fabio Previtali, Nantas Nardelli, Subramanian Ramamoorthy
2015.
@bachelorthesis{Bordallo2015,
title = {Counterfactual reasoning about intent for interactive navigation in dynamic environments},
author = {Alejandro Bordallo and Fabio Previtali and Nantas Nardelli and Subramanian Ramamoorthy},
url = {https://www.youtube.com/watch?v=breBAyXkVhc},
doi = {0.1109/IROS.2015.7353783},
year = {2015},
date = {2015-12-17},
abstract = {Many modern robotics applications require robots to function autonomously in dynamic environments including other decision making agents, such as people or other robots. This calls for fast and scalable interactive motion planning. This requires models that take into consideration the other agent's intended actions in one's own planning. We present a real-time motion planning framework that brings together a few key components including intention inference by reasoning counterfactually about potential motion of the other agents as they work towards different goals. By using a light-weight motion model, we achieve efficient iterative planning for fluid motion when avoiding pedestrians, in parallel with goal inference for longer range movement prediction. This inference framework is coupled with a novel distributed visual tracking method that provides reliable and robust models for the current belief-state of the monitored environment. This combined approach represents a computationally efficient alternative to previously studied policy learning methods that often require significant offline training or calibration and do not yet scale to densely populated environments. We validate this framework with experiments involving multi-robot and human-robot navigation. We further validate the tracker component separately on much larger scale unconstrained pedestrian data sets.},
keywords = {},
pubstate = {published},
tppubtype = {bachelorthesis}
}
Recognising activities by jointly modelling actions and their effects PhD Thesis
Efstathios Vafeias
University of Edinburgh, 2015.
@phdthesis{Vafeias2015,
title = {Recognising activities by jointly modelling actions and their effects},
author = {Efstathios Vafeias},
url = {https://era.ed.ac.uk/handle/1842/14182},
year = {2015},
date = {2015-11-26},
school = {University of Edinburgh},
abstract = {With the rapid increase in adoption of consumer technologies, including inexpensive but powerful hardware, robotics appears poised at the cusp of widespread deployment in human environments. A key barrier that still prevents this is the machine understanding and interpretation of human activity, through a perceptual medium such as computer vision, or RBG-D sensing such as with the Microsoft Kinect sensor. This thesis contributes novel video-based methods for activity recognition. Specifically, the focus is on activities that involve interactions between the human user and objects in the environment. Based on streams of poses and object tracking, machine learning models are provided to recognize various of these interactions. The thesis main contributions are (1) a new model for interactions that explicitly learns the human-object relationships through a latent distributed representation, (2) a practical framework for labeling chains of manipulation actions in temporally extended activities and (3) an unsupervised sequence segmentation technique that relies on slow feature analysis and spectral clustering. These techniques are validated by experiments with publicly available data sets, such as the Cornell CAD-120 activity corpus which is one of the most extensive publicly available such data sets that is also annotated with ground truth information. Our experiments demonstrate the advantages of the proposed methods, over and above state of the art alternatives from the recent literature on sequence classifiers.},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Utilising policy types for effective ad hoc coordination in multiagent systems PhD Thesis
Stefano Vittorino Albrecht
University of Edinburgh, 2015.
@phdthesis{albrecht2015,
title = {Utilising policy types for effective ad hoc coordination in multiagent systems},
author = {Stefano Vittorino Albrecht
},
url = {http://hdl.handle.net/1842/16199},
year = {2015},
date = {2015-11-26},
school = {University of Edinburgh},
abstract = {This thesis is concerned with the ad hoc coordination problem. Therein, the goal is to design an autonomous agent which can achieve high flexibility and efficiency in a multiagent system that admits no prior coordination between the designed agent and the other agents. Flexibility describes the agent’s ability to solve its task with a variety of other agents in the system; efficiency is the relation between the agent’s payoffs and time needed to solve the task; and no prior coordination means that the agent does not a priori know how the other agents behave. This problem is relevant for a number of practical applications, including human-machine interaction tasks, such as adaptive user interfaces, robotic elderly care, and automated trading agents. Motivated by this problem, the central idea studied in this thesis is to utilise a set of policies, or types, to characterise the behaviour of other agents. Specifically, the idea is to reduce the complexity of the interaction problem by assuming that the other agents draw their latent type from some known or hypothesised space of types, and that the assignment of types is governed by an unknown distribution. Based on the current interaction history, we can form posterior beliefs about the relative likelihood of types. These beliefs, combined with the future predictions of the types, can then be used in a planning procedure to compute optimal responses. The aim of this thesis is to study the potential and limitations of this idea in the context of ad hoc coordination. We formulate the ad hoc coordination problem using a game-theoretic model called the stochastic Bayesian game. Based on this model, we derive a canonical algorithmic description of the idea outlined above, called Harsanyi-Bellman Ad Hoc Coordination (HBA). The practical potential of HBA is demonstrated in two case studies, including a human-machine experiment and a simulated logistics domain. We formulate basic ways to incorporate evidence (i.e. observed actions) into posterior beliefs and analyse the conditions under which the posterior beliefs converge to the true distribution of types. Furthermore, we study the impact of prior beliefs over types (that is, before any actions are observed) on the long-term performance of HBA, and show empirically that automatic methods can compute prior beliefs with consistent performance effects. For hypothesised (i.e. “guessed”) type spaces, we analyse the relations between hypothesised and true type spaces under which HBA is still guaranteed to solve its task, despite inaccuracies in hypothesised types. Finally, we show how HBA can perform an automatic statistical analysis to decide whether to reject its behavioural hypothesis, i.e. the combination of posterior beliefs and types.},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Topological trajectory classification with filtrations of simplicial complexes and persistent homology Journal Article
Florian T. Pokorny, Majd Hawasly, Subramanian Ramamoorthy
In: International Journal of Robotics Research, vol. 35, pp. 204-233, 2015.
@article{pokorny2015topoligical,
title = {Topological trajectory classification with filtrations of simplicial complexes and persistent homology},
author = {Florian T. Pokorny and Majd Hawasly and Subramanian Ramamoorthy},
doi = {10.1177/0278364915586713},
year = {2015},
date = {2015-08-21},
journal = {International Journal of Robotics Research},
volume = {35},
pages = {204-233},
abstract = {In this work, we present a sampling-based approach to trajectory classification which enables automated high-level reasoning about topological classes of trajectories. Our approach is applicable to general configuration spaces and relies only on the availability of collision free samples. Unlike previous sampling-based approaches in robotics which use graphs to capture information about the path-connectedness of a configuration space, we construct a multiscale approximation of neighborhoods of the collision free configurations based on filtrations of simplicial complexes. Our approach thereby extracts additional homological information which is essential for a topological trajectory classification. We propose a multiscale classification algorithm for trajectories in configuration spaces of arbitrary dimension and for sets of trajectories starting and ending in two fixed points. Using a cone construction, we then generalize this approach to classify sets of trajectories even when trajectory start and end points are allowed to vary in path-connected subsets. We furthermore show how an augmented filtration of simplicial complexes based on an arbitrary function on the configuration space, such as a costmap, can be defined to incorporate additional constraints. We present an evaluation of our approach in 2-, 3-, 4- and 6-dimensional configuration spaces in simulation and in real-world experiments using a Baxter robot and motion capture data.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Are You Doing What I Think You Are Doing? Criticising Uncertain Agent Models Proceedings Article
Stefano V. Albrecht, Subramanian Ramamoorthy
In: Uncertainty in Artificial Intelligence (UAI), 2015.
@inproceedings{Albrecht2015b,
title = {Are You Doing What I Think You Are Doing? Criticising Uncertain Agent Models},
author = {Stefano V. Albrecht and Subramanian Ramamoorthy },
url = {https://www.auai.org/uai2015/proceedings/papers/37.pdf},
year = {2015},
date = {2015-07-12},
urldate = {2015-07-12},
booktitle = {Uncertainty in Artificial Intelligence (UAI)},
abstract = {The key for effective interaction in many multiagent applications is to reason explicitly about the behaviour of other agents, in the form of a hypothesised behaviour. While there exist several methods for the construction of a behavioural hypothesis, there is currently no universal theory which would allow an agent to contemplate the correctness of a hypothesis. In this work, we present a novel algorithm which decides this question in the form of a frequentist hypothesis test. The algorithm allows for multiple metrics in the construction of the test statistic and learns its distribution during the interaction process, with asymptotic correctness guarantees. We present results from a comprehensive set of experiments, demonstrating that the algorithm achieves high accuracy and scalability at low computational costs},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Predicting actions using an adaptive probabilistic model of human decision behaviours Proceedings Article
Anthony Cruickshank, Subramanian Ramamoorthy, Richard Shillcock
In: Workshop Proceedings of the 23rd Conference on User Modeling, Adaptation, and Personalization (UMAP), 2015.
@inproceedings{Cruickshank2015,
title = {Predicting actions using an adaptive probabilistic model of human decision behaviours},
author = {Anthony Cruickshank and Subramanian Ramamoorthy and Richard Shillcock},
url = {https://ceur-ws.org/Vol-1388/poster_paper6.pdf},
year = {2015},
date = {2015-06-29},
urldate = {2015-06-29},
booktitle = {Workshop Proceedings of the 23rd Conference on User Modeling, Adaptation, and Personalization (UMAP)},
abstract = {Computer interfaces provide an environment that allows for multiple objectively optimal solutions but individuals will, over time, use a smaller number of subjectively optimal solutions, developed as habits that have been formed and tuned by repetition. Designing an interface agent to provide assistance in this environment thus requires not only knowledge of the objectively optimal solutions, but also recognition that users act from habit and that adaptation to an individual’s subjectively optimal solutions is required. We present a dynamic Bayesian network model for predicting a user’s actions by inferring whether a decision is being made by deliberation or through habit. The model adapts to individuals in a principled manner by incorporating observed actions using Bayesian probabilistic techniques. We demonstrate the model’s effectiveness using specific implementations of deliberation and habitual decision making, that are simple enough to transparently expose the mechanisms of our estimation procedure. We show that this implementation achieves > 90% prediction accuracy in a task with a large number of optimal solutions and a high degree of freedom in selecting actions.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
IRL-based prediction of goals for dynamic environments Workshop
Fabio Previtali, Alejandro Bordallo, Subramanian Ramamoorthy
2015.
@workshop{Previtali2015,
title = {IRL-based prediction of goals for dynamic environments},
author = {Fabio Previtali and Alejandro Bordallo and Subramanian Ramamoorthy
},
url = {https://www.research.ed.ac.uk/en/publications/irl-based-prediction-of-goals-for-dynamic-environments},
year = {2015},
date = {2015-05-26},
abstract = {Understanding activities of people in a monitored environment is a topic of active research, motivated by applications requiring context-awareness. Inferring future agent motion is useful not only for improving tracking accuracy, but also for planning in an interactive motion task. Despite rapid advances in the area of activity forecasting, many state-of-the-art methods are still cumbersome for use on realistic robots. This is due to the requirement of having good semantic scene and map labelling, as well as assumptions made regarding possible goals and types of motion. Many emerging applications require robots with modest sensory and computational ability to robustly perform such activity forecasting in high density and dynamic environments. We address this by combining a novel multi-camera tracking method, efficient multi-resolution representations of state and a standard Inverse Reinforcement Learning (IRL) technique, to demonstrate performance that is sometimes better than the state-of-the-art in the literature. In this framework, the IRL method uses agent trajectories from a distributed tracker, and the output reward functions, describing the agent’s goal-oriented navigation within a Markov Decision Process (MDP) model, can be used to estimate the agent’s set of possible future activities. We conclude with a quantitative evaluation comparing the proposed method against others from the literature.
},
howpublished = {Workshop on Machine Learning for Social Robotics colocated with ICRA},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
Action Priors for Learning Domain Invariances Journal Article
Benjamin Rosman, Subramanian Ramamoorthy
In: IEEE Transactions on Autonomous Mental Development, 2015.
@article{rosman2015action,
title = {Action Priors for Learning Domain Invariances},
author = {Benjamin Rosman and Subramanian Ramamoorthy},
doi = {10.1109/TAMD.2015.2419715},
year = {2015},
date = {2015-04-03},
journal = {IEEE Transactions on Autonomous Mental Development},
abstract = {An agent tasked with solving a number of different decision making problems in similar environments has an opportunity to learn over a longer timescale than each individual task. Through examining solutions to different tasks, it can uncover behavioral invariances in the domain, by identifying actions to be prioritized in local contexts, invariant to task details. This information has the effect of greatly increasing the speed of solving new problems. We formalise this notion as action priors, defined as distributions over the action space, conditioned on environment state, and show how these can be learnt from a set of value functions. We apply action priors in the setting of reinforcement learning, to bias action selection during exploration. Aggressive use of action priors performs context based pruning of the available actions, thus reducing the complexity of lookahead during search. We additionally define action priors over observation features, rather than states, which provides further flexibility and generalizability, with the additional benefit of enabling feature selection. Action priors are demonstrated in experiments in a simulated factory environment and a large random graph domain, and show significant speed ups in learning new tasks. Furthermore, we argue that this mechanism is cognitively plausible, and is compatible with findings from cognitive psychology.
},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
E-HBA: Using Action Policies for Expert Advice and Agent Typification Workshop
Stefano V. Albrecht, Jacob W. Crandall, Subramanian Ramamoorthy
2015.
@workshop{Albrecht2019,
title = {E-HBA: Using Action Policies for Expert Advice and Agent Typification},
author = {Stefano V. Albrecht and Jacob W. Crandall and Subramanian Ramamoorthy},
url = {https://arxiv.org/abs/1907.09810
https://assistive-autonomy.ed.ac.uk/wp-content/uploads/2025/09/mipc15app.pdf},
year = {2015},
date = {2015-01-25},
abstract = {Past research has studied two approaches to utilise predefined policy sets in repeated interactions: as experts, to dictate our own actions, and as types, to characterise the behaviour of other agents. In this work, we bring these complementary views together in the form of a novel meta-algorithm, called Expert-HBA (E-HBA), which can be applied to any expert algorithm that considers the average (or total) payoff an expert has yielded in the past. E-HBA gradually mixes the past payoff with a predicted future payoff, which is computed using the type-based characterisation. We present results from a comprehensive set of repeated matrix games, comparing the performance of several well-known expert algorithms with and without the aid of E-HBA. Our results show that E-HBA has the potential to significantly improve the performance of expert algorithms.},
howpublished = {Workshop on Multiagent Interaction without Prior Coordination colocated with AAAI},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
An Empirical Study on the Practical Impact of Prior Beliefs over Policy Types Proceedings Article
Stefano V. Albrecht, Jacob W. Crandall, Subramanian Ramamoorthy
In: Conference on Artificial Intelligence (AAAI), 2015.
@inproceedings{Albrecht2015c,
title = {An Empirical Study on the Practical Impact of Prior Beliefs over Policy Types},
author = {Stefano V. Albrecht and Jacob W. Crandall and Subramanian Ramamoorthy},
url = {https://aaai.org/papers/9426-an-empirical-study-on-the-practical-impact-of-prior-beliefs-over-policy-types
https://arxiv.org/abs/1907.05247
https://assistive-autonomy.ed.ac.uk/wp-content/uploads/2025/09/aaai15app.pdf},
year = {2015},
date = {2015-01-25},
urldate = {2015-01-25},
booktitle = {Conference on Artificial Intelligence (AAAI)},
abstract = {Many multiagent applications require an agent to learn quickly how to interact with previously unknown other agents. To address this problem, researchers have studied learning algorithms which compute posterior beliefs over a hypothesised set of policies, based on the observed actions of the other agents. The posterior belief is complemented by the prior belief, which specifies the subjective likelihood of policies before any actions are observed. In this paper, we present the first comprehensive empirical study on the practical impact of prior beliefs over policies in repeated interactions. We show that prior beliefs can have a significant impact on the long-term performance of such methods, and that the magnitude of the impact depends on the depth of the planning horizon. Moreover, our results demonstrate that automatic methods can be used to compute prior beliefs with consistent performance effects. This indicates that prior beliefs could be eliminated as a manual parameter and instead be computed automatically.
},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
A formalization of the coach problem Proceedings Article
G.Y.R. Schropp, J-J. Ch. Meyer, S. Ramamoorthy
In: RoboCup International Symposium, pp. 345 - 357, 2015.
@inproceedings{Schropp2025,
title = { A formalization of the coach problem},
author = {G.Y.R. Schropp and J-J. Ch. Meyer and S. Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2014/rcs14.pdf
https://link.springer.com/chapter/10.1007/978-3-319-18615-3_28},
year = {2015},
date = {2015-01-01},
urldate = {2025-01-01},
booktitle = { RoboCup International Symposium},
pages = {345 - 357},
abstract = {Coordination is an important aspect of multi-agent teamwork. In the context of robot soccer in the RoboCup Standard Platform League, our focus is on the coach as an external observer of the team, aiming to provide his teammates with effective tactical advice during matches. The coach problem can be approached from different angles: in order to adapt the behaviour of his teammates, he should at first be able to perform plan recognition on their observable actions. Furthermore, in providing them with appropriate advice, he should still adhere to the norms and regulations of the match to prevent penalties for his team. Also, when teammates’ profiles and attributes are unknown or the system is only partially observable, coordination should be more ‘ad hoc’ to ensure robustness of the Multi-Agent System (MAS). In this work, we present a formalization of the problem of designing a coach in robot soccer, employing a temporal deontic logical framework. The framework is based on agent organizations[10], in which social coordination and norms play an important part.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
2014
Policy space abstraction for a lifelong learning agent PhD Thesis
Majd Hawasly
University of Edinburgh, 2014.
@phdthesis{Hawasly2014,
title = {Policy space abstraction for a lifelong learning agent},
author = {Majd Hawasly },
url = {http://hdl.handle.net/1842/9931},
year = {2014},
date = {2014-11-27},
urldate = {2014-11-27},
school = {University of Edinburgh},
abstract = {This thesis is concerned with policy space abstractions that concisely encode alternative ways of making decisions; dealing with discovery, learning, adaptation and use of these abstractions. This work is motivated by the problem faced by autonomous agents that operate within a domain for long periods of time, hence having to learn to solve many different task instances that share some structural attributes. An example of such a domain is an autonomous robot in a dynamic domestic environment. Such environments raise the need for transfer of knowledge, so as to eliminate the need for long learning trials after deployment. Typically, these tasks would be modelled as sequential decision making problems, including path optimisation for navigation tasks, or Markov Decision Process models for more general tasks. Learning within such models often takes the form of online learning or reinforcement learning. However, handling issues such as knowledge transfer and multiple task instances requires notions of structure and hierarchy, and that raises several questions that form the topic of this thesis – (a) can an agent acquire such hierarchies in policies in an online, incremental manner, (b) can we devise mathematically rigorous ways to abstract policies based on qualitative attributes, (c) when it is inconvenient to employ prolonged trial and error learning, can we devise alternate algorithmic methods for decision making in a lifelong setting? The first contribution of this thesis is an algorithmic method for incrementally acquiring hierarchical policies. Working with the framework of options - temporally extended actions - in reinforcement learning, we present a method for discovering persistent subtasks that define useful options for a particular domain. Our algorithm builds on a probabilistic mixture model in state space to define a generalised and persistent form of ‘bottlenecks’, and suggests suitable policy fragments to make options. In order to continuously update this hierarchy, we devise an incremental process which runs in the background and takes care of proposing and forgetting options. We evaluate this framework in simulated worlds, including the RoboCup 2D simulation league domain. The second contribution of this thesis is in defining abstractions in terms of equivalence classes of trajectories. Utilising recently developed techniques from computational topology, in particular the concept of persistent homology, we show that a library of feasible trajectories could be retracted to representative paths that may be sufficient for reasoning about plans at the abstract level. We present a complete framework, starting from a novel construction of a simplicial complex that describes higher-order connectivity properties of a spatial domain, to methods for computing the homology of this complex at varying resolutions. The resulting abstractions are motion primitives that may be used as topological options, contributing a novel criterion for option discovery. This is validated by experiments in simulated 2D robot navigation, and in manipulation using a physical robot platform. Finally, we develop techniques for solving a family of related, but different, problem instances through policy reuse of a finite policy library acquired over the agent’s lifetime. This represents an alternative approach when traditional methods such as hierarchical reinforcement learning are not computationally feasible. We abstract the policy space using a non-parametric model of performance of policies in multiple task instances, so that decision making is posed as a Bayesian choice regarding what to reuse. This is one approach to transfer learning that is motivated by the needs of practical long-lived systems. We show the merits of such Bayesian policy reuse in simulated real-time interactive systems, including online personalisation and surveillance.},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Adapting interaction environments to diverse users through online action set selection Proceedings Article
M.M Hassan Mahmud, Benjamin Rosman, Subramanian Ramamoorthy, Pushmeet Kohli
In: AAAI Workshop on Machine Learning for Interactive Systems (AAAI-MLIS), pp. 1-7, 2014.
@inproceedings{Mahmud2014,
title = {Adapting interaction environments to diverse users through online action set selection},
author = {M.M Hassan Mahmud and Benjamin Rosman and Subramanian Ramamoorthy and Pushmeet Kohli },
url = {https://rad.inf.ed.ac.uk/data/publications/2014/mlis14_mahmud.pdf
https://www.research.ed.ac.uk/en/publications/adapting-interaction-environments-to-diverse-users-through-online},
year = {2014},
date = {2014-07-27},
booktitle = {AAAI Workshop on Machine Learning for Interactive Systems (AAAI-MLIS)},
number = {7},
pages = {1-7},
abstract = {Interactive interfaces are a common feature of many systems ranging from field robotics to video games. In most applications, these interfaces must be used by a heterogeneous set of users, with substantial variety in effectiveness with the same interface when configured differently. We address the issue of personalizing such an interface, adapting parameters to present the user with an environment that is optimal with respect to their individual traits - enabling that particular user to achieve their personal optimum. We introduce a new class of problem in interface personalization where the task of the adaptive interface is to choose the subset of actions of the full interface to present to the user. In formalising this problem, we model the user as a Markov decision process (MDP), wherein the transition dynamics within a task depends on the type (e.g., skill or dexterity) of the user, where the type parametrizes the MDP. The action set of the MDP is divided into disjoint set of actions, with different action-sets optimal for different type (transition dynamics). The task of the adaptive interface is then to choose the right action-set. Given this formalization, we present experiments with simulated and human users in a video game domain to show that (a) action set selection is an interesting class of problems (b) adaptively choosing the right action set improves performance over sticking to a fixed action set and (c) immediately applicable approaches such as bandits can be improved upon.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
On convergence and optimality of best-response learning with policy types in multiagent systems Proceedings Article
S.V. Albrecht, S. Ramamoorthy
In: Proceedings of the 30th Conference on Uncertainty in Artificial Intelligence, 2014.
@inproceedings{Albrecht2014,
title = {On convergence and optimality of best-response learning with policy types in multiagent systems},
author = {S.V. Albrecht and S. Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2014/uai14app.pdf
https://rad.inf.ed.ac.uk/data/publications/2014/uai14.pdf},
year = {2014},
date = {2014-07-23},
urldate = {2014-07-23},
booktitle = {Proceedings of the 30th Conference on Uncertainty in Artificial Intelligence},
abstract = {While many multiagent algorithms are designed for homogeneous systems (i.e. all agents are identical), there are important applications which require an agent to coordinate its actions without knowing a priori how the other agents behave. One method to make this problem feasible is to assume that the other agents draw their latent policy (or type) from a specific set, and that a domain expert could provide a specification of this set, albeit only a partially correct one. Algorithms have been proposed by several researchers to compute posterior beliefs over such policy libraries, which can then be used to determine optimal actions. In this paper, we provide theoretical guidance on two central design parameters of this method: Firstly, it is important that the user choose a posterior which can learn the true distribution of latent types, as otherwise suboptimal actions may be chosen. We analyse convergence properties of two existing posterior formulations and propose a new posterior which can learn correlated distributions. Secondly, since the types are provided by an expert, they may be inaccurate in the sense that they do not predict the agents’ observed actions. We provide a novel characterisation of optimality which allows experts to use efficient model checking algorithms to verify optimality of types.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Multiscale topological trajectory classification with persistent homology Proceedings Article
F. T. Pokorny, M. Hawasly, S. Ramamoorthy
In: Proceedings of Robotics: Science and Systems, 2014.
@inproceedings{Pokorny2014,
title = {Multiscale topological trajectory classification with persistent homology},
author = {F. T. Pokorny and M. Hawasly and S. Ramamoorthy },
url = {https://www.roboticsproceedings.org/rss10/p54.html
https://www.youtube.com/watch?v=jfz8e7lZnQI},
doi = {10.15607/RSS.2014.X.054},
year = {2014},
date = {2014-07-12},
urldate = {2014-07-12},
booktitle = {Proceedings of Robotics: Science and Systems},
abstract = {Topological approaches to studying equivalence classes of trajectories in a configuration space have recently received attention in robotics since they allow a robot to reason about trajectories at a high level of abstraction. While recent work has approached the problem of topological motion planning under the assumption that the configuration space and obstacles within it are explicitly described in a noise-free manner, we focus on trajectory classification and present a sampling-based approach which can handle noise, which is applicable to general configuration spaces and which relies only on the availability of collision free samples. Unlike previous sampling-based approaches in robotics which use graphs to capture information about the path-connectedness of a configuration space, we construct a multiscale approximation of neighborhoods of the collision free configurations based on filtrations of simplicial complexes. Our approach thereby extracts additional homological information which is essential for a topological trajectory classification. By computing a basis for the first persistent homology groups, we obtain a multiscale classification algorithm for trajectories in configuration spaces of arbitrary dimension. We furthermore show how an augmented filtration of simplicial complexes based on a cost function can be defined to incorporate additional constraints. We present an evaluation of our approach in 2, 3, 4 and 6 dimensional configuration spaces in simulation and using a Baxter robot.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning domain abstractions for long lived robots PhD Thesis
Rosman, Benjamin Saul
The University of Edinburgh, 2014.
@phdthesis{Rosman2014,
title = {Learning domain abstractions for long lived robots},
author = {Rosman and Benjamin Saul},
url = {http://hdl.handle.net/1842/9665},
year = {2014},
date = {2014-06-27},
school = {The University of Edinburgh},
abstract = {Recent trends in robotics have seen more general purpose robots being deployed in unstructured environments for prolonged periods of time. Such robots are expected to adapt to different environmental conditions, and ultimately take on a broader range of responsibilities, the specifications of which may change online after the robot has been deployed. We propose that in order for a robot to be generally capable in an online sense when it encounters a range of unknown tasks, it must have the ability to continually learn from a lifetime of experience. Key to this is the ability to generalise from experiences and form representations which facilitate faster learning of new tasks, as well as the transfer of knowledge between different situations. However, experience cannot be managed na¨ıvely: one does not want constantly expanding tables of data, but instead continually refined abstractions of the data – much like humans seem to abstract and organise knowledge. If this agent is active in the same, or similar, classes of environments for a prolonged period of time, it is provided with the opportunity to build abstract representations in order to simplify the learning of future tasks. The domain is a common structure underlying large families of tasks, and exploiting this affords the agent the potential to not only minimise relearning from scratch, but over time to build better models of the environment. We propose to learn such regularities from the environment, and extract the commonalities between tasks. This thesis aims to address the major question: what are the domain invariances which should be learnt by a long lived agent which encounters a range of different tasks? This question can be decomposed into three dimensions for learning invariances, based on perception, action and interaction. We present novel algorithms for dealing with each of these three factors. Firstly, how does the agent learn to represent the structure of the world? We focus here on learning inter-object relationships from depth information as a concise representation of the structure of the domain. To this end we introduce contact point networks as a topological abstraction of a scene, and present an algorithm based on support vector machine decision boundaries for extracting these from three dimensional point clouds obtained from the agent’s experience of a domain. By reducing the specific geometry of an environment into general skeletons based on contact between different objects, we can autonomously learn predicates describing spatial relationships. Secondly, how does the agent learn to acquire general domain knowledge? While the agent attempts new tasks, it requires a mechanism to control exploration, particularly when it has many courses of action available to it. To this end we draw on the fact that many local behaviours are common to different tasks. Identifying these amounts to learning “common sense” behavioural invariances across multiple tasks. This principle leads to our concept of action priors, which are defined as Dirichlet distributions over the action set of the agent. These are learnt from previous behaviours, and expressed as the prior probability of selecting each action in a state, and are used to guide the learning of novel tasks as an exploration policy within a reinforcement learning framework. Finally, how can the agent react online with sparse information? There are times when an agent is required to respond fast to some interactive setting, when it may have encountered similar tasks previously. To address this problem, we introduce the notion of types, being a latent class variable describing related problem instances. The agent is required to learn, identify and respond to these different types in online interactive scenarios. We then introduce Bayesian policy reuse as an algorithm that involves maintaining beliefs over the current task instance, updating these from sparse signals, and selecting and instantiating an optimal response from a behaviour library. This thesis therefore makes the following contributions. We provide the first algorithm for autonomously learning spatial relationships between objects from point cloud data. We then provide an algorithm for extracting action priors from a set of policies, and show that considerable gains in speed can be achieved in learning subsequent tasks over learning from scratch, particularly in reducing the initial losses associated with unguided exploration. Additionally, we demonstrate how these action priors allow for safe exploration, feature selection, and a method for analysing and advising other agents’ movement through a domain. Finally, we introduce Bayesian policy reuse which allows an agent to quickly draw on a library of policies and instantiate the correct one, enabling rapid online responses to adversarial conditions.},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Giving advice to agents with hidden goals Proceedings Article
Benjamin Rosman, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2014.
@inproceedings{Rosman2014b,
title = {Giving advice to agents with hidden goals},
author = {Benjamin Rosman and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2014/icra14rosman.pdf},
doi = { 10.1109/ICRA.2014.6907118},
year = {2014},
date = {2014-05-31},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {This paper considers the problem of providing advice to an autonomous agent when neither the behavioural policy nor the goals of that agent are known to the advisor. We present an approach based on building a model of “common sense” behaviour in the domain, from an aggregation of different users performing various tasks, modelled as MDPs, in the same domain. From this model, we estimate the normalcy of the trajectory given by a new agent in the domain, and provide behavioural advice based on an approximation of the trade-off in utility between potential benefits to the exploring agent and the costs incurred in giving this advice. This model is evaluated on a maze world domain by providing advice to different types of agents, and we show that this leads to a considerable and unanimous improvement in the completion rate of their tasks.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Joint classification of actions and object state changes with a latent variable discriminative model Proceedings Article
Efstathios Vafeias, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2014.
@inproceedings{Vafeias2014,
title = {Joint classification of actions and object state changes with a latent variable discriminative model},
author = {Efstathios Vafeias and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2014/eacl_eshky.pdf},
year = {2014},
date = {2014-05-31},
urldate = {2014-05-31},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {We present a technique to classify human actions that involve object manipulation. Our focus is to accurately distinguish between actions that are related in that the object's state changes define the essential differences. Our algorithm uses a latent variable conditional random field that allows for the modelling of spatio-temporal relationships between the human motion and the corresponding object state changes. Our approach involves a factored representation that better allows for the description of causal effects in the way human action causes object state changes. The utility of incorporating such structure in our model is that it enables more accurate classification of activities that could enable robots to reason about interaction, and to learn using a high level vocabulary that captures phenomena of interest. We present experiments involving the recognition of human actions, where we show that our factored representation achieves superior performance in comparison to alternate flat representations.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
On convergence and optimality of best-response learning with policy types in multiagent systems Proceedings Article
S.V. Albrecht, S. Ramamoorthy
In: Workshop on Adaptive Learning Agents (ALA), at the International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2014, (This paper is a self-contained workshop version of the UAI 2014 paper.).
@inproceedings{nokey,
title = {On convergence and optimality of best-response learning with policy types in multiagent systems},
author = {S.V. Albrecht and S. Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2014/ala14.pdf},
year = {2014},
date = {2014-05-05},
urldate = {2014-05-05},
booktitle = {Workshop on Adaptive Learning Agents (ALA), at the International Conference on Autonomous Agents and Multiagent Systems (AAMAS)},
abstract = {While many multiagent algorithms are designed for homogeneous systems (i.e. all agents are identical), there are important applications which require an agent to coordinate its actions without knowing a priori how the other agents behave. One method to make this problem feasible is to assume that the other agents draw their latent policy from a specific set, and that a domain expert could provide a specification of this set, albeit only a partially correct one. Algorithms have been proposed by several researchers to compute posterior beliefs over such policy libraries, which can then be used to determine optimal actions. In this paper, we provide theoretical guidance on two central design parameters of this method: Firstly, it is important that the user choose a posterior which can learn the true distribution of latent types, as otherwise suboptimal actions may be chosen. We analyse convergence properties of two existing posterior formulations and propose a new posterior which can learn correlated distributions. Secondly, since the types are provided by an expert, they may be inaccurate in the sense that they do not predict the agents’ observed actions. We provide a novel characterisation of optimality which allows experts to use efficient model checking algorithms to verify optimality of types.},
note = {This paper is a self-contained workshop version of the UAI 2014 paper.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
A generative model for user simulation in a spatial navigation domain Best Paper Proceedings Article
Aciel Eshky, Ben Allison, Subramanian Ramamoorthy, Mark Steedman
In: Conference of the European Chapter of the Association for Computational Linguistics (EACL), pp. 626–635, 2014.
@inproceedings{Eshky2014,
title = {A generative model for user simulation in a spatial navigation domain},
author = {Aciel Eshky and Ben Allison and Subramanian Ramamoorthy and Mark Steedman},
url = {https://rad.inf.ed.ac.uk/data/publications/2014/eacl_eshky.pdf},
doi = {10.3115/v1/E14-1066},
year = {2014},
date = {2014-04-01},
booktitle = {Conference of the European Chapter of the Association for Computational Linguistics (EACL)},
number = {10},
pages = {626–635},
abstract = {We propose the use of a generative model to simulate user behaviour in a novel task-oriented dialog domain, where user goals are spatial routes across artificial landscapes. We show how to derive an efficient feature-based representation of spatial goals, admitting exact inference and generalising to new routes. The use of a generative model allows us to capture a range of plausible behaviour given the same underlying goal. We evaluate intrinsically using held-out probability and perplexity, and find a substantial reduction in uncertainty brought by our spatial representation. We evaluate extrinsically in a human judgement task and find that our model’s behaviour does not differ significantly from the behaviour of real users.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
On user behaviour adaptation under interface change Proceedings Article
Benjamin Rosman, Subramanian Ramamoorthy, M.M. Hassan Mahmud, Pushmeet Kohli
In: International Conference on Intelligent User Interfaces (IUI), pp. 273 - 278, 2014.
@inproceedings{Rosman2014c,
title = {On user behaviour adaptation under interface change},
author = {Benjamin Rosman and Subramanian Ramamoorthy and M.M. Hassan Mahmud and Pushmeet Kohli},
url = {https://rad.inf.ed.ac.uk/data/publications/2014/iui_rosman.pdf},
doi = {10.1145/2557500.2557535},
year = {2014},
date = {2014-02-24},
urldate = {2014-02-24},
booktitle = { International Conference on Intelligent User Interfaces (IUI)},
pages = {273 - 278},
abstract = {Different interfaces allow a user to achieve the same end goal through different action sequences, e.g., command lines vs. drop down menus. Interface efficiency can be described in terms of a cost incurred, e.g., time taken, by the user in typical tasks. Realistic users arrive at evaluations of efficiency, hence making choices about which interface to use, over time, based on trial and error experience. Their choices are also determined by prior experience, which determines how much learning time is required. These factors have substantial effect on the adoption of new interfaces. In this paper, we aim at understanding how users adapt under interface change, how much time it takes them to learn to interact optimally with an interface, and how this learning could be expedited through intermediate interfaces. We present results from a series of experiments that make four main points: (a) different interfaces for accomplishing the same task can elicit significant variability in performance, (b) switching interfaces can result in adverse sharp shifts in performance, (c) subject to some variability, there are individual thresholds on tolerance to this kind of performance degradation with an interface, causing users to potentially abandon what may be a pretty good interface, and (d) our main result -- shaping user learning through the presentation of intermediate interfaces can mitigate the adverse shifts in performance while still enabling the eventual improved performance with the complex interface upon the user becoming suitably accustomed. In our experiments, human users use keyboard based interfaces to navigate a simulated ball through a maze. Our results are a first step towards interface adaptation algorithms that architect choice to accommodate personality traits of realistic users.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Latent-variable MDP models for adapting the interaction environment of diverse users Proceedings Article
M.M Hassan Mahmud, Benjamin Rosman, Pushmeet Kohli
In: Technical Report, University of Edinburgh, pp. 14, 2014, (Detailed technical version of Adapting Interaction Environments to Diverse Users through Online Action Set Selection (2014).).
@inproceedings{Mahmud2014b,
title = { Latent-variable MDP models for adapting the interaction environment of diverse users},
author = {M.M Hassan Mahmud and Benjamin Rosman and Pushmeet Kohli},
url = {https://rad.inf.ed.ac.uk/data/publications/2014/interaction%20tech%20report%20v2.pdf
https://www.research.ed.ac.uk/en/publications/latent-variable-mdp-models-for-adapting-the-interaction-environme},
year = {2014},
date = {2014-01-01},
booktitle = {Technical Report, University of Edinburgh},
pages = {14},
abstract = {Interactive interfaces are a common feature of many systems ranging from fieldrobotics to video games. In most applications, these interfaces must be used by aheterogeneous set of users, with substantial variety in effectiveness with the sameinterface when configured differently. We address the problem of personalizingsuch an interface, adapting parameters to present the user with an environmentthat is optimal with respect to their individual traits - enabling that particular userto achieve their personal optimum. We model the user as a parameterised Markov Decision Process (MDP), wherein the transition dynamics within a task depends on the latent personality traits (e.g., skill or dexterity) of the user. A key innovation is that we adapt at the level of action sets, picking a personalized optimal set of actions that the user should use. Our solution involves a latent variable formulation wherein we maintain beliefs over the latent type of users, which serves as a proxy for the hidden personality traits. This allows us to compute a Bayes optimal action set which when presented to the user allows them to achieve optimal performance. Our experiments, with real and simulated human participants, demonstrate that our personalized adaptive solution outperforms any alternate static solution, and also other adaptive algorithms such as EXP−3. Furthermore, we show that our algorithm is most useful under high diversity in user base, where the benefits of safe initialization and quick adaptation (properties our algorithm provably enjoys) are most pronounced.},
note = {Detailed technical version of Adapting Interaction Environments to Diverse Users through Online Action Set Selection (2014).},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
2013
Book review: "S. A. Levin (ed), Games, Groups and the Global Good" Journal Article
S. Ramamoorthy
In: Journal of the Operational Research Society , vol. 64, iss. 12, pp. 1867, 2013, ISSN: 0160-5682.
@article{nokey,
title = {Book review: "S. A. Levin (ed), Games, Groups and the Global Good"},
author = {S. Ramamoorthy },
url = {https://www.tandfonline.com/doi/full/10.1057/jors.2013.125},
doi = {10.1057/jors.2013.125},
issn = {0160-5682},
year = {2013},
date = {2013-12-01},
journal = {Journal of the Operational Research Society },
volume = {64},
issue = {12},
pages = {1867},
abstract = {Cooperation—how it comes about, how it is achieved and what its uses and implications are—constitutes an important challenge for the behavioural sciences. This book, an edited volume including contributions from eminent experts on this problem, is an authoritative reading on our present understanding of these issues. A particularly appealing feature of this book is the combination of breadth, in the number of different perspectives it manages to incorporate, with depth, in that even brief chapters are written in a way that provides valuable insight.
The book is organized by three major themes. It starts at the individual level by asking about the evolution of cooperation in a setting where there are self-interested actors. The second section moves on to issues of group formation and finally there is discussion of problems of the commons. This linear transition from the individual to the social organizes the nice diversity of viewpoints represented along the way.
As this is a book in a series in game theory, there are clearly numerous models that apply this theory. However, there is a significant variety—we find out in the two introductory chapters how some biological phenomena are nicely described by evolutionary game models and how cooperation can arise from the game dynamics. However, this leads up to more nuanced discussions about the realism of some aspects of these models and the roles of reputation and network structure in the evolution of cooperation. Similarly, even at the level of social systems, we see the discussion of strategic issues in negotiations and apologizing, showing us how agents could resolve difficult issues of cooperation, which is complemented by the discussion of the importance of mechanisms of trust and team level rather than individual reasoning. Indeed, the book covers even more ground than these modelling issues, especially in the second section, by taking on philosophical issues around the evolution and uses of moral systems, even taking on the role and evolution of religion. A final dimension of variety is defined by the combination of theoretical discussions of models, such as regarding the structure of matrix games, and empirical discussions such as based on data regarding city-level social behaviour.
Despite all this diversity, which is a virtue in a collection such as this one, there is indeed a common underlying theme. Much of this book addresses how a simple game theoretic viewpoint on coordination must be augmented by institutional mechanisms and individual-level attributes that play an important role in making cooperation possible. From this reviewer’s point of view, the potential readership and audience for this book could have been increased by the inclusion—in addition to the discussion of the state of the art and speculations about future directions—of some further tutorial content summarizing this specific theme independently from the expert essays. However, this is only a minor quibble that may be addressed by simply going back and reading specific chapters, and associated references, as the theme begins to clarify in the reader’s mind.
In summary, this is a very interesting and authoritative collection of chapters on the broad topic of cooperation, considering the problem at many levels of description and from a number of methodological standpoints. It should appeal to a wide audience including scientists or graduate students who wish to understand social behaviour through the lens of game theoretic modelling.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
The book is organized by three major themes. It starts at the individual level by asking about the evolution of cooperation in a setting where there are self-interested actors. The second section moves on to issues of group formation and finally there is discussion of problems of the commons. This linear transition from the individual to the social organizes the nice diversity of viewpoints represented along the way.
As this is a book in a series in game theory, there are clearly numerous models that apply this theory. However, there is a significant variety—we find out in the two introductory chapters how some biological phenomena are nicely described by evolutionary game models and how cooperation can arise from the game dynamics. However, this leads up to more nuanced discussions about the realism of some aspects of these models and the roles of reputation and network structure in the evolution of cooperation. Similarly, even at the level of social systems, we see the discussion of strategic issues in negotiations and apologizing, showing us how agents could resolve difficult issues of cooperation, which is complemented by the discussion of the importance of mechanisms of trust and team level rather than individual reasoning. Indeed, the book covers even more ground than these modelling issues, especially in the second section, by taking on philosophical issues around the evolution and uses of moral systems, even taking on the role and evolution of religion. A final dimension of variety is defined by the combination of theoretical discussions of models, such as regarding the structure of matrix games, and empirical discussions such as based on data regarding city-level social behaviour.
Despite all this diversity, which is a virtue in a collection such as this one, there is indeed a common underlying theme. Much of this book addresses how a simple game theoretic viewpoint on coordination must be augmented by institutional mechanisms and individual-level attributes that play an important role in making cooperation possible. From this reviewer’s point of view, the potential readership and audience for this book could have been increased by the inclusion—in addition to the discussion of the state of the art and speculations about future directions—of some further tutorial content summarizing this specific theme independently from the expert essays. However, this is only a minor quibble that may be addressed by simply going back and reading specific chapters, and associated references, as the theme begins to clarify in the reader’s mind.
In summary, this is a very interesting and authoritative collection of chapters on the broad topic of cooperation, considering the problem at many levels of description and from a number of methodological standpoints. It should appeal to a wide audience including scientists or graduate students who wish to understand social behaviour through the lens of game theoretic modelling.
Decision shaping and strategy learning in multi-robot interactions PhD Thesis
Valtazanos, Aris
The University of Edinburgh, 2013.
@phdthesis{Valtazanos2013,
title = {Decision shaping and strategy learning in multi-robot interactions},
author = {Valtazanos and Aris},
url = {http://hdl.handle.net/1842/8091},
year = {2013},
date = {2013-11-28},
urldate = {2013-11-28},
school = {The University of Edinburgh},
abstract = {Recent developments in robot technology have contributed to the advancement of autonomous behaviours in human-robot systems; for example, in following instructions received from an interacting human partner. Nevertheless, increasingly many systems are moving towards more seamless forms of interaction, where factors such as implicit trust and persuasion between humans and robots are brought to the fore. In this context, the problem of attaining, through suitable computational models and algorithms, more complex strategic behaviours that can influence human decisions and actions during an interaction, remains largely open. To address this issue, this thesis introduces the problem of decision shaping in strategic interactions between humans and robots, where a robot seeks to lead, without however forcing, an interacting human partner to a particular state. Our approach to this problem is based on a combination of statistical modeling and synthesis of demonstrated behaviours, which enables robots to efficiently adapt to novel interacting agents. We primarily focus on interactions between autonomous and teleoperated (i.e. human-controlled) NAO humanoid robots, using the adversarial soccer penalty shooting game as an illustrative example. We begin by describing the various challenges that a robot operating in such complex interactive environments is likely to face. Then, we introduce a procedure through which composable strategy templates can be learned from provided human demonstrations of interactive behaviours. We subsequently present our primary contribution to the shaping problem, a Bayesian learning framework that empirically models and predicts the responses of an interacting agent, and computes action strategies that are likely to influence that agent towards a desired goal. We then address the related issue of factors affecting human decisions in these interactive strategic environments, such as the availability of perceptual information for the human operator. Finally, we describe an information processing algorithm, based on the Orient motion capture platform, which serves to facilitate direct (as opposed to teleoperation-mediated) strategic interactions between humans and robots. Our experiments introduce and evaluate a wide range of novel autonomous behaviours, where robots are shown to (learn to) influence a variety of interacting agents, ranging from other simple autonomous agents, to robots controlled by experienced human subjects. These results demonstrate the benefits of strategic reasoning in human-robot interaction, and constitute an important step towards realistic, practical applications, where robots are expected to be not just passive agents, but active, influencing participants.},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Lifelong transfer learning with an option hierarchy Proceedings Article
Majd Hawasly, Subramanian Ramamoorthy
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2013.
@inproceedings{Hawasly2013,
title = { Lifelong transfer learning with an option hierarchy},
author = {Majd Hawasly and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2013/IROS2013.pdf
https://ieeexplore.ieee.org/document/6696523},
year = {2013},
date = {2013-11-03},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
abstract = {Many applications require autonomous agents to achieve quick responses to task instances drawn from a rich family of qualitatively-related tasks. We address the setting where the tasks share a state-action space and have the same qualitative objective but differ in dynamics. We adopt a transfer learning approach where common structure in previously-learnt policies, in the form of shared subtasks, is exploited to accelerate learning in subsequent ones. We use a probabilistic mixture model to describe regions in state space which are common to successful trajectories in different instances. Then, we extract policy fragments from previously-learnt policies that are specialised to these regions. These policy fragments are options, whose initiation and termination sets are automatically extracted from data by the mixture model. In novel task instances, these options are used in an SMDP learning process and option learning repeats over the resulting policy library. The utility of this method is demonstrated through experiments in a standard navigation environment and then in the RoboCup simulated soccer domain with opponent teams of different skill.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Motion generation with geodesic paths on learnt skill manifolds Proceedings Article
I. Havoutis, S. Ramamoorthy
In: Modeling, Simulation and Optimization of Bipedal Walking. Cognitive Systems Monographs, pp. 43-51, 2013.
@inproceedings{Havoutis2013b,
title = {Motion generation with geodesic paths on learnt skill manifolds},
author = {I. Havoutis and S. Ramamoorthy},
url = {https://link.springer.com/chapter/10.1007/978-3-642-36368-9_4},
year = {2013},
date = {2013-10-17},
booktitle = {Modeling, Simulation and Optimization of Bipedal Walking. Cognitive Systems Monographs},
volume = {18},
pages = {43-51},
abstract = {We present a framework for generating motions drawn from parametrized classes of motions and in response to goals chosen arbitrarily from a set. Our framework is based on learning a manifold representation of possible trajectories, from a set of example trajectories that are generated by a (computationally expensive) process of optimization. We show that these examples can be utilized to learn a manifold on which all feasible trajectories corresponding to a skill are the geodesics. This manifold is learned by inferring the local tangent spaces from data. Our main result is that this process allows us to define a flexible and computationally efficient motion generation procedure that comes close to the much more expensive computational optimization procedure in terms of accuracy while taking a small fraction of the time to perform a similar computation.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Latent space segmentation for mobile gait analysis Journal Article
Aris Valtazanos, D. K. Arvind, Subramanian Ramamoorthy
In: ACM Transactions on Embedded Computing Systems - Special Section on Wireless Health Systems, On-Chip and Off-Chip Network Architectures, vol. 12, iss. 4, no. 101, pp. 1-22, 2013, ISSN: 1539-9087.
@article{Valtazanos2013b,
title = { Latent space segmentation for mobile gait analysis},
author = {Aris Valtazanos and D. K. Arvind and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2013/acmtecs.pdf
https://dl.acm.org/doi/10.1145/2485984.2485989},
issn = {1539-9087},
year = {2013},
date = {2013-07-03},
urldate = {2013-07-03},
journal = {ACM Transactions on Embedded Computing Systems - Special Section on Wireless Health Systems, On-Chip and Off-Chip Network Architectures},
volume = {12},
number = {101},
issue = {4},
pages = {1-22},
abstract = {An unsupervised learning algorithm is presented for segmentation and evaluation of motion data from the on-body Orient wireless motion capture system for mobile gait analysis. The algorithm is model-free and operates on the latent space of the motion, by first aggregating all the sensor data into a single vector, and then modeling them on a low-dimensional manifold to perform segmentation. The proposed approach is contrasted to a basic, model-based algorithm, which operates directly on the joint angles computed by the Orient sensor devices. The latent space algorithm is shown to be capable of retrieving qualitative features of the motion even in the face of noisy or incomplete sensor readings.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
BRISK-based visual feature extraction for resource constrained robots Proceedings Article
J. D. Mankowitz, S. Ramamoorthy
In: RoboCup International Symposium, 2013.
@inproceedings{Mankowitz2013,
title = {BRISK-based visual feature extraction for resource constrained robots},
author = {J. D. Mankowitz and S. Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2013/BRISK-Based%20Visual%20Feature%20Extraction%20for%20Resource%20Constrained%20Robots.pdf},
year = {2013},
date = {2013-06-30},
urldate = {2013-06-30},
booktitle = {RoboCup International Symposium},
abstract = {We address the problem of devising vision-based feature extraction for the purpose of localisation on resource constrained robots that nonetheless require reasonably agile visual processing. We present modifications to a state-of-the-art Feature Extraction Algorithm (FEA) called Binary Robust Invariant Scalable Keypoints (BRISK) [8]. A key aspect of our contribution is the combined use of BRISK0 and U-BRISK as the FEA detector-descriptor pair for the purpose of localisation. We present a novel scoring function to find optimal parameters for this FEA. Also, we present two novel geometric matching constraints that serve to remove invalid interest point matches, which is key to keeping computations tractable. This work is evaluated using images captured on the Nao humanoid robot. In experiments, we show that the proposed procedure outperforms a previously implemented state-of-the-art vision-based FEA called 1D SURF (developed by the rUNSWift RoboCup SPL team), on the basis of accuracy and generalisation performance. Our experiments include data from indoor and outdoor environments, including a comparison to datasets such as based on Google Streetview.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Motion planning and reactive control on learnt skill manifolds Journal Article
Ioannis Havoutis, Subramanian Ramamoorthy
In: International Journal of Robotics Research, vol. 32, iss. 9-10, 2013.
@article{Havoutis2013,
title = {Motion planning and reactive control on learnt skill manifolds},
author = {Ioannis Havoutis and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2013/ijrr_havoutis.pdf
https://journals.sagepub.com/doi/10.1177/0278364913482016
},
year = {2013},
date = {2013-06-28},
urldate = {2013-06-28},
journal = {International Journal of Robotics Research},
volume = {32},
issue = {9-10},
abstract = {We address the problem of encoding and executing skills, i.e. motion tasks involving a combination of specifications regarding constraints and variability. We take an approach that is model-free in the sense that we do not assume an explicit and complete analytical specification of the task – which can be hard to obtain for many realistic robot systems. Instead, we learn an encoding of the skill from observations of an initial set of sample trajectories. This is achieved by encoding trajectories in a skill manifold which is learnt from data and generalizes in the sense that all trajectories on the manifold satisfy the constraints and allowable variability in the demonstrated samples. In new instances of the trajectory-generation problem, we restrict attention to geodesic trajectories on the learnt skill manifold, making computation more tractable. This procedure is also extended to accommodate dynamic obstacles and constraints, and to dynamically react against unexpected perturbations, enabling a form of model-free feedback control with respect to an incompletely modelled skill. We present experiments to validate this framework using various robotic systems – ranging from a three-link arm to a small humanoid robot – demonstrating significant computational improvements without loss of accuracy. Finally, we present a comparative evaluation of our framework against a state-of-the-art imitation-learning method.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Lifelong learning of structure in the space of policies Proceedings Article
Majd Hawasly, Subramanian Ramamoorthy
In: AAAI Spring Symposium on Lifelong Machine Learning, 2013, ISBN: 978-1-57735-602-7, (Preliminary version of the work published as: M. Hawasly, S. Ramamoorthy, Lifelong transfer learning with an option hierarchy, In Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2013.).
@inproceedings{Hawasly2013b,
title = {Lifelong learning of structure in the space of policies},
author = {Majd Hawasly and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2013/paper.pdf},
isbn = {978-1-57735-602-7},
year = {2013},
date = {2013-06-26},
urldate = {2013-06-26},
booktitle = {AAAI Spring Symposium on Lifelong Machine Learning},
abstract = {We address the problem faced by an autonomous agent that must achieve quick responses to a family of qualitativelyrelated tasks, such as a robot interacting with different types of human participants. We work in the setting where the tasks share a state-action space and have the same qualitative objective but differ in the dynamics and reward process. We adopt a transfer approach where the agent attempts to exploit common structure in learnt policies to accelerate learning in a new one. Our technique consists of a few key steps. First, we use a probabilistic model to describe the regions in state space which successful trajectories seem to prefer. Then, we extract policy fragments from previously-learnt policies for these regions as candidates for reuse. These fragments may be treated as options with corresponding domains and termination conditions extracted by unsupervised learning. Then, the set of reusable policies is used when learning novel tasks, and the process repeats. The utility of this method is demonstrated through experiments in the simulated soccer domain, where the variability comes from the different possible behaviours of opponent teams, and the agent needs to perform well against novel opponents.},
note = {Preliminary version of the work published as:
M. Hawasly, S. Ramamoorthy, Lifelong transfer learning with an option hierarchy,
In Proc. IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2013.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning in non-stationary MDPs as transfer learning Technical Report
M. M. H. Mahmud, S. Ramamoorthy
2013, (More detailed account of the material presented in: M. M. H. Mahmud, S. Ramamoorthy, Learning in non-stationary MDPs as transfer learning (Extended Abstract), In Proc. International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2013.).
@techreport{Mahmud2025,
title = {Learning in non-stationary MDPs as transfer learning},
author = {M. M. H. Mahmud and S. Ramamoorthy},
url = {https://assistive-autonomy.ed.ac.uk/wp-content/uploads/2025/11/transferDT.pdf},
year = {2013},
date = {2013-05-13},
urldate = {2013-05-13},
school = { The University of Edinburgh},
abstract = {In this paper we present a learning algorithm for a particular subclass of non-stationary environments where the learner is required
to interact with other agents. The behavior-policy of the agents are
determined by a latent variable that changes rarely, but can modify the agent policies drastically when it does change (like traffic conditions in a driving problem). This unpredictable change in
the latent variable results in non-stationarity. We frame this problem as a transfer learning in a particular subclass of MDPs where
each task/MDP requires the learner to learn to interact with opponent agents with fixed policies. Across the tasks, the state and action space remains the same (and is known) but the agent-policies
change. We transfer information from previous tasks to quickly infer the combined agent behavior policy in a new task after some
limited initial exploration, and hence rapidly learn an optimal/nearoptimal policy. We propose a transfer algorithm which given a collection of source behavior policies, eliminates the policies that do
not apply in the new task in time polynomial in the relevant parameters using novel a statistical test. We also perform experiments in
three interesting domains and show that our algorithm significantly
outperforms relevant algorithms.
},
note = {More detailed account of the material presented in:
M. M. H. Mahmud, S. Ramamoorthy, Learning in non-stationary MDPs as transfer learning (Extended Abstract),
In Proc. International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2013.},
keywords = {},
pubstate = {published},
tppubtype = {techreport}
}
to interact with other agents. The behavior-policy of the agents are
determined by a latent variable that changes rarely, but can modify the agent policies drastically when it does change (like traffic conditions in a driving problem). This unpredictable change in
the latent variable results in non-stationarity. We frame this problem as a transfer learning in a particular subclass of MDPs where
each task/MDP requires the learner to learn to interact with opponent agents with fixed policies. Across the tasks, the state and action space remains the same (and is known) but the agent-policies
change. We transfer information from previous tasks to quickly infer the combined agent behavior policy in a new task after some
limited initial exploration, and hence rapidly learn an optimal/nearoptimal policy. We propose a transfer algorithm which given a collection of source behavior policies, eliminates the policies that do
not apply in the new task in time polynomial in the relevant parameters using novel a statistical test. We also perform experiments in
three interesting domains and show that our algorithm significantly
outperforms relevant algorithms.
Learning in non-stationary MDPs as transfer learning (Extended Abstract) Proceedings Article
M.M.H. Mahmud, S. Ramamoorthy
In: International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pp. 1259 - 1260, 2013.
@inproceedings{Mahmud2013,
title = {Learning in non-stationary MDPs as transfer learning (Extended Abstract)},
author = {M.M.H. Mahmud and S. Ramamoorthy},
url = {https://rad.inf.ed.ac.uk/data/publications/2013/ext391-mahmud.pdf
https://dl.acm.org/doi/10.5555/2484920.2485172},
year = {2013},
date = {2013-05-06},
booktitle = {International Conference on Autonomous Agents and Multiagent Systems (AAMAS)},
pages = {1259 - 1260},
abstract = {In this paper we introduce the MDP-A model for addressing a particular sub-class of non-stationary environments where the learner is required to interact with other agents. The behavior-policies of the agents are determined by a latent variable that changes rarely, but can modify the agent policies drastically when it does change (like traffic conditions in a driving problem). This unpredictable change in the latent variable results in non-stationarity. We frame this problem as transfer learning in a particular subclass of MDPs, which we call MDPs-with-agents (MDP-A), where each task/MDP requires the learner to learn to interact with opponent agents with fixed policies. Across the tasks, the state and action space remains the same (and is known) but the agent-policies change. We transfer information from previous tasks to quickly infer the combined agent behavior policy in a new task after some limited initial exploration, and hence rapidly learn an optimal/near-optimal policy. We propose a transfer algorithm which given a collection of source behavior policies, eliminates the policies that do not apply in the new task in time polynomial in the relevant parameters using novel a statistical test. We also perform experiments in three interesting domains and show that our algorithm significantly outperforms relevant alternative algorithms.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems (Extended Abstract) Proceedings Article
Stefano V. Albrecht, Subramanian Ramamoorthy
In: AAMAS '13: Proceedings of the 2013 international conference on Autonomous agents and multi-agent systems , pp. 1155 - 1156, 2013.
@inproceedings{Albrecht2013,
title = {A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems (Extended Abstract)},
author = {Stefano V. Albrecht and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2013/aamas13_salbrecht.pdf
https://dl.acm.org/doi/10.5555/2484920.2485118},
year = {2013},
date = {2013-05-06},
booktitle = {AAMAS '13: Proceedings of the 2013 international conference on Autonomous agents and multi-agent systems
},
pages = {1155 - 1156},
abstract = {The ad hoc coordination problem is to design an ad hoc agent which is able to achieve optimal flexibility and efficiency in a multiagent system that admits no prior coordination between the ad hoc agent and the other agents. We conceptualise this problem formally as a stochastic Bayesian game in which the behaviour of a player is determined by its type. Based on this model, we derive a solution, called Harsanyi-Bellman Ad Hoc Coordination (HBA), which utilises a set of user-defined types to characterise players based on their observed behaviours. We evaluate HBA in the level-based foraging domain, showing that it outperforms several alternative algorithms using just a few user-defined types. We also report on a human-machine experiment in which the humans played Prisoner's Dilemma and Rock-Paper-Scissors against HBA and alternative algorithms. The results show that HBA achieved equal efficiency but a significantly higher welfare and winning rate.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Bayesian interaction shaping: learning to influence strategic interactions in mixed robotic domains Proceedings Article
Aris Valtazanos, Subramanian Ramamoorthy
In: International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pp. 63 - 70, 2013, ISBN: 978-1-4503-1993-7.
@inproceedings{Valtazanos2013d,
title = {Bayesian interaction shaping: learning to influence strategic interactions in mixed robotic domains},
author = {Aris Valtazanos and Subramanian Ramamoorthy },
url = {https://www.youtube.com/watch?v=5rYVhHZzHQQ
https://rad.inf.ed.ac.uk/data/publications/2013/aamas2013.pdf
https://dl.acm.org/doi/10.5555/2484920.2484934},
isbn = {978-1-4503-1993-7},
year = {2013},
date = {2013-05-06},
booktitle = {International Conference on Autonomous Agents and Multiagent Systems (AAMAS)},
pages = {63 - 70},
abstract = {Despite recent advances in getting autonomous robots to follow instructions from humans, strategically intelligent robot behaviours have received less attention. Strategic intelligence entails influence over the beliefs of other interacting agents, possibly adversarial. In this paper, we present a learning framework for strategic interaction shaping in physical robotic systems, where an autonomous robot must lead an unknown adversary to a desired joint state. Offline, we learn composable interaction templates, represented as shaping regions and tactics, from human demonstrations. Online, the agent empirically learns the adversary's responses to executed tactics, and the reachability of different regions. Interaction shaping is effected by selecting tactic sequences through Bayesian inference over the expected reachability of their traversed regions. We experimentally evaluate our approach in an adversarial soccer penalty task between NAO robots, by comparing an autonomous shaping robot with and against human-controlled agents. Results, based on 650 trials and a diverse group of 30 human subjects, demonstrate that the shaping robot performs comparably to the best human-controlled robots, in interactions with a heuristic autonomous adversary. The shaping robot is also shown to progressively improve its influence over a more challenging strategic adversary controlled by an expert human user.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Using wearable inertial sensors for posture and position tracking in unconstrained environments through learned translation manifolds Proceedings Article
A. Valtazanos, D.K. Arvind, S. Ramamoorthy
In: ACM/IEEE Conference on Information Processing in Sensor Networks (IPSN), pp. 241 - 252, 2013, ISBN: 978-1-4673-1997-6.
@inproceedings{Valtazanos2013c,
title = {Using wearable inertial sensors for posture and position tracking in unconstrained environments through learned translation manifolds},
author = {A. Valtazanos and D.K. Arvind and S. Ramamoorthy},
url = {https://doi.org/10.1145/2461381.2461411
https://rad.inf.ed.ac.uk/data/publications/2013/ipsn2013.pdf},
isbn = {978-1-4673-1997-6},
year = {2013},
date = {2013-04-08},
booktitle = {ACM/IEEE Conference on Information Processing in Sensor Networks (IPSN)},
pages = {241 - 252},
abstract = {Despite recent advances in 3-D motion capture, the problem of simultaneously tracking human posture and position in an unconstrained environment remains open. Optical systems provide both types of information, but are confined to a restricted area of capture. Inertial sensing alleviates this restriction, but at the expense of capturing only relative (postural) and not absolute (positional) information. In this paper, we propose an algorithm combining the relative merits of these systems to track both position and posture in challenging environments. Offline, we combine an optical (Kinect) and an inertial sensing (Orient-4) platform to learn a mapping from posture variations to translations, which we encode as a translation manifold. Online, the optical source is removed, and the learned mapping is used to infer positions using the postures computed by the inertial sensors. We first evaluate our approach in simulation, on motion sequences with ground-truth positions for error estimation. Then, the method is deployed on physical sensing platforms to track human subjects. The proposed algorithm is shown to yield a lower average cumulative error than comparable position tracking methods, such as double integration of accelerometer data, on both simulated and real sensory data, and in a variety of motions and capture settings.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Evaluating the effects of limited perception on interactive decisions in mixed robotic environments Proceedings Article
Aris Valtazanos, Subramanian Ramamoorthy
In: ACM/IEEE International Conference on Human-Robot Interaction (HRI), pp. 9 - 16, 2013.
@inproceedings{Valtazanos2013e,
title = {Evaluating the effects of limited perception on interactive decisions in mixed robotic environments},
author = {Aris Valtazanos and Subramanian Ramamoorthy},
url = {https://www.youtube.com/watch?v=6xi7WPgg46A
https://rad.inf.ed.ac.uk/data/publications/2013/hri2013.pdf
https://dl.acm.org/doi/10.5555/2447556.2447559
},
year = {2013},
date = {2013-03-03},
booktitle = {ACM/IEEE International Conference on Human-Robot Interaction (HRI)},
pages = {9 - 16},
abstract = {Many robotic applications feature a mixture of interacting teleoperated and autonomous robots. In several such domains, human operators must make decisions using very limited perceptual information, e.g. by viewing only the noisy camera feed of their robot. There are many interaction scenarios where such restricted visibility impacts teleoperation performance, and where the role of autonomous robots needs to be reinforced. In this paper, we report on an experimental study assessing the effects of limited perception on human decision making, in interactions between autonomous and teleoperated NAO robots, where subjects do not have prior knowledge of how other agents will respond to their decisions. We evaluate the performance of several subjects under varying perceptual constraints in two scenarios; a simple cooperative task requiring collaboration with an autonomous robot, and a more demanding adversarial task, where an autonomous robot is actively trying to outperform the human. Our results indicate that limited perception has minimal impact on user performance when the task is simple. By contrast, when the other agent becomes more strategic, restricted visibility has an adverse effect on most subjects, with the performance level even falling below that achieved by an autonomous robot with identical restrictions. Our results could inform decisions about the division of control between humans and robots in mixed-initiative systems, and in determining when autonomous robots should intervene to assist operators.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems Technical Report
Stefano V. Albrecht, Subramanian Ramamoorthy
2013, (More detailed account of the material presented in: S. Albrecht, S. Ramamoorthy, A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems (Extended Abstract), In Proc. International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2013.).
@techreport{Albrecht2013b,
title = {A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems},
author = {Stefano V. Albrecht and Subramanian Ramamoorthy },
url = {https://arxiv.org/abs/1506.01170},
year = {2013},
date = {2013-02-01},
school = { The University of Edinburgh},
abstract = {The ad hoc coordination problem is to design an autonomous agent which is able to achieve optimal flexibility and efficiency in a multiagent system with no mechanisms for prior coordination. We conceptualise this problem formally using a game-theoretic model, called the stochastic Bayesian game, in which the behaviour of a player is determined by its private information, or type. Based on this model, we derive a solution, called Harsanyi-Bellman Ad Hoc Coordination (HBA), which utilises the concept of Bayesian Nash equilibrium in a planning procedure to find optimal actions in the sense of Bellman optimal control. We evaluate HBA in a multiagent logistics domain called level-based foraging, showing that it achieves higher flexibility and efficiency than several alternative algorithms. We also report on a human-machine experiment at a public science exhibition in which the human participants played repeated Prisoner's Dilemma and Rock-Paper-Scissors against HBA and alternative algorithms, showing that HBA achieves equal efficiency and a significantly higher welfare and winning rate.},
note = {More detailed account of the material presented in:
S. Albrecht, S. Ramamoorthy, A game-theoretic model and best-response learning method for ad hoc coordination in multiagent systems (Extended Abstract),
In Proc. International Conference on Autonomous Agents and Multiagent Systems (AAMAS), 2013.},
keywords = {},
pubstate = {published},
tppubtype = {techreport}
}
Approximating a system using an abstract geometrical space Patent
J. M. Lewis, M. D. Cerna, K. P. Gupton, J. C. Nagle, Y. Rao, S. Ramamoorthy, D. R. Schmidt, B. R. Weidman, L. Wenzel, N. Zhang, B. Wang
8364446, 2013.
@patent{Lewis2013,
title = {Approximating a system using an abstract geometrical space},
author = {J. M. Lewis and M. D. Cerna and K. P. Gupton and J. C. Nagle and Y. Rao and S. Ramamoorthy and D. R. Schmidt and B. R. Weidman and L. Wenzel and N. Zhang and B. Wang},
year = {2013},
date = {2013-01-29},
number = {8364446},
keywords = {},
pubstate = {published},
tppubtype = {patent}
}
2012
What good are actions? Accelerating learning using learned action priors Best Paper Proceedings Article
Benjamin Rosman, Subramanian Ramamoorthy
In: International Conference on Development and Learning (ICDL-EpiRob), 2012.
@inproceedings{Rosman2012,
title = {What good are actions? Accelerating learning using learned action priors},
author = {Benjamin Rosman and Subramanian Ramamoorthy },
url = {https://ieeexplore.ieee.org/document/6400810?arnumber=6400810
https://rad.inf.ed.ac.uk/data/publications/2012/icdl12.pdf},
year = {2012},
date = {2012-11-07},
booktitle = {International Conference on Development and Learning (ICDL-EpiRob)},
abstract = {The computational complexity of learning in sequential decision problems grows exponentially with the number of actions available to the agent at each state. We present a method for accelerating this process by learning action priors that express the usefulness of each action in each state. These are learned from a set of different optimal policies from many tasks in the same state space, and are used to bias exploration away from less useful actions. This is shown to improve performance for tasks in the same domain but with different goals. We extend our method to base action priors on perceptual cues rather than absolute states, allowing the transfer of these priors between tasks with differing state spaces and transition functions, and demonstrate experimentally the advantages of learning with action priors in a reinforcement learning context.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Task variability in autonomous robots: Offline learning for online performance Proceedings Article
Majd Hawasly, Subramanian Ramamoorthy
In: Int. Workshop on Evolutionary and Reinforcement Learning for Autonomous Robot Systems (ERLARS), 2012.
@inproceedings{Hawasly2012,
title = {Task variability in autonomous robots: Offline learning for online performance},
author = {Majd Hawasly and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2012/ERLARS-2012-camera-ready.pdf},
year = {2012},
date = {2012-10-01},
urldate = {2012-10-01},
booktitle = {Int. Workshop on Evolutionary and Reinforcement Learning for Autonomous Robot Systems (ERLARS)},
number = {8},
abstract = {A problem faced by autonomous robots is that of achieving quick, efficient operation in unseen variations of their tasks after experiencing a subset of these variations sampled offline at training time. We model the task variability in terms of a family of MDPs differing in transition dynamics and reward processes. In the case when it is not possible to experiment in the new world, e.g., in real-time situations, a policy for novel instances may be defined by averaging over the policies of the offline instances. This would be suboptimal in the general case, and for this we propose an alternate model that draws on the methodology of hierarchical reinforcement learning, wherein we learn partial policies for partial goals (subtasks) in the offline MDPs, in the form of options, and we treat solving a novel MDP as one of sequential composition of partial policies. Our procedure utilises a modified version of option interruption for control switching where the interruption signal is acquired from offline experience. We also show that desirable performance advantages can be attained in situations where the task can be decomposed into concurrent subtasks, allowing us to devise an alternate control structure that emphasises flexible switching and concurrent use of policy fragments. We demonstrate the utility of these ideas using example gridworld domains with variability in task.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Motion planning for self-reconfiguring robotic systems PhD Thesis
Larkworthy, Thomas James
The University of Edinburgh, 2012.
@phdthesis{Larkworthy2012,
title = {Motion planning for self-reconfiguring robotic systems},
author = {Larkworthy and Thomas James},
url = {http://hdl.handle.net/1842/6256},
year = {2012},
date = {2012-06-25},
urldate = {2012-06-25},
school = {The University of Edinburgh},
abstract = {Robots that can actively change morphology offer many advantages over fixed shape, or monolithic, robots: flexibility, increased maneuverability and modularity. So called self-reconfiguring systems (SRS) are endowed with a shape changing ability enabled by an active connection mechanism. This mechanism allows a mechanical link to be engaged or disengaged between two neighboring robotic subunits. Through utilization of embedded joints to change the geometry plus the connection mechanism to change the topology of the kinematics, a collection of robotic subunits can drastically alter the overall kinematics. Thus, an SRS is a large robot comprised of many small cooperating robots that is able to change its morphology on demand. By design, such a system has many and variable degrees of freedom (DOF). To gain the benefits of self-reconfiguration, the process of morphological change needs to be controlled in response to the environment. This is a motion planning problem in a high dimensional configuration space. This problem is complex because each subunit only has a few internal DOFs, and each subunit's range of motion depends on the state of its connected neighbors. Together with the high dimensionality, the problem may initially appear to be intractable, because as the number of subunits grow, the state space expands combinatorially. However, there is hope. If individual robotic subunits are identical, then there will exist some form of regularity in the resulting state space of the conglomerate. If this regularity can be exploited, then there may exist tractable motion planning algorithms for self-reconfiguring system. Existing approaches in the literature have been successful in developing algorithms for specific SRSs. However, it is not possible to transfer one motion planning algorithm onto another system. SRSs share a similar form of regularity, so one might hope that a tool from mathematical literature would identify the common properties that are exploitable for motion planning. So, while there exists a number of algorithms for certain subsets of possible SRS instantiations, there is no general motion planning methodology applicable to all SRSs. In this thesis, firstly, the best existing general motion planning techniques were evaluated to the SRS motion planning problem. Greedy search, simulated annealing, rapidly exploring random trees and probabilistic roadmap planning were found not to scale well, requiring exponential computation time, as the number of subunits in the SRS increased. The planners performance was limited by the availability of a good general purpose heuristic. There does not currently exist a heuristic which can accurately guide a path through the search space toward a far away goal configuration. Secondly, it is shown that a computationally efficient reconfiguration algorithms do exist by development of an efficient motion planning algorithm for an exemplary SRS, the Claytronics formulation of the Hexagonal Metamorphic Robot (HMR). The developed algorithm was able to solve a randomly generated shape-to-shape planning task for the SRS in near linear time as the number of units in the configuration grew. Configurations containing 20,000 units were solvable in under ten seconds on modest computational hardware. The key to the success of the approach was discovering a subspace of the motion planning space that corresponded with configurations with high mobility. Plans could be discovered in this sub-space much more readily because the risk of the search entering a blind alley was greatly reduced. Thirdly, in order to extract general conclusions, the efficient subspace, and other efficient subspaces utilized in other works, are analyzed using graph theoretic methods. The high mobility is observable as an increase in the state space's Cheeger constant, which can be estimated with a local sampling procedure. Furthermore, state spaces associated with an efficient motion planning algorithm are well ordered by the graph minor relation. These qualitative observations are discoverable by machine without human intervention, and could be useful components in development of a general purpose SRS motion planner compiler.},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Motion planning and reactive control on learnt skill manifolds PhD Thesis
Ioannis Havoutis
The University of Edinburgh, 2012.
@phdthesis{Havoutis2012,
title = {Motion planning and reactive control on learnt skill manifolds},
author = {Ioannis Havoutis},
url = {http://hdl.handle.net/1842/5864},
year = {2012},
date = {2012-06-25},
urldate = {2012-06-25},
school = {The University of Edinburgh},
abstract = {We propose a novel framework for motion planning and control that is based on a manifold encoding of the desired solution set. We present an alternate, model-free, approach to path planning, replanning and control. Our approach is founded on the idea of encoding the set of possible trajectories as a skill manifold, which can be learnt from data such as from demonstration. We describe the manifold representation of skills, a technique for learning from data and a method for generating trajectories as geodesics on such manifolds. We extend the trajectory generation method to handle dynamic obstacles and constraints. We show how a state metric naturally arises from the manifold encoding and how this can be used for reactive control in an on-line manner. Our framework tightly integrates learning, planning and control in a computationally efficient representation, suitable for realistic humanoid robotic tasks that are defined by skill specifications involving high-dimensional nonlinear dynamics, kinodynamic constraints and non-trivial cost functions, in an optimal control setting. Although, in principle, such problems can be handled by well understood analytical methods, it is often difficult and expensive to formulate models that enable the analytical approach. We test our framework with various types of robotic systems – ranging from a 3-link arm to a small humanoid robot – and show that the manifold encoding gives significant improvements in performance without loss of accuracy. Furthermore, we evaluate the framework against a state-of-the-art imitation learning method. We show that our approach, by learning manifolds of robotic skills, allows for efficient planning and replanning in changing environments, and for robust and online reactive control.},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
Automatically generating a second graphical program based on a first graphical program Patent
S. Ramamoorthy, L. Wenzel, G. O. Morrow, M. L. Santori, J. C. Limroth, R. Kudukoli, R. E. Dye
8205188, 2012.
@patent{Ramamoorthy2012a,
title = {Automatically generating a second graphical program based on a first graphical program},
author = {S. Ramamoorthy and L. Wenzel and G. O. Morrow and M. L. Santori and J. C. Limroth and R. Kudukoli and R. E. Dye},
year = {2012},
date = {2012-06-19},
number = {8205188},
keywords = {},
pubstate = {published},
tppubtype = {patent}
}
NaOISIS: A 3-D behavioural simulator for the NAO humanoid robot Proceedings Article
Aris Valtazanos, Subramanian Ramamoorthy
In: RoboCup International Symposium, pp. 341 - 352, 2012, ISSN: 0302-9743.
@inproceedings{Valtazanos2012,
title = {NaOISIS: A 3-D behavioural simulator for the NAO humanoid robot},
author = {Aris Valtazanos and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2011/simpaper.pdf
https://dl.acm.org/doi/10.5555/2554542.2554575},
issn = {0302-9743},
year = {2012},
date = {2012-06-18},
booktitle = {RoboCup International Symposium},
volume = {7416},
number = {12},
pages = {341 - 352},
abstract = {We present NaOISIS, a three-dimensional behavioural simulator for the NAO humanoid robot, aimed at designing and testing physically plausible strategic behaviours for multi-agent soccer teams. NaOISIS brings together features from both physical three-dimensional simulators that model robot dynamics and interactions, and two- dimensional environments that are used to design sophisticated team coordination strategies, which are however difficult to implement in practice. To this end, the focus of our design has been on the accurate modeling of the simulated agents’ perceptual limitations and their compatibility with the corresponding capabilities of the real NAO robot. The simulator features presented in this paper suggest that NaOISIS can be used as a rapid prototyping tool for implementing behavioural algorithms for the NAO, and testing them in the context of matches between simulated agents.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Induction and learning of finite-state controllers from simulation (Extended Abstract) Proceedings Article
M. Leonetti, L. Iocchi, S. Ramamoorthy
In: International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pp. 1203 - 1204, 2012.
@inproceedings{Leonetti2012,
title = {Induction and learning of finite-state controllers from simulation (Extended Abstract)},
author = {M. Leonetti and L. Iocchi and S. Ramamoorthy},
url = {https://dl.acm.org/doi/10.5555/2343896.2343922
https://rad.inf.ed.ac.uk/data/publications/2012/aamas12-leonetti.pdf},
year = {2012},
date = {2012-06-04},
booktitle = {International Conference on Autonomous Agents and Multiagent Systems (AAMAS)},
volume = {3},
pages = {1203 - 1204},
abstract = {We propose a method to generate agent controllers, represented as state machines, to act in partially observable environments. Such controllers are used to constrain the search space, applying techniques from Hierarchical Reinforcement Learning. We define a multi-step process, in which a simulator is employed to generate possible traces of execution. Those traces are then utilized to induce a non-deterministic state machine, that represents all reasonable behaviors, given the approximate models and planners used in simulation. The state machine will have multiple possible choices in some of its states. Those states are choice points, and we defer the learning of those choices to the deployment of the agent in the actual environment. The controller obtained can therefore adapt to the actual environment, limiting the search space in a sensible way.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Comparative evaluation of MAL algorithms in a diverse set of ad hoc team problems Proceedings Article
Stefano V. Albrecht, Subramanian Ramamoorthy
In: International Conference on Autonomous Agents and Multiagent Systems (AAMAS), pp. 349 - 356, 2012.
@inproceedings{Albrecht2012,
title = {Comparative evaluation of MAL algorithms in a diverse set of ad hoc team problems},
author = {Stefano V. Albrecht and Subramanian Ramamoorthy },
url = {https://dl.acm.org/doi/10.5555/2343576.2343626
https://assistive-autonomy.ed.ac.uk/wp-content/uploads/2025/10/aamas12_salbrecht.pdf},
year = {2012},
date = {2012-06-04},
booktitle = {International Conference on Autonomous Agents and Multiagent Systems (AAMAS)},
volume = {1},
pages = {349 - 356},
abstract = {This paper is concerned with evaluating different multiagent learning (MAL) algorithms in problems where individual agents may be heterogenous, in the sense of utilizing different learning strategies, without the opportunity for prior agreements or information regarding coordination. Such a situation arises in ad hoc team problems, a model of many practical multiagent systems applications. Prior work in multiagent learning has often been focussed on homogeneous groups of agents, meaning that all agents were identical and a priori aware of this fact. Also, those algorithms that are specifically designed for ad hoc team problems are typically evaluated in teams of agents with fixed behaviours, as opposed to agents which are adapting their behaviours. In this work, we empirically evaluate five MAL algorithms, representing major approaches to multiagent learning but originally developed with the homogeneous setting in mind, to understand their behaviour in a set of ad hoc team problems. All teams consist of agents which are continuously adapting their behaviours. The algorithms are evaluated with respect to a comprehensive characterisation of repeated matrix games, using performance criteria that include considerations such as attainment of equilibrium, social welfare and fairness. Our main conclusion is that there is no clear winner. However, the comparative evaluation also highlights the relative strengths of different algorithms with respect to the type of performance criteria, e.g., social welfare vs. attainment of equilibrium.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Macroscopes: models for collective decision making Proceedings Article
Subramanian Ramamoorthy, András Z. Salamon, Rahul Santhanam
In: Collective Intelligence, 2012.
@inproceedings{Ramamoorthy2012,
title = {Macroscopes: models for collective decision making},
author = {Subramanian Ramamoorthy and András Z. Salamon and Rahul Santhanam},
url = {https://arxiv.org/abs/1204.3860
https://rad.inf.ed.ac.uk/data/publications/2012/macroscopes.pdf},
year = {2012},
date = {2012-04-18},
urldate = {2012-04-18},
booktitle = {Collective Intelligence},
abstract = {We introduce a new model of collective decision making, when a global decision needs to be made but the parties only possess partial information, and are unwilling (or unable) to first create a globalcomposite of their local views. Our macroscope model captures two key features of many real-world problems: allotment structure (how access to local information is apportioned between parties, including overlaps between the parties) and the possible presence of meta-information (what each party knows about the allotment structure of the overall problem). Using the framework of communication complexity, we formalize the efficient solution of a macroscope. We present general results about the macroscope model, and also results that abstract the essential computational operations underpinning practical applications, including in financial markets and decentralized sensor networks. We illustrate the computational problem inherent in real-world collective decision making processes using results for specific functions, involving detecting a change in state (constant and step functions), and computing statistical properties (the mean).},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Converting a first graphical program into an intermediate abstract representation for new graphical program generation Patent
S. Ramamoorthy, L. Wenzel, G. O. Morrow, M. L. Santori, J. C. Limroth, R. Kudukoli, R. E. Dye
8146007, 2012.
@patent{Ramamoorthy2012b,
title = {Converting a first graphical program into an intermediate abstract representation for new graphical program generation},
author = {S. Ramamoorthy and L. Wenzel and G. O. Morrow and M. L. Santori and J. C. Limroth and R. Kudukoli and R. E. Dye},
year = {2012},
date = {2012-03-27},
number = {8146007},
keywords = {},
pubstate = {published},
tppubtype = {patent}
}
A multitask representation using reusable local policy templates Proceedings Article
Benjamin Rosman, Subramanian Ramamoorthy
In: AAAI Spring Symposium on Designing Intelligent Robots: Reintegrating AI, 2012.
@inproceedings{Rosman2012b,
title = {A multitask representation using reusable local policy templates},
author = {Benjamin Rosman and Subramanian Ramamoorthy},
url = {https://rad.inf.ed.ac.uk/data/publications/2012/aaaidir12.pdf},
year = {2012},
date = {2012-03-26},
urldate = {2012-03-26},
booktitle = {AAAI Spring Symposium on Designing Intelligent Robots: Reintegrating AI},
abstract = {Constructing robust controllers to perform tasks in large, continually changing worlds is a difficult problem. A long-lived agent placed in such a world could be required to perform a variety of different tasks. For this to be possible, the agent needs to be able to abstract its experiences in a reusable way. This paper addresses the problem of online multitask decision making in such complex worlds, with inherent incompleteness in models of change. A fully general version of this problem is intractable but many interesting domains are rendered manageable by the fact that all instances of tasks may be described using a finite set of qualitatively meaningful contexts. We suggest an approach to solving the multitask problem through decomposing the domain into a set of capabilities based on these local contexts. Capabilities resemble the options of hierarchical reinforcement learning, but provide robust behaviours capable of achieving some subgoal with the associated guarantee of achieving at least a particular aspiration level of performance. This enables using these policies within a planning framework, and they become a level of abstraction which factorises an otherwise large domain into task-independent sub-problems, with well-defined interfaces between the perception, control and planning problems. This is demonstrated in a stochastic navigation example, where an agent reaches different goals in different world instances without relearning.
},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
2011
Learning finite state controllers from simulation Proceedings Article
Matteo Leonetti, Luca Iocchi, Subramanian Ramamoorthy
In: European Workshop on Reinforcement Learning (EWRL-9), 2011.
@inproceedings{Leonetti2011b,
title = {Learning finite state controllers from simulation},
author = {Matteo Leonetti and Luca Iocchi and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2011/ewrl2011_submission_361.pdf
https://www.research.ed.ac.uk/en/publications/learning-finite-state-controllers-from-simulation},
year = {2011},
date = {2011-09-25},
urldate = {2011-09-25},
booktitle = {European Workshop on Reinforcement Learning (EWRL-9)},
number = {12},
abstract = {We propose a methodology to automatically generate agent controllers, represented as state machines, to act in partially observable environments. We define a multi-step process, in which increasingly accurate models - generally too complex to be used for planning - are employed to generate possible traces of execution by simulation. Those traces are then utilized to induce a state machine, that represents all reasonable behaviors, given the approximate models and planners previously used. The state machine will have multiple possible choices in some of its states. Those states are choice points, and we defer the learning of those choices to the deployment of the agent in the real environment. The controller obtained can therefore adapt to the actual environment, limiting the search space in a sensible way.
},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Intent inference and strategic escape in multi-robot games with physical limitations and uncertainty Proceedings Article
Aris Valtazanos, Subramanian Ramamoorthy
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2011.
@inproceedings{Valtazanos2025,
title = {Intent inference and strategic escape in multi-robot games with physical limitations and uncertainty},
author = {Aris Valtazanos and Subramanian Ramamoorthy},
url = {https://rad.inf.ed.ac.uk/data/publications/2011/iros2011.pdf
https://ieeexplore.ieee.org/document/6094754},
year = {2011},
date = {2011-09-25},
urldate = {2025-09-25},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
abstract = {Many multi-robot decision problems present autonomous agents with a dual challenge: the accurate egocentric estimation of the state and strategy of their adversaries, in the face of physical limitations and sensory uncertainty. Although these are clearly difficult constraints on the capabilities of an autonomous robot, this is also an opportunity for exploiting the corresponding limitations of the adversary. In this paper, we propose a decision making framework for physically constrained multi-robot games, using a combination of probabilistic and game-theoretic tools. We first present the Reachable Set Particle Filter, an adversary state estimation algorithm combining data-driven approximation with dynamical constraints. Then, we use game-theoretic notions to formulate a strategy estimation framework that progressively learns and exploits the adversary's behaviour. We evaluate our framework in a series of robotic soccer games between robots with varying sensing and strategic capabilities. Our results demonstrate that the combination of probabilistic modeling and strategic reasoning leads to significant improvements in performance robustness, while flexibly adapting to dynamic adversaries.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Reinforcement learning through global stochastic search in N-MDPs Proceedings Article
Matteo Leonetti, Luca Iocchi, Subramanian Ramamoorthy
In: European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD), pp. 326–340, 2011.
@inproceedings{Leonetti2011,
title = {Reinforcement learning through global stochastic search in N-MDPs},
author = {Matteo Leonetti and Luca Iocchi and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2011/ECML2011.pdf
https://link.springer.com/chapter/10.1007/978-3-642-23783-6_21},
year = {2011},
date = {2011-09-05},
booktitle = {European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD)},
pages = {326–340},
abstract = {Reinforcement Learning (RL) in either fully or partially observable domains usually poses a requirement on the knowledge representation in order to be sound: the underlying stochastic process must be Markovian. In many applications, including those involving interactions between multiple agents (e.g., humans and robots), sources of uncertainty affect rewards and transition dynamics in such a way that a Markovian representation would be computationally very expensive. An alternative formulation of the decision problem involves partially specified behaviors with choice points. While this reduces the complexity of the policy space that must be explored - something that is crucial for realistic autonomous agents that must bound search time - it does render the domain Non-Markovian. In this paper, we present a novel algorithm for reinforcement learning in Non-Markovian domains. Our algorithm, Stochastic Search Monte Carlo, performs a global stochastic search in policy space, shaping the distribution from which the next policy is selected by estimating an upper bound on the value of each action. We experimentally show how, in challenging domains for RL, high-level decisions in Non-Markovian processes can lead to a behavior that is at least as good as the one learned by traditional algorithms, and can be achieved with significantly fewer samples.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Learning spatial relationships between objects Journal Article
Benjamin Rosman, Subramanian Ramamoorthy
In: International Journal of Robotics Research, vol. 30, iss. 11, 2011.
@article{Rosman2011,
title = {Learning spatial relationships between objects},
author = {Benjamin Rosman and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2011/RosmanIJRR11.pdf
https://journals.sagepub.com/doi/10.1177/0278364911408155},
year = {2011},
date = {2011-07-07},
journal = {International Journal of Robotics Research},
volume = {30},
issue = {11},
abstract = {Although a manipulator must interact with objects in terms of their full complexity, it is the qualitative structure of the objects in an environment and the relationships between them which define the composition of that environment, and allow for the construction of efficient plans to enable the completion of various elaborate tasks. In this paper we present an algorithm which redescribes a scene in terms of a layered representation, from labeled point clouds of the objects in the scene. The representation includes a qualitative description of the structure of the objects, as well as the symbolic relationships between them. This is achieved by constructing contact point networks of the objects, which are topological representations of how each object is used in that particular scene, and are based on the regions of contact between objects. We demonstrate the performance of the algorithm, by presenting results from the algorithm tested on a database of stereo images. This shows a high percentage of correctly classified relationships, as well as the discovery of interesting topological features. This output provides a layered representation of a scene, giving symbolic meaning to the inter-object relationships useful for subsequent commonsense reasoning and decision making.},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
Online motion planning for multi-robot interaction using composable reachable sets Proceedings Article
Aris Valtazanos, Subramanian Ramamoorthy
In: RoboCup International Symposium, pp. 186–197, 2011.
@inproceedings{Valtazanos2011,
title = {Online motion planning for multi-robot interaction using composable reachable sets},
author = {Aris Valtazanos and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2011/rsc.pdf
https://dl.acm.org/doi/abs/10.5555/2554542.2554561},
year = {2011},
date = {2011-06-18},
urldate = {2011-06-18},
booktitle = {RoboCup International Symposium},
pages = {186–197},
abstract = {This paper presents an algorithm for autonomous online path planning in uncertain, possibly adversarial, and partially observable environments. In contrast to many state-of-the-art motion planning approaches, our focus is on decision making in the presence of adversarial agents who may be acting strategically but whose exact behaviour is difficult to model precisely. Our algorithm first computes a collection of reachable sets with respect to a family of possible strategies available to the adversary. Online, the agent uses these sets as composable behavioural templates, in conjunction with a particle filter to maintain the current belief on the adversary’s strategy. In partially observable environments, this yields significant performance improvements over state-of-the-art planning algorithms. We present empirical results to this effect using a robotic soccer simulator, highlighting the applicability of our implementation against adversaries with varying capabilities. We also demonstrate experiments on the NAO humanoid robots, in the context of different
collision-avoidance scenarios.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
collision-avoidance scenarios.
Book review: "B. Øksendal, A. Sulem, Applied Stochastic Control of Jump Diffusions" Journal Article
S. Ramamoorthy
In: J. Operational Research Society, vol. 62, iss. 1, pp. 246 - 250, 2011.
@article{Ramamoorthy2011,
title = {Book review: "B. Øksendal, A. Sulem, Applied Stochastic Control of Jump Diffusions"},
author = {S. Ramamoorthy},
url = {https://rad.inf.ed.ac.uk/data/publications/2011/JORSreview.pdf
https://www.tandfonline.com/doi/abs/10.1057/jors.2010.154
},
year = {2011},
date = {2011-01-01},
journal = {J. Operational Research Society},
volume = {62},
issue = {1},
pages = { 246 - 250},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
A characterization of the reconfiguration space of self-reconfiguring robotic systems Journal Article
Tom Larkworthy, Subramanian Ramamoorthy
In: Robotica (Special Issue on Self-X Systems), vol. 29, iss. 1, pp. 73-85, 2011.
@article{Larkworthy2011,
title = {A characterization of the reconfiguration space of self-reconfiguring robotic systems},
author = {Tom Larkworthy and Subramanian Ramamoorthy
},
url = {https://rad.inf.ed.ac.uk/data/publications/2011/Robotica2010Preprint.pdf
https://doi.org/10.1017/S0263574710000718},
year = {2011},
date = {2011-01-01},
journal = {Robotica (Special Issue on Self-X Systems)},
volume = {29},
issue = {1},
pages = {73-85},
abstract = {Motion planning for self-reconfiguring robots can be made efficient by exploiting potential reductions to suitably large subspaces. However, there are no general techniques for identifying suitable restrictions that have a positive effect on planning efficiency. We present two approaches to understanding the structure that is required of the subspaces, which leads to improvement in efficiency of motion planning. This work is presented in the context of a specific motion planning procedure for a hexagonal metamorphic robot. First, we use ideas from spectral graph theory – empirically estimating the algebraic connectivity of the state space – to show that the HMR model is better structured than many alternative motion catalogs. Secondly, using ideas from graph minor theory, we show that the infinite sequence of subspaces generated by configurations containing increasing numbers of subunits is well ordered, indicative of regularity of the space as complexity increases. We hope that these principles could inform future algorithm design for many different types of self-reconfiguring robotics problems.
},
keywords = {},
pubstate = {published},
tppubtype = {article}
}
2010
Controlling humanoid robots in topology coordinates Proceedings Article
Edmond S.L. Ho, Taku Komura, Subramanian Ramamoorthy, Sethu Vijayakumar
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2010.
@inproceedings{Ho2010,
title = {Controlling humanoid robots in topology coordinates},
author = {Edmond S.L. Ho and Taku Komura and Subramanian Ramamoorthy and Sethu Vijayakumar },
url = {https://rad.inf.ed.ac.uk/data/publications/2010/ho-IROS2010.pdf
https://ieeexplore.ieee.org/document/5652787
},
year = {2010},
date = {2010-10-18},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
abstract = {This paper presents an approach to the control of humanoid robot motion, e.g., holding another robot or tangled interactions involving multiple limbs, in a space defined by `topology coordinates'. The constraints of tangling can be linearized at every frame of motion synthesis, and can be used together with constraints such as defined by the Zero Moment Point, Center of Mass, inverse kinematics and angular momentum for computing the postures by a linear programming procedure. We demonstrate the utility of this approach using the simulator for the Nao humanoid robot. We show that this approach enables us to synthesize complex motion, such as tangling, very efficiently.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Constrained geodesic trajectory generation on learnt skill manifolds. Best Paper Proceedings Article
Ioannis Havoutis, Subramanian Ramamoorthy
In: IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2010.
@inproceedings{Havoutis2010,
title = {Constrained geodesic trajectory generation on learnt skill manifolds.},
author = {Ioannis Havoutis and Subramanian Ramamoorthy},
url = {https://rad.inf.ed.ac.uk/data/publications/2010/1385.pdf
https://ieeexplore.ieee.org/document/5651957},
year = {2010},
date = {2010-10-18},
booktitle = {IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS)},
abstract = {This paper addresses the problem of compactly encoding a continuous family of trajectories corresponding to a robotic skill, and using this representation for the purpose of constrained trajectory generation in an environment with many (possibly dynamic) obstacles. With a skill manifold that is learnt from data, we show that constraints can be naturally handled within an iterative process of minimizing the total geodesic path length and curvature over the manifold. We demonstrate the utility of this process with two examples. Firstly, a three-link arm whose joint space and corresponding skill manifold can be explicitly visualized. Then, we demonstrate how this procedure can be used to generate constrained walking motions in a humanoid robot.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Comparative study of segmentation of periodic motion data for mobile gait analysis. Proceedings Article
Aris Valtazanos, D. K. Arvind, S. Ramamoorthy
In: Wireless Health Conference, pp. 145 - 154, 2010.
@inproceedings{Valtazanos2010,
title = {Comparative study of segmentation of periodic motion data for mobile gait analysis.},
author = {Aris Valtazanos and D. K. Arvind and S. Ramamoorthy},
url = {https://rad.inf.ed.ac.uk/data/publications/2010/comparativestudy.pdf
https://dl.acm.org/doi/10.1145/1921081.1921099},
year = {2010},
date = {2010-10-05},
booktitle = {Wireless Health Conference},
pages = {145 - 154},
abstract = {Two approaches are presented and compared for segmenting motion data from on-body Orient wireless motion capture system for mobile gait analysis. The first is a basic, model-based algorithm which operates directly on the joint angles computed by the Orient sensor devices. The second is a model-free, Latent Space algorithm, which first aggregates all the sensor data, and then embeds them in a low-dimensional manifold to perform segmentation. The two approaches are compared for segmenting four different styles of walking, and then applied in a hospital-based clinical study for analysing the motion of elderly patients recovering from a fall.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
A heuristic strategy for learning in partially observable and non-Markovian domains Proceedings Article
M. Leonetti, S. Ramamoorthy
In: International Workshop on Evolutionary and Reinforcement Learning for Autonomous Robot Systems (ERLARS 2010), 2010.
@inproceedings{Leonetti2010,
title = {A heuristic strategy for learning in partially observable and non-Markovian domains},
author = {M. Leonetti and S. Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2010/erlars10-leonetti.pdf
https://www.erlars.org/2010/ERLARS2010-Proceedings.pdf},
year = {2010},
date = {2010-08-16},
booktitle = {International Workshop on Evolutionary and Reinforcement Learning for Autonomous Robot Systems (ERLARS 2010)},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Graph minor analysis of reconfiguring state spaces Proceedings Article
Thomas Larkworthy, Subramanian Ramamoorthy
In: Workshop on Modular Robotics: State of the Art, IEEE International Conference on Robotics and Automation, 2010, 2010.
@inproceedings{Larkworthy2025,
title = {Graph minor analysis of reconfiguring state spaces},
author = {Thomas Larkworthy and Subramanian Ramamoorthy },
url = {https://www.research.ed.ac.uk/en/a/graph-minor-analysis-of-reconfiguration-state-spaces},
year = {2010},
date = {2010-05-04},
urldate = {2025-05-04},
booktitle = {Workshop on Modular Robotics: State of the Art, IEEE International Conference on Robotics and Automation, 2010},
abstract = {Efficiently overcoming difficult motion constraints is the prime problem in development of efficient motion planning algorithms for self-reconfiguring systems (SRSs). Metamodularization, and other related techniques, deal with the problem by adding further constraints in a way that simplifies planning. If Rn denotes a raw state space for configurations containing n sub-units, and Cn a further constrained version of Rn then Rn le Cn where le denotes the graph minor relation. Often the choice of Cn is ad hoc (although made on clever intuitions). We wish to study whether there are principles that may guide this choice. We demonstrate one such principle, that is planning is tractable, e.g. in meta-modularized sub-spaces, when Cn le Cn+1, which captures a smooth increase in state-space complexity as more modules are added.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
An efficient algorithm for self-reconfiguration planning in a modular robot Proceedings Article
Tom Larkworthy, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2010.
@inproceedings{Larkworthy2010,
title = {An efficient algorithm for self-reconfiguration planning in a modular robot},
author = {Tom Larkworthy and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2010/1383.pdf
https://ieeexplore.ieee.org/document/5509482},
year = {2010},
date = {2010-05-03},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {An efficient planning algorithm for the hexagonal metamorphic self-reconfiguring system (SRS) is presented. Empirically, the algorithm achieves an time complexity of O(n) averaged over random problem instances. The planning algorithm is capable of solving approximately 97% of planning tasks in the general state space of configurations containing less than 20,000 units. The state space is divided into two classes according to planning efficiency. The configurations belonging to the first class permit an Euler tour to be wrapped around the robotic aggregate. The existence of the Euler tour implies units are free to move around the perimeter of the SRS. Planning between configurations in this class can be performed in O(n) using a specialized planning algorithm. The set of Euler tour configurations span a large volume of the general state space of the hexagonal SRS. A second specialized planning algorithm plans from a general configuration to a nearby Euler tour configuration. While planning in the general configuration state space is computationally harder, the distance required to plan is short. Thus, the combination of both algorithms allows us to efficiently plan for a large proportion of possible reconfiguration tasks for the hexagonal metamorphic robot.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Geodesic trajectory generation on learnt skill manifolds. Proceedings Article
Ioannis Havoutis, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2010.
@inproceedings{Havoutis2010b,
title = {Geodesic trajectory generation on learnt skill manifolds.},
author = {Ioannis Havoutis and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2010/1372.pdf
https://ieeexplore.ieee.org/document/5509819
},
year = {2010},
date = {2010-05-03},
booktitle = { IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {Humanoid robots are appealing due to their inherent dexterity. However, these potential benefits may only be realized if the corresponding motion synthesis procedure is suitably flexible. This paper presents a flexible trajectory generation algorithm that utilizes a geometric representation of humanoid skills (e.g., walking) - in the form of skill manifolds. These manifolds are learnt from demonstration data that may be obtained from off-line optimization algorithms (or a human expert).We demonstrate that this model may be used to produce approximately optimal motion plans as geodesics over the manifold and that this allows us to effectively generalize from a limited training set. We demonstrate the effectiveness of our approach on a simulated 3-link planar arm, and then the more challenging example of a physical 19-DoF humanoid robot. We show that our algorithm produces a close approximation of the much more computationally intensive optimization procedure used to generate the data. This allows us to present experimental results for fast motion planning on a realistic - variable step length, width and height - walking task on a humanoid robot.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
A game theoretic procedure for learning hierarchically structured strategies. Proceedings Article
Benjamin Rosman, Subramanian Ramamoorthy
In: IEEE International Conference on Robotics and Automation (ICRA), 2010.
@inproceedings{Rosman2010,
title = {A game theoretic procedure for learning hierarchically structured strategies.},
author = {Benjamin Rosman and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2010/icra10.pdf
https://ieeexplore.ieee.org/document/5509632},
year = {2010},
date = {2010-05-03},
booktitle = {IEEE International Conference on Robotics and Automation (ICRA)},
abstract = {This paper addresses the problem of acquiring a hierarchically structured robotic skill in a nonstationary environment. This is achieved through a combination of learning primitive strategies from observation of an expert, and autonomously synthesising composite strategies from that basis. Both aspects of this problem are approached from a game theoretic viewpoint, building on prior work in the area of multiplicative weights learning algorithms. The utility of this procedure is demonstrated through simulation experiments motivated by the problem of autonomous driving. We show that this procedure allows the agent to come to terms with two forms of uncertainty in the world - continually varying goals (due to oncoming traffic) and nonstationarity of optimisation criteria (e.g., driven by changing navigability of the road). We argue that this type of factored task specification and learning is a necessary ingredient for robust autonomous behaviour in a “large-world” setting.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
2009
Geodesic trajectory generation on learnt skill manifolds Proceedings Article
Ioannis Havoutis, Subramanian Ramamoorthy
In: Modeling, Simulation and Optimization of Bipedal Walking Workshop, IEEE-RAS International Conference on Humanoid Robots, 2009.
@inproceedings{Havoutis2009b,
title = {Geodesic trajectory generation on learnt skill manifolds},
author = {Ioannis Havoutis and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2009/HR_HumanoidsWkshp09.pdf},
year = {2009},
date = {2009-12-07},
booktitle = {Modeling, Simulation and Optimization of Bipedal Walking Workshop, IEEE-RAS International Conference on Humanoid Robots},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
General motion planning methods for self-reconfiguration planning Proceedings Article
Thomas Larkworthy, Gillian Hayes, Subramanian Ramamoorthy
In: Towards Autonomous Robotic Systems, 2009.
@inproceedings{Larkworthy2009,
title = {General motion planning methods for self-reconfiguration planning},
author = {Thomas Larkworthy and Gillian Hayes and Subramanian Ramamoorthy },
url = {https://www.research.ed.ac.uk/en/publications/general-motion-planning-methods-for-self-reconfiguration-planning},
year = {2009},
date = {2009-08-31},
booktitle = {Towards Autonomous Robotic Systems},
abstract = {Self-reconfiguring robotic systems (SRSs) can alter their morphology autonomously. Determining a feasible plan of subcomponent moves that realize a desired shape, in general, is a hard problem for which there are no general solutions. We investigated the utility of some general motion planning methods, namely greedy search, RRT-Connect (RRT), probabilistic roadmaps (PRM) and simulated annealing (SA), as part of an investigation into generally applicable techniques for different SRS architectures. The performance of such methods is greatly dependent on heuristics. We present two new heuristics that improve performance, a greedy assignment heuristic which is a faster approximation to the classic optimal assignment heuristic, and the vector map heuristic, which transforms a configuration into a vector representation for fast nearest neighbor queries. Results of our experiments show greedy search is the fastest single shot planning algorithm for two variants of the hexagonal metamorphic system. Probabilistic roadmap planning is the fastest method overall, but initial roadmap construction is expensive. Also, we applied two existing post processing smoothing algorithms whose combination significantly improves plans produced by RRT, SA and PRM.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Motion synthesis on learned skill manifolds Presentation
Ioannis Havoutis, Subramanian Ramamoorthy
20.07.2009.
@misc{Havoutis2009c,
title = {Motion synthesis on learned skill manifolds},
author = {Ioannis Havoutis and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2009/rlssPoster.pdf},
year = {2009},
date = {2009-07-20},
booktitle = {Poster, Robot Learning Summer School (RLSS)},
abstract = {Humanoid robots are extremely flexible and
complex platforms. We want them to be able to
exhibit a variety of dynamical behaviours subject
to:
• Task constraints
(Feasibility)
• Large disturbances
(Reactive planning)
For this we need a flexible motion representation
that would allow us to handle the complexity of
the environment and the inherent complexity of
the system.},
keywords = {},
pubstate = {published},
tppubtype = {presentation}
}
complex platforms. We want them to be able to
exhibit a variety of dynamical behaviours subject
to:
• Task constraints
(Feasibility)
• Large disturbances
(Reactive planning)
For this we need a flexible motion representation
that would allow us to handle the complexity of
the environment and the inherent complexity of
the system.
Multi-strategy trading utilizing market regimes Proceedings Article
Hynek Mlnařík, Subramanian Ramamoorthy, Rahul Savani
In: Advances in Machine Learning for Computational Finance Workshop, London, 2009, (Slightly modified presentation from the Stats in the Château workshop, whose proceedings are available as P. Alquier, E. Gautier, G. Stoltz (Eds.), Inverse Problems and High-Dimensional Estimation, Lecture Notes in Statistics Vol. 203, Springer 2011]).
@inproceedings{Mlnařík2009,
title = {Multi-strategy trading utilizing market regimes},
author = {Hynek Mlnařík and Subramanian Ramamoorthy and Rahul Savani},
url = {https://videolectures.net/videos/amlcf09_ramamoorthy_mstumr
https://rad.inf.ed.ac.uk/data/publications/2009/AMLCFSlides.pdf},
year = {2009},
date = {2009-07-20},
urldate = {2009-07-20},
booktitle = {Advances in Machine Learning for Computational Finance Workshop, London},
note = {Slightly modified presentation from the Stats in the Château workshop, whose proceedings are available as P. Alquier, E. Gautier, G. Stoltz (Eds.), Inverse Problems and High-Dimensional Estimation, Lecture Notes in Statistics Vol. 203, Springer 2011]},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Motion synthesis through randomized exploration on submanifolds in configuration space Proceedings Article
Ioannis Havoutis, Subramanian Ramamoorthy
In: Lecture Notes in Artificial Intelligence, pp. 92-103, 2009.
@inproceedings{Havoutis2010c,
title = {Motion synthesis through randomized exploration on submanifolds in configuration space},
author = {Ioannis Havoutis and Subramanian Ramamoorthy },
url = {https://link.springer.com/chapter/10.1007/978-3-642-11876-0_9},
year = {2009},
date = {2009-06-29},
urldate = {2010-06-29},
booktitle = { Lecture Notes in Artificial Intelligence},
volume = { 5949},
pages = {92-103},
abstract = {Motion synthesis for humanoid robot behaviours is made difficult by the combination of task space, joint space and kinodynamic constraints that define realisability. Solving these problems by general purpose methods such as sampling based motion planning has involved significant computational complexity, and has also required specialised heuristics to handle constraints. In this paper we propose an approach to incorporate specifications and constraints as a bias in the exploration process of such planning algorithms. We present a general approach to solving this problem wherein a subspace, of the configuration space and consisting of poses involved in a specific task, is identified in the form of a nonlinear manifold, which is in turn used to focus the exploration of a sampling based motion planning algorithm. This allows us to solve the motion planning problem so that we synthesize previously unseen paths for novel goals in a way that is strongly biased by known good or feasible paths, e.g., from human demonstration. We demonstrate this result with a simulated humanoid robot performing a number of bipedal tasks.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Geodesic trajectory generation on learnt skill manifolds Proceedings Article
Ioannis Havoutis, Subramanian Ramamoorthy
In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2009.
@inproceedings{Havoutis2009,
title = {Geodesic trajectory generation on learnt skill manifolds},
author = {Ioannis Havoutis and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2009/HR_HumanoidsWkshp09.pdf
https://ieeexplore.ieee.org/abstract/document/5509819
},
year = {2009},
date = {2009-05-03},
booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
abstract = {Humanoid robots are appealing due to their inherent dexterity. However, these potential benefits may only be realized if the corresponding motion synthesis procedure is suitably flexible. This paper presents a flexible trajectory generation algorithm that utilizes a geometric representation of humanoid skills (e.g., walking) - in the form of skill manifolds. These manifolds are learnt from demonstration data that may be obtained from off-line optimization algorithms (or a human expert).We demonstrate that this model may be used to produce approximately optimal motion plans as geodesics over the manifold and that this allows us to effectively generalize from a limited training set. We demonstrate the effectiveness of our approach on a simulated 3-link planar arm, and then the more challenging example of a physical 19-DoF humanoid robot. We show that our algorithm produces a close approximation of the much more computationally intensive optimization procedure used to generate the data. This allows us to present experimental results for fast motion planning on a realistic - variable step length, width and height - walking task on a humanoid robot.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
A differential geometric approach to discrete-coefficient filter design Proceedings Article
Subramanian Ramamoorthy, Lothar Wenzel, James Nagle, Bin Wang, Michael Cerna
In: IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pp. 3197-3200, 2009.
@inproceedings{Ramamoorthy2009,
title = { A differential geometric approach to discrete-coefficient filter design},
author = {Subramanian Ramamoorthy and Lothar Wenzel and James Nagle and Bin Wang and Michael Cerna},
url = {https://www.computer.org/csdl/proceedings-article/icassp/2009/04960304/12OmNBziBe4},
year = {2009},
date = {2009-04-19},
booktitle = {IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages = {3197-3200},
abstract = {This paper is concerned with the problem of computing a discrete-coefficient approximation to a digital filter. In contrast to earlier works that have approached this problem using standard combinatorial optimization tools, we take a geometric approach. We define a Riemannian manifold, arising from the difference in frequency response between the two systems of interest, on which we design efficient algorithms for sampling and approximation. This additional structure enables us to tame the computational complexity of the native combinatorial optimization problem. We illustrate the benefits of this approach with design examples involving IIR and FIR filters.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
2008
Towards Autonomous Robotic Systems (TAROS 2008) Proceedings Article
S. Ramamoorthy, G.M. Hayes (Ed.)
In: S. Ramamoorthy, G.M. Hayes (Ed.): 2008, ISBN: 978 1 906849 00 9.
@inproceedings{Ramamoorthy2009b,
title = {Towards Autonomous Robotic Systems (TAROS 2008)},
editor = {S. Ramamoorthy and G.M. Hayes},
isbn = {978 1 906849 00 9},
year = {2008},
date = {2008-09-01},
urldate = {2009-09-01},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
A rapid prototyping tool for embedded, real time hierarchical control systems Proceedings Article
Ram Rajagopal, Subramanian Ramamoorthy, Lothar Wenzel, Hugo Andrade
In: EURASIP Journal on Embedded Systems, 2008.
@inproceedings{Rajagopal2008,
title = { A rapid prototyping tool for embedded, real time hierarchical control systems},
author = {Ram Rajagopal and Subramanian Ramamoorthy and Lothar Wenzel and Hugo Andrade},
url = {https://www.research.ed.ac.uk/en/publications/a-rapid-prototyping-tool-for-embedded-real-time-hierarchical-cont},
year = {2008},
date = {2008-07-27},
booktitle = {EURASIP Journal on Embedded Systems},
number = {14},
abstract = {Laboratory Virtual Instrumentation and Engineering Workbench (LabVIEW) is a graphical programming tool based on the dataflow language G. Recently, runtime support for a hard real-time environment has become available for LabVIEW, which makes it an option for embedded systems prototyping. Due to its characteristics, the environment presents itself as an ideal tool for both the design and implementation of embedded software. In this paper, we study the design and implementation of embedded software by using G as the specification language and the LabVIEW RT real-time platform. One of the main advantages of this approach is that the environment leads itself to a very smooth transition from design to implementation, allowing for powerful cosimulation strategies (e.g., hardware in the loop, runtime modeling). We characterize the semantics and formal model of computation of G. We compare it to other models of computation and develop design rules and algorithms to propose sound embedded design in the language. We investigate the specification and mapping of hierarchical control systems in LabVIEW and G. Finally, we describe the development of a state-of-the-art embedded motion control system using LabVIEW as the specification, simulation and implementation tool, using the proposed design principles. The solution is state-of-the-art in terms of flexibility and control performance.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Efficient, incremental coverage of space with a continuous curve. Proceedings Article
Subramanian Ramamoorthy, Ram Rajagopal, Lothar Wenzel
In: Robotica (Special Issue on Geometry in Robotics), pp. 503 - 512, 2008.
@inproceedings{Ramamoorthy2008b,
title = {Efficient, incremental coverage of space with a continuous curve.},
author = {Subramanian Ramamoorthy and Ram Rajagopal and Lothar Wenzel },
url = {https://www.cambridge.org/core/journals/robotica/article/efficient-incremental-coverage-of-space-with-a-continuous-curve/264CA34CC25B9C0EA47B5E5E8FB53906},
year = {2008},
date = {2008-07-01},
booktitle = {Robotica (Special Issue on Geometry in Robotics)},
volume = {26},
pages = { 503 - 512},
abstract = {This paper is concerned with algorithmic techniques for the incremental generation of continuous curves that can efficiently cover an abstract surface. We introduce the notion of low-discrepancy curves as an extension of the notion of low-discrepancy sequences—such that sufficiently smooth curves with low-discrepancy properties can be defined and generated. We then devise a procedure for lifting these curves, that efficiently cover the unit cube, to abstract surfaces, such as nonlinear manifolds. We present algorithms that yield suitable fair mappings between the unit cube and the abstract surface. We demonstrate the application of these ideas using some concrete examples of interest in robotics.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Trajectory generation for dynamic bipedal walking through qualitative model based manifold learning. Best Paper Proceedings Article
Subramanian Ramamoorthy, Benjamin J. Kuipers
In: IEEE International Conference on Robotics and Automation (ICRA), pp. 359-366, 2008.
@inproceedings{Ramamoorthy2008c,
title = {Trajectory generation for dynamic bipedal walking through qualitative model based manifold learning.},
author = {Subramanian Ramamoorthy and Benjamin J. Kuipers},
url = {https://ieeexplore.ieee.org/document/4543234},
year = {2008},
date = {2008-05-19},
urldate = {2008-05-19},
booktitle = { IEEE International Conference on Robotics and Automation (ICRA)},
pages = {359-366},
abstract = {Legged robots represent great promise for transport in unstructured environments. However, it has been difficult to devise motion planning strategies that achieve a combination of energy efficiency, safety and flexibility comparable to legged animals. In this paper, we address this issue by presenting a trajectory generation strategy for dynamic bipedal walking robots using a factored approach to motion planning - combining a low-dimensional plan (based on intermittently actuated passive walking in a compass-gait biped) with a manifold learning algorithm that solves the problem of embedding this plan in the high-dimensional phase space of the robot. This allows us to achieve task level control (over step length) in an energy efficient way - starting with only a coarse qualitative model of the system dynamics and performing a data-driven approximation of the dynamics in order to synthesize families of dynamically realizable trajectories. We demonstrate the utility of this approach with simulation results for a multi-link legged robot.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
System and method for programmatically generating a second graphical program based on a first graphical program Patent
S. Ramamoorthy, L. Wenzel, G. O. Morrow, M. L. Santori, J. C. Limroth, R. Kudukoli, R. E. Dye
7340684, 2008.
@patent{Ramamoorthy2008,
title = {System and method for programmatically generating a second graphical program based on a first graphical program},
author = {S. Ramamoorthy and L. Wenzel and G. O. Morrow and M. L. Santori and J. C. Limroth and R. Kudukoli and R. E. Dye},
year = {2008},
date = {2008-03-04},
number = {7340684},
keywords = {},
pubstate = {published},
tppubtype = {patent}
}
Geometric pattern matching using dynamic feature combinations Patent
D. Nair, M. S. Fisher, S. V. Kumar, B. Smyth, S. Ramamoorthy
7340089, 2008.
@patent{Nair2008,
title = {Geometric pattern matching using dynamic feature combinations},
author = {D. Nair and M. S. Fisher and S. V. Kumar and B. Smyth and S. Ramamoorthy},
year = {2008},
date = {2008-03-04},
number = {7340089},
keywords = {},
pubstate = {published},
tppubtype = {patent}
}
2007
Task encoding, motion planning and intelligent control using qualitative models PhD Thesis
S. Ramamoorthy
The University of Texas at Austin, 2007.
@phdthesis{Ramamoorthy2007,
title = {Task encoding, motion planning and intelligent control using qualitative models},
author = {S. Ramamoorthy },
url = {https://repositories.lib.utexas.edu/items/77abae22-87c3-46cc-a47b-7846977c9edf
https://rad.inf.ed.ac.uk/data/publications/2007/UT-AI-TR-07-342.pdf},
year = {2007},
date = {2007-01-01},
school = {The University of Texas at Austin},
abstract = {This dissertation addresses the problem of trajectory generation for dynamical robots operating in unstructured environments in the absence of detailed models of the dynamics of the environment or of the robot itself. We factor this problem into the subproblem of task variation, and the subproblem of imprecision in models of dynamics.},
keywords = {},
pubstate = {published},
tppubtype = {phdthesis}
}
2006
Parametrization and computations in shape spaces with area and boundary invariants Proceedings Article
Benjamin J. Kuipers, Subramanian Ramamoorthy, L. Wenzel
In: 16th Fall Workshop on Computational and Combinatorial Geometry, pp. 1-3, 2006.
@inproceedings{Kuipers2006,
title = {Parametrization and computations in shape spaces with area and boundary invariants},
author = {Benjamin J. Kuipers and Subramanian Ramamoorthy and L. Wenzel },
url = {https://rad.inf.ed.ac.uk/data/publications/2006_/FwCG.pdf
https://www.research.ed.ac.uk/en/publications/parametrization-and-computations-in-shape-spaces-with-area-and-bo},
year = {2006},
date = {2006-11-10},
booktitle = {16th Fall Workshop on Computational and Combinatorial Geometry},
pages = {1-3},
abstract = {Shape spaces play an important role in several applications in robotics, most notably by providing a manifold structure on which to perform motion planning, control, behavior discovery and related algorithmic operations. Many classical approaches to defining shape spaces are not well suited to the needs of robotics. In this abstract, we outline an approach to defining shape spaces that address the needs of such problems, which often involve constraints on area/volume, perimeter/boundary, etc. Using the simple example of the space of constant-area and constant-perimeter triangles, which are represented as Riemannian manifolds, we demonstrate efficient solutions to problems involving continuous shape evolution, optimal sampling, etc.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Qualitative hybrid control of dynamic bipedal walking Proceedings Article
S. Ramamoorthy, B. Kuipers
In: Robotics : Science and Systems II, pp. 89-96, 2006.
@inproceedings{Ramamoorthy2006b,
title = {Qualitative hybrid control of dynamic bipedal walking},
author = {S. Ramamoorthy and B. Kuipers},
url = {https://www.roboticsproceedings.org/rss02/p12.html
https://rad.inf.ed.ac.uk/data/publications/2007/p12.pdf},
year = {2006},
date = {2006-08-01},
booktitle = {Robotics : Science and Systems II},
number = {8},
pages = {89-96},
abstract = {We present a qualitative approach to the dynamical control of bipedal walking that allows us to combine the benefits of passive dynamic walkers with the ability to walk on uneven terrain. We demonstrate an online control strategy, synthesizing a stable walking gait along a sequence of irregularly spaced stepping stones. The passive dynamic walking paradigm has begun to establish itself as a useful approach to gait synthesis. Recently, researchers have begun to explore the problem of actuating these passive walkers, to extend their domain of applicability. The problem of applying this approach to applications involving uneven terrain remains unsolved and forms the focus of this paper. We demonstrate that through the use of qualitative descriptions of the task, the use of the nonlinear dynamics of the robot mechanism and a multiple model control strategy, it is possible to design gaits that can safely operate under realistic terrain conditions.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Low-discrepancy curves and efficient coverage of space Proceedings Article
Subramanian Ramamoorthy, Ram Rajagopal, Qing Ruan, Lothar Wenzel
In: Algorithmic Foundations of Robotics VII, pp. 203–218, 2006.
@inproceedings{Ramamoorthy2006c,
title = {Low-discrepancy curves and efficient coverage of space},
author = {Subramanian Ramamoorthy and Ram Rajagopal and Qing Ruan and Lothar Wenzel },
url = {https://www.researchgate.net/publication/220946745_Low-Discrepancy_Curves_and_Efficient_Coverage_of_Space
https://rad.inf.ed.ac.uk/data/publications/2007/p42.pdf},
year = {2006},
date = {2006-07-16},
booktitle = {Algorithmic Foundations of Robotics VII},
pages = {203–218},
abstract = {We introduce the notion of low-discrepancy curves and use it to solve the problem of optimally covering space. In doing so, we extend the notion of low-discrepancy sequences in such a way that sufficiently smooth curves with low discrepancy properties can be defined and generated. Based on a class of curves that cover the unit square in an efficient way, we define induced low discrepancy curves in Riemannian spaces. This allows us to efficiently cover an arbitrarily chosen abstract surface that admits a diffeomorphism to the unit square. We demonstrate the application of these ideas by presenting concrete examples of low-discrepancy curves on some surfaces that are of interest in robotics.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Designing safe, profitable automated stock trading agents using evolutionary algorithms Proceedings Article
Harish Subramanian, Subramanian Ramamoorthy, Peter Stone, Benjamin J. Kuipers
In: 8th Annual Conference on Genetic and Evolutionary Computation, pp. 1777 - 1784, 2006.
@inproceedings{Subramanian2006,
title = {Designing safe, profitable automated stock trading agents using evolutionary algorithms},
author = {Harish Subramanian and Subramanian Ramamoorthy and Peter Stone and Benjamin J. Kuipers},
url = {https://rad.inf.ed.ac.uk/data/publications/2006_/GECCO06-trading.pdf
https://www.cis.upenn.edu/%7Emkearns/projects/plat.html
https://dl.acm.org/doi/10.1145/1143997.1144285
},
year = {2006},
date = {2006-07-08},
booktitle = {8th Annual Conference on Genetic and Evolutionary Computation},
pages = {1777 - 1784},
abstract = {Trading rules are widely used by practitioners as an effective means to mechanize aspects of their reasoning about stock price trends. However, due to the simplicity of these rules, each rule is susceptible to poor behavior in specific types of adverse market conditions. Naive combinations of such rules are not very effective in mitigating the weaknesses of component rules. We demonstrate that sophisticated approaches to combining these trading rules enable us to overcome these problems and gainfully utilize them in autonomous agents. We achieve this combination through the use of genetic algorithms and genetic programs. Further, we show that it is possible to use qualitative characterizations of stochastic dynamics to improve the performance of these agents by delineating safe, or feasible, regions. We present the results of experiments conducted within the Penn-Lehman Automated Trading project. In this way we are able to demonstrate that autonomous agents can achieve consistent profitability in a variety of market conditions, in ways that are human competitive.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
System and method for programmatically generating a second graphical program based on a first graphical program Patent
L. Wenzel, S. Ramamoorthy, G. O. Morrow, M. L. Santori, J. C. Limroth, R. Kudukoli, R. E. Dye
7043693, 2006.
@patent{Wenzel2006,
title = {System and method for programmatically generating a second graphical program based on a first graphical program},
author = {L. Wenzel and S. Ramamoorthy and G. O. Morrow and M. L. Santori and J. C. Limroth and R. Kudukoli and R. E. Dye},
year = {2006},
date = {2006-05-09},
urldate = {2006-05-09},
number = {7043693},
keywords = {},
pubstate = {published},
tppubtype = {patent}
}
Dynamic bipedal walking on irregular terrain: An online adaptive algorithm Proceedings Article
Subramanian Ramamoorthy, Benjamin J. Kuipers
In: Dynamic Walking Workshop: Mechanics and Control of Human and Robot Locomotion, 2006.
@inproceedings{Ramamoorthy2006d,
title = {Dynamic bipedal walking on irregular terrain: An online adaptive algorithm},
author = {Subramanian Ramamoorthy and Benjamin J. Kuipers },
url = {https://rad.inf.ed.ac.uk/data/publications/2006_/10.1.1.61.7281.pdf},
year = {2006},
date = {2006-05-06},
booktitle = {Dynamic Walking Workshop: Mechanics and Control of Human and Robot Locomotion},
abstract = {We present a qualitative approach to the dynamical control of bipedal walking that allows us to combine the benefits of passive dynamic walkers with the ability to walk on uneven terrain. We demonstrate an online control strategy, synthesizing a stable walking gait along a sequence of irregularly spaced stepping-stones. Researchers have recently begun to explore the problem of actuating passive walkers, in order to extend their domain of applicability. In realistic applications, actuation is required for stable walking in level, uphill, or irregular environments, and active planning is essential to allow the robot to react to environmental uncertainty. The algorithmic challenge is to gain the benefits of actuation and active planning without compromising the use of natural dynamics. Our approach to solving this problem uses qualitative descriptions of the dynamics of the system, and a hybrid control framework for composing the walking behavior from simple component behaviors.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
Automatic tuning of motion controllers using search techniques Patent
S. Ramamoorthy, J. S. Falcon
7035694, 2006.
@patent{Ramamoorthy2006,
title = {Automatic tuning of motion controllers using search techniques},
author = {S. Ramamoorthy and J. S. Falcon},
year = {2006},
date = {2006-04-25},
number = {7035694},
keywords = {},
pubstate = {published},
tppubtype = {patent}
}
2005
Safe strategies for autonomous financial trading agents: A qualitative multiple-model approach Workshop
S. Ramamoorthy, H.K. Subramanian, P. Stone, B.J. Kuipers
Neural Information Processing Systems, 2005.
@workshop{Ramamoorthy2005,
title = {Safe strategies for autonomous financial trading agents: A qualitative multiple-model approach},
author = {S. Ramamoorthy and H.K. Subramanian and P. Stone and B.J. Kuipers},
url = {https://www.researchgate.net/profile/Subramanian-Ramamoorthy/publication/228937502_Safe_Strategies_for_Autonomous_Financial_Trading_Agents_A_Qualitative_Multiple-Model_Approach/links/0fcfd5062fe8beb2aa000000/Safe-Strategies-for-Autonomous-Financial-Trading-Agents-A-Qualitative-Multiple-Model-Approach.pdf},
year = {2005},
date = {2005-12-09},
booktitle = {Neural Information Processing Systems},
abstract = {We present a principled approach to the design of safe strategies for autonomous trading agents. Our design is based on a qualitative characterization of the stochastic dynamics of some simple trading rules. Using a canonical model for price processes, we first determine the market conditions under which each trading rule can be profitable. Then, using this information, we compose trading rules with a decision rule based on reasoning about the evolution of the agent’s position in a particular state space. These composite trading rules result in significant improvements in profitability. This approach to qualitative characterization of dynamics may be combined with machine learning techniques to define more sophisticated composite trading rules, combining the benefits of improved profitability, ie, safety, with robustness resulting from learning. These claim are validated by empirical experiments conducted as part of the Penn-Lehman Automated Trading Project.},
keywords = {},
pubstate = {published},
tppubtype = {workshop}
}
2004
Controller synthesis using qualitative models and constraints Proceedings Article
Subramanian Ramamoorthy, Benjamin Kuipers
In: 18th International Workshop on Qualitative Reasoning, pp. 41-50, 2004.
@inproceedings{Ramamoorthy2004,
title = { Controller synthesis using qualitative models and constraints},
author = {Subramanian Ramamoorthy and Benjamin Kuipers},
url = {https://rad.inf.ed.ac.uk/data/publications/2006_/Ramamoorthy-qr-04.pdf
https://www.researchgate.net/publication/237447812_Controller_Synthesis_using_Qualitative_Models_and_Constraints},
year = {2004},
date = {2004-01-01},
booktitle = {18th International Workshop on Qualitative Reasoning},
pages = { 41-50},
abstract = {Many engineering systems require the synthesis of global behaviors in nonlinear dynamical systems. Multiple model approaches to control design make it possible to synthesize robust and optimal versions of such global behaviors. We propose a methodology called Qualitative Heterogeneous Control that enables this type of control design. This methodology is based on a separation of concerns between qualitative correctness and quantitative optimization. Qualitative sufficient conditions are derived, that define a space of quantitative control strategies. These sufficient conditions are used in conjunction with a numerical optimization procedure to synthesize nonlinear optimal controllers that are robust in practical implementations. We demonstrate this process of controller synthesis for the global control of an inverted pendulum system.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
2003
Qualitative heterogeneous control of higher order systems Proceedings Article
Subramanian Ramamoorthy, Benjamin Kuipers
In: Hybrid Systems: Computation and Control, pp. 417–434, 2003.
@inproceedings{Ramamoorthy2003,
title = {Qualitative heterogeneous control of higher order systems},
author = {Subramanian Ramamoorthy and Benjamin Kuipers },
url = {https://link.springer.com/chapter/10.1007/3-540-36580-X_31
https://rad.inf.ed.ac.uk/data/publications/2006_/Ramamoorthy-hscc-03.pdf
https://www.youtube.com/watch?v=OANAQPFGf38
https://www.youtube.com/watch?v=dJOyf7iyDKs},
year = {2003},
date = {2003-01-01},
urldate = {2003-01-01},
booktitle = {Hybrid Systems: Computation and Control},
volume = {2623},
pages = {417–434},
abstract = {This paper presents the qualitative heterogeneous control framework, a methodology for the design of a controlled hybrid system based on attractors and transitions between them. This framework designs a robust controller that can accommodate bounded amounts of parametric and structural uncertainty. This framework provides a number of advantages over other similar techniques. The local models used in the design process are qualitative, allowing the use of partial knowledge about system structure, and nonlinear, allowing regions and transitions to be defined in terms of dynamical attractors. In addition, we define boundaries between local models in a natural manner, appealing to intrinsic properties of the system. We demonstrate the use of this framework by designing a novel control algorithm for the cart-pole system. In addition, we illustrate how traditional algorithms, such as linear quadratic regulators, can be incorporated within this framework. The design is validated by experiments with a physical system.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}
2002
Qualitative modeling and heterogeneous control of global system behavior Proceedings Article
Benjamin Kuipers, Subramanian Ramamoorthy
In: Hybrid Systems: Computation and Control, Lecture Notes in Computer Science, pp. 294–307, 2002.
@inproceedings{Kuipers2002,
title = {Qualitative modeling and heterogeneous control of global system behavior},
author = {Benjamin Kuipers and Subramanian Ramamoorthy },
url = {https://rad.inf.ed.ac.uk/data/publications/2006_/Kuipers-hscc-02.pdf
https://link.springer.com/chapter/10.1007/3-540-45873-5_24
},
year = {2002},
date = {2002-01-01},
booktitle = {Hybrid Systems: Computation and Control, Lecture Notes in Computer Science},
volume = {2289},
pages = {294–307},
abstract = {Multiple model approaches to the control of complex dynamical systems are attractive because the local models can be simple and intuitive, and global behavior can be analyzed in terms of transitions among local operating regions. In this paper, we argue that the use of qualitative models further improves the strengths of the multiple model approach by allowing each local model to describe a large class of useful non-linear dynamical systems. In addition, reasoning with qualitative models naturally identifies weak sufficient conditions adequate to prove qualitative properties such as stability. We demonstrate our approach by building a global controller for the free pendulum. We specify and validate local controllers by matching their structures to simple generic qualitative models. This process identifies qualitative constraints on the controller designs, sufficient to guarantee the desired local properties and to determine the possible transitions between local regions. This, in turn, allows the continuous phase portrait to be abstracted to a simple transition graph. The degrees of freedom in the design that are unconstrained by the qualitative description remain available for optimization by the designer for any other purpose.},
keywords = {},
pubstate = {published},
tppubtype = {inproceedings}
}